基于时空分离卷积和非对称卷积的视频特征提取模型的建模方法
本发明属于模式识别、机器视觉和视频处理,涉及人体行为识别和视频特征提取网络模型技术,尤其涉及一种视频特征提取网络模型方法,构建基于时空分离卷积和非对称卷积的视频特征提网络模型,有效地提升了人体行为识别效果,证明其视频特征提取质量较好。
背景技术:
1、互联网上的多媒体正在迅速增长,导致互联网上每分钟都在共享越来越多的视频。为了应对信息爆炸,理解和分析这些视频的信息是非常必要的,理解和分析视频信息的目的十分繁多,例如便于用户搜索视频、为用户推荐喜爱视频、为相同类别视频排名热度等。几十年来大量的专业人员一直致力于视频信息的分析,并解决了各种各样的问题,例如视频分类、视频理解以及视频的目标检测等。通过采用不同的具体解决方案,在这些问题上取得了相当大的进展。然而,我国越来越需要一个通用的视频特征提取方法来检测出视频描述符,以帮助人们以相同的方式解决大规模的视频信息的分析任务。
2、在视频中提取可以表征视频特征的任务被称为视频特征提取。受图像领域的深度学习突破的启发,过去几年特征学习取得了快速进展,各种预训练的卷积网络模型可用于提取图像特征。这些图像特征是通过网络模型的最后几个全连接层的激活获得,全连接层在迁移学习任务上表现良好。然而,由于缺乏运动建模,这种基于图像的深度特征并不直接适用于视频。现如今,开发有效的视频特征提取模型存在几个主要的挑战。
3、在数据集方面:首先,定义用于训练视频特征提取模型的标签空间非常困难。这是因为视频特征提取的数据集通常为剪辑的视频,要想训练模型需要对数据集中的视频进行注释,然而注释视频需要大量的时间与精力,因为需要观看所有的视频帧,同时注释视频的动作范围也很模糊,因为大多数动作很难确定其确切的开始和结束时刻。然后,一些流行的基准数据集,只发布视频链接供用户下载,而不是真正的视频,这种情况会导致虽然处理的是相同的数据集,但是会对不同的数据进行评估。所以即使使用同一个数据集,要对各种模型进行公平的比较,并得出有说服力的观点是十分困难的。
4、在建模方面:首先,数据集中的数据都是捕捉人类动作的剪辑视频,而提取视频的动作特征具有很强的类内和类间的差异。人们可以在不同的场景下以不同的速度执行相同的动作。此外,一些动作类别具有相似的运动模式,区分成功十分困难。其次,提取视频的动作特征需要同时理解短期动作特定的运动信息和长期时间信息,所以不能使用单一的卷积神经网络,而需要一个复杂的模型来处理不同的视角。最后,模型训练和检验的计算成本都很高,极大地阻碍了视频特征提取模型的开发和部署。
