一种非数据类型对象的引用持久化及其恢复的方法与流程
本发明属于互联网,涉及数据序列化与反序列化,具体是一种复杂条件下的实例构造技术与非数据类型对象数据之间保持同一引用的解决方案。
背景技术:
1、在当前的语言开发中,对无状态的数据已经存在诸多非常成熟的解决方案,如json(javascript object notation,js对象简谱)、protobuf(protocol buffers)、xml(extensible markup language,可扩展标记语言)等。
2、json是一种轻量级的数据交换格式。它基于ecmascript(european computermanufacturers association,欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。json化数据是将内存中的数据对象编码为对应的字节形式,并可以在需要时进行反序列化使用。json采用了无状态的数据序列化方法,只有7种数据类型:数字,字符串,对象,数组,null,true,false。该方式可以方便的在各种语言之间进行通信传递。
3、protobuf是谷歌开发的一款无关平台,无关语言,可扩展,轻量级高效的序列化结构的数据格式,用于将自定义数据结构序列化成字节流,和将字节流反序列化为数据结构。适合做数据存储和为不同语言、不同应用之间互相通信的数据交换格式,只要实现相同的协议格式,即后缀为proto文件被编译成不同的语言版本,加入各自的项目中,这样不同的语言可以解析其它语言通过protobuf序列化的数据。protobuf为了进一步减小序列化后的数据大小,进行了额外的元数据提取,以及特殊的内容编码。
4、json化数据在当前已经能处理大部分的情况,但在指定场景下,还有部分问题需要解决。如:(1)不能处理对象关系:数据本身具有无状态的特征,所有的内存对象都被作为数据处理,因此对象恢复的时候要求对象值相等,而不强制要求对象值为同一个。在对象关系复杂的场景中,两个对象的相互引用会引发错误,无法成功进行序列化,因为同一引用和数值相等最大的区别在于,如果引用是用一个数据对象,当修改该数据时,会影响到所有引用该数据的其他地方;如果是值对象,一般是不可更改的,并且改动也仅仅引用当前使用点,这一现象,会在序列化和反序列化后发生。(2)有限制的反序列化规范:在常规json框架下,对数据的写法以及反序列化时的函数成员有一定的要求,在部分的情况下需要提供特定的构造函数。(3)数据内容比较大:json本身产生的数据中,需要记录大量的“键-值对”,这也使得大部分情况下,json序列化的字节内容并不小。protobuf在json的数据基础上做出了一些针对性改进,其提取了数据的键以减少数据量,一定程度上解决了数据内容较大的问题,但其它问题仍然存在。
技术实现思路
1、为了解决现有技术的不足,本发明提出一种非数据类型对象的引用持久化及其恢复的方法,在处理非数据类型对象数据的对象关系上,能够在固定作用域下,解决数据引用的恢复与持久化问题,保证恢复前后,原有数据引用保持不变。
2、本发明要解决的技术问题是通过以下技术方案实现的:
3、一种非数据类型对象的引用持久化及其恢复的方法,包括数据的序列化和反序列化两个部分:
4、数据序列化时,检测当前数据入口是否存在,其中序列化的第一个成员总是会被指定为数据入口,如果不存在则将其指定为数据入口,随后提取当前数据中的所有成员,提取需要存储的成员并识别出对应的引用类型数据:对于数据类型成员,根据其序列化程序进行数据序列化,然后输出到指定的写出器;对于引用类型成员,为其生成唯一的引用编号并与当前数据类型映射保存,随后对该引用对象递归触发重复本序列化步骤,直到所有数据处理完成,输出的数据内容总是与其唯一编号保持关联;
