对话处理方法、预训练对话改写模型和电子设备与流程
本申请涉及人工智能,具体涉及一种对话处理方法、预训练对话改写模型和电子设备。
背景技术:
1、随着人工智能的快速发展,在智能对话技术中,通常情况下利用机器学习来输出用户想要的问答结果,在确定用户要得到的问答结果过程中,如何准确理解用户的输入信息中包含的意图是决定问答准确性的关键因素。但是,发明人发现,相关技术中智能对话系统识别用户输入信息的准确度较低,无法满足用户对识别准确性的要求。
技术实现思路
1、鉴于上述问题,本申请提供一种对话处理方法、预训练对话改写模型和电子设备,以至少解决智能对话系统识别用户输入信息准确度较低的技术问题。
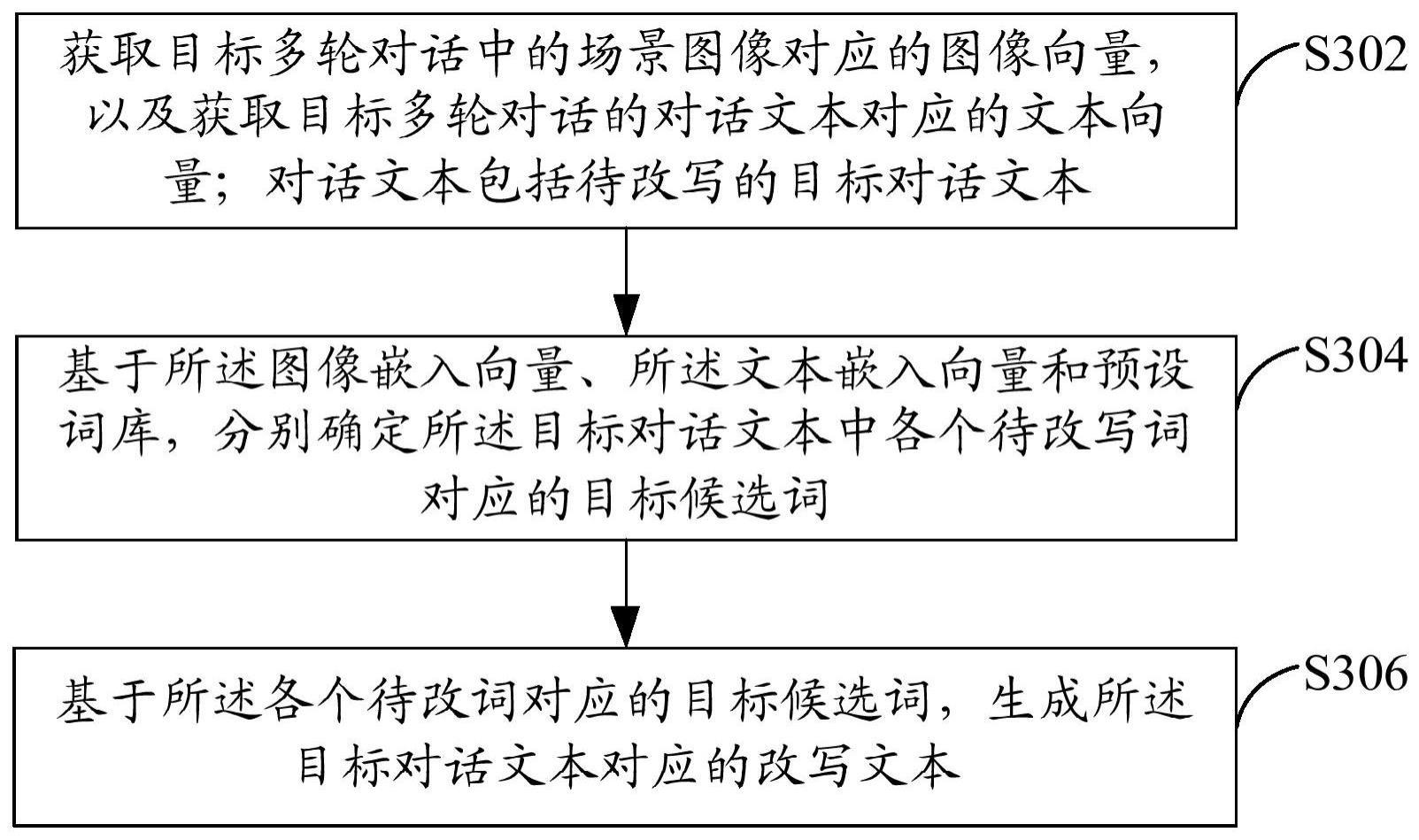
2、根据本申请实施例的第一方面,提供了一种对话处理方法,包括:获取目标多轮对话中的场景图像对应的图像嵌入向量,以及获取所述目标多轮对话的对话文本对应的文本嵌入向量;所述对话文本包括待改写的目标对话文本;基于所述图像嵌入向量、所述文本嵌入向量和预设词库,分别确定所述目标对话文本中各个待改写词对应的目标候选词;基于所述各个待改词对应的目标候选词,生成所述目标对话文本对应的改写文本。
3、根据本申请实施例的第二方面,提供了一种预训练对话改写模型的训练方法,所述预训练对话改写模型应用于第一方面所述的对话处理方法,所述训练方法包括:构建预训练对话改写模型的模型结构,所述预训练对话改写模型的解码器中包括指针网络;获取训练集,所述训练集包括含有场景图像的多轮对话样本,所述多轮对话样本中包括需改写的目标对话文本及所述目标对话文本对应的验证改写文本;基于所述多轮对话样本,训练构建的所述模型结构,得到预训练对话改写模型。
4、根据本申请实施例的第三方面,提供了一种预训练对话改写模型,包括:码器以及与所述编码器相连的解码器;
5、所述编码器,用于将目标多轮对话中的场景图像对应的图像嵌入向量映射为图像编码向量,以及将所述目标多轮对话的对话文本对应的文本嵌入向量映射为文本编码向量;其中,所述对话文本包括待改写的目标对话文本;所述解码器,用于根据预设词库、所述编码器输入的图像编码向量和文本编码向量,分别确定所述目标对话文本中各个待改写词对应的目标候选词;