5、然而随着时代的发展,深度学习的热度越来越高。而在视频特征提取方面,基于深度学习的模型可以提取视频动作特征。早期有许多人尝试将卷积神经网络应用于视频特征提取,而深度三维卷积网络(c3d)就是其中之一。(tran d,bourdev l,fergus r,etal.learning spatiotemporal features with 3d convolutional networks[j].ieee,2015.)c3d网络是一种很好的特征学习方法,它可以同时模拟视频中对象的外观和运动。由于c3d网络能直接提取时空特征,并且结构由3d卷积层和3d池化以及全连接层简单堆叠而成,所以结构比较简单,广泛用于视频的人体行为识别研究和视频特征提取任务。原始的c3d模型共有8层卷积核为3×3×3卷积层,每层卷积后跟有3d池化层,最后有两个全连接层以及一个softmax分类器。虽然c3d模型在视频的人体行为识别任务和特征提取任务中取得了不错的效果,但在实际应用中仍然会出现问题,由于原始c3d模型的网络结构不深,导致精度有待提升,对特征提取的还不够充分,且参数量较大,不利于实际应用中的模型迁移。
技术实现思路
1、本发明的目的在于实现一种基于时空分离卷积和非对称卷积的视频特征提取模型的建模方法。
2、本发明提供的技术方案如下:
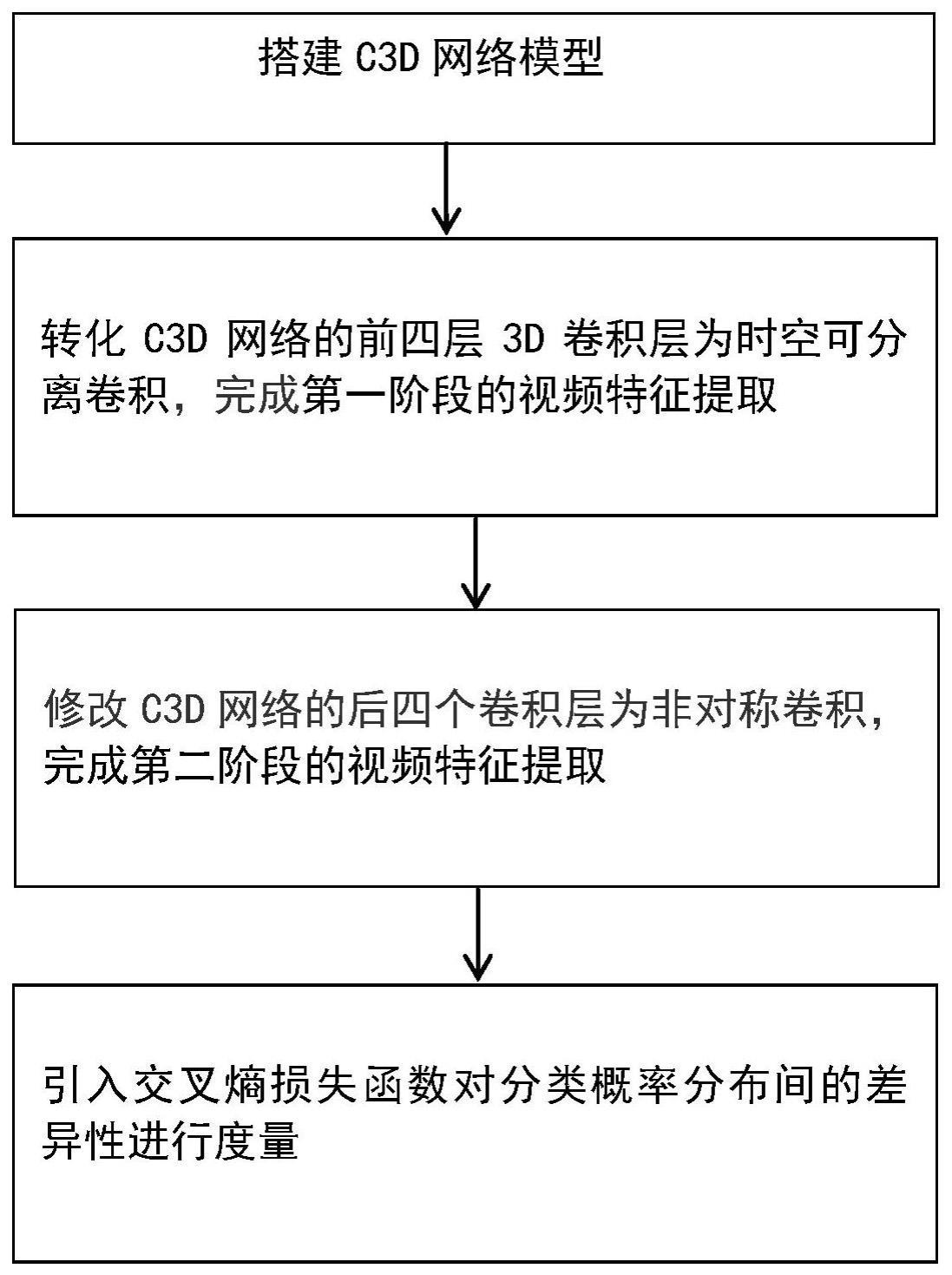
3、如附图1所示,本发明提供一种基于时空分离卷积和非对称卷积的视频特征提取模型的建模方法,其步骤包括:
4、1)搭建原始c3d网络模型,该模型包括八个卷积层conv1a、conv2a、conv3a、conv3b、conv4a、conv4b、conv5a以及conv5b,五个池化层和两个全连接层;
5、2)转化c3d网络的前四层3d卷积层为时空可分离卷积。将每一层3d卷积层分解一个2d空间卷积和一个1d时间卷积,conv1a、conv2a、conv3a以及conv3b转化后变为conv1a、conv1b、conv2a、conv2b、conv3a、conv3b、conv3c以及conv3d共八层卷积层,其中,2d空间卷积层为conv1a、conv2a、conv3a以及conv3c,1d时间卷积层为conv1b、conv2b、conv3b以及conv3d,转化后2d空间卷积层的卷积核由原来的3×3×3变为1×3×3,1d时间卷积层的卷积核由原来的3×3×3变为3×1×1,完成第一阶段的视频特征提取;
6、3)修改c3d网络的后四个卷积层conv4a、conv4b、conv5a以及conv5b为非对称卷积,其中,conv4a与conv4b的卷积核由原来的3×3×3分别转化为3×1×5与3×5×1,conv5a与conv5b的卷积核由原来的3×3×3分别转化为3×1×7与3×7×1,构成新的视频特征提取模型;