5、数据反序列化时,从数据中读取数据入口,读取数据入口的类型成员信息,使用该信息基于内存重建该数据实例,并将该数据实例根据其引用编号保存至当前上下文,此时,该数据是一个无效的数据,需要接下来进行两种数据的装填:对于值类型数据,直接反序列化即可;对于在序列化过程中被标记为引用类型数据的,需要检测该数据是够已经处于反序列化过程,只要上下文中存在该数据类型即被认定,如果存在反序列化过程,则直接从上下文中获取并设置,否则,递归从内存中构造一个实例并重复上述步骤。
6、在本发明中,在数据序列化和反序列化的过程中,如果出现堆栈读取过大的情况,改变程序参数调大堆栈,或者将递归式的引用类型序列化改为循环式,可以使用大的堆内存进行处理。
7、在本发明中,在数据序列化和反序列化的过程中,序列化产生的数据应跟引用编号关联起来,以便在需要处理数据时进行快速查询;如果数据之间的关系是处于统一等级,需要遍历反序列化数据直至读取完成并返回。一般情况下,数据入口应该只有一个对象,如果是多个数据,使用数组处理也可以完成。
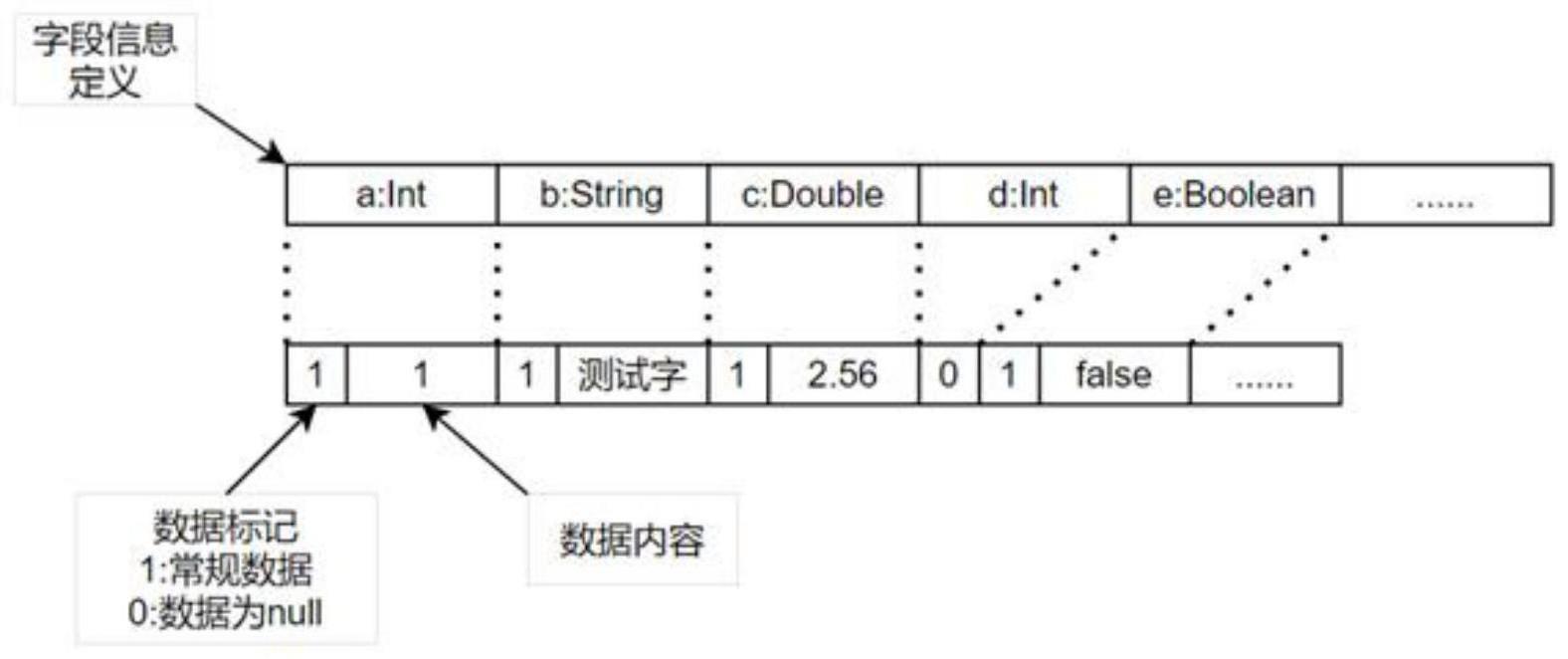
8、在本发明中,在数据序列化的过程中,数据的字段信息和其内容数据文件分开存储,字端信息中只需要包含:字段名称、字段类型,该字段信息主要用于与实际类型之间做校验使用,称之为数据元信息;数据文件是保存后按照头文件中字段顺序排列的数据值,因此数据文件与数据元信息文件应配合读取。
9、进一步的,在数据的存储过程中,使用特定的数据标记来存储数据的一些额外信息,如数据为null的标志等。
10、与现有技术相比,本发明具有以下优点:
11、(1)本发明进行的数据处理,可以无视任何引用进行序列化并在序列化后进行恢复,将纵向数据进行横向数据存储,恢复时再将横向数据转换为纵向数据,恢复前后,原有数据引用保持不变;
12、(2)本发明的反序列化过程中,基于内存重建数据类型,不受数据原有实例化过程影响,因此对数据本身的写法基本无要求,可以在内存的基准上进行直接操作和关联,从而获得一定的性能提升,数据的类型还可以在后续基础上逐渐添加以提高兼容;
13、(3)本发明使用数据元信息与数据文件分离的方式进行存储,能够将大量重复的数据抽离,最大程度减少数据大小,实际数据生成大小约为json数据的1/2,与protobuf数据大小相当。
技术特征:
1.一种非数据类型对象的引用持久化及其恢复的方法,其内容包括数据的序列化和反序列化两个部分。其主要工作逻辑如下:
2.根据权利要求1所述的引用持久化及其恢复的方法,其特征在于:在数据序列化的过程中,数据的字段信息和其内容数据文件分开存储,字段信息中只需要包含:字段名称、字段类型,该字段信息主要用于与实际类型之间做校验使用,称之为数据元信息;数据文件是保存后按照头文件中字段顺序排列的数据值,因此数据文件与数据元信息文件应配合读取。
3.根据权利要求2所述的引用持久化及其恢复的方法,其特征在于:在数据的存储过程中,使用特定的数据标记来存储数据的一些额外信息。
4.根据权利要求1所述的引用持久化及其恢复的方法,其特征在于:在数据序列化和反序列化的过程中,如果出现堆栈读取过大的情况,改变程序参数调大线程堆栈,或者将递归式的引用类型序列化改为循环式,可以使用大的堆内存进行处理。
5.根据权利要求1所述的引用持久化及其恢复的方法,其特征在于:在数据序列化和反序列化的过程中,序列化产生的数据应跟引用编号关联起来,以便在需要处理数据时进行快速查询;如果数据之间的关系是处于统一等级,需要遍历反序列化数据直至读取完成并返回。
技术总结
一种非数据类型对象的引用持久化及其恢复的方法,属于互联网技术,该技术包括数据的序列化和反序列化两个部分。该方法在序列化时对数据进行标记,并分离成为数据元信息和数据进行存储;在反序列化时依次读取数据入口,并根据数据类型重建原有数据引用体系。本发明可以无视任何引用结构进行序列化并在序列化后进行恢复,且有效的减小了序列化后的数据大小。
技术研发人员:韩春林,沈兵
受保护的技术使用者:谷斗科技(上海)有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!