6、所述解码器包括指针网络,所述指针网络用于确定从所述目标多轮对话的文本中选择待改写词对应的候选词的第二概率,以及根据第一概率和所述第二概率确定所述候选词最终的概率;其中,所述待改写词为所述目标对话文本中的任一待改写词,所述第一概率为根据所述预设词库中选择待改写词对应的候选词的概率。
7、根据本申请实施例的第四方面,还提供了一种电子设备,包括存储器和处理器,上述存储器中存储有计算机程序,上述处理器被设置为通过上述计算机程序执行上述第一方面的对话处理方法和第二方面的预训练对话改写模型的训练方法。
8、根据本申请实施例的第五方面,还提供了一种计算机可读的存储介质,该计算机可读的存储介质中存储有计算机程序,其中,该计算机程序被设置为运行时执行上述第一方面的对话处理方法和第二方面的预训练对话改写模型的训练方法。
9、在本申请实施例中,根据目标多轮对话中的场景图像对应的图像向量,以及上述目标多轮对话的对话文本对应的文本向量,并基于所述图像嵌入向量、所述文本嵌入向量和预设词库,分别从预设词库和目标多轮对话确定用于改写上述目标对话文本的目标候选词,由此能够从多个维度来精准的将目标对话文本中出现信息缺失的词汇进行补充和完善,即本申请相较于现有技术,识别用户输入信息的数据来源中,增加了图像数据,同时结合对话过程中的上下文数据、预设词库数据,从而能提高智能对话系统识别用户输入信息的准确度。
技术特征:
1.一种对话处理方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述基于所述图像嵌入向量、所述文本嵌入向量和预设词库,分别确定所述目标对话文本中每个词对应的目标候选词,包括:
3.根据权利要求2所述的方法,其特征在于,所述在当前迭代周期,将已预测词向量、所述图像编码向量和所述文本编码向量输入所述预训练对话改写模型的解码器,输出所述当前迭代周期对应的目标待改写词的至少一个候选词的概率,包括:
4.根据权利要求3所述的方法,其特征在于,所述获得第一注意力权重向量,包括:
5.根据权利要求3所述的方法,其特征在于,所述获得第二注意力权重向量,包括:
6