7、4)引入交叉熵损失函数对分类概率分布间的差异性进行度量,模型中的计算过程如下:
8、首先输入是size为(minibatch,c),其中,minibatch为类的批量大小,c为类别总数,输入size后损失函数按公式(1)计算:
9、
10、公式(1)中,x为各类别对应损失函数的数组,loss为类别对应损失值,j为类别个数,class为标签值,式(1)中的标签值class并不参与直接计算,而是作为一个索引,索引对象为实际类别。
11、进一步,得到损失函数后,通过公式(2)计算得到交叉熵的值,其中,p为概率分布期望输出,q为概率分布实际输出:
12、
13、由此计算得到各类别的交叉熵值,交叉熵值越小,两个概率分布就越接近,进而实现对输入的视频特征的分类任务。
14、本发明经实验表明,其优点是改进的模型在视频的特征提取方面效果更好,且对于模型参数也可以进行有效的压缩。
技术特征:
1.一种基于时空分离卷积和非对称卷积的视频特征提取模型的建模方法,其步骤包括:
2.如权利要求1所述的建模方法,其特征在于,得到损失函数后,通过公式(2)计算得到交叉熵的值,其中,p为概率分布期望输出,q为概率分布实际输出:
3.如权利要求1所述的建模方法,其特征在于,步骤2)中卷积层conv1a拥有ni个尺寸大小为ni-1×t×d×d的3d卷积核,(2+1)d卷积模块分别由mi个尺寸为ni-1×1×d×d的2d卷积核和ni个尺寸为mi×t×1×1的时间卷积核组成,其中
4.如权利要求1所述的建模方法,其特征在于,步骤3)中模型训练采用adam优化参数,并在每个卷积层后加入bn层,adam算法参数设置情况如下:
5.如权利要求1所述的建模方法,其特征在于,步骤4)中对视频数据集进行处理:
技术总结
本发明公开了一种基于时空分离卷积和非对称卷积的视频特征提取模型的建模方法,属于模式识别、机器视觉技术领域和视频处理技术领域,该方法包括:搭建C3D网络模型;将C3D网络的前四层卷积层转化为时空可分离卷积,将3D卷积明确分解为一个2D空间卷积和一个1D时间卷积的连续操作;对C3D网络的后四个卷积层进行改进以减少模型参数,将3D卷积改进为非对称卷积;构建基于时空分离卷积和非对称卷积的视频特征提取模型。本发明经实验表明,其优点是改进的模型在视频的特征提取方面效果更好,且对于模型参数也可以进行有效的压缩,具有较高的应用价值及推广价值。
技术研发人员:邢素霞,郭正,于重重,佟鑫
受保护的技术使用者:北京工商大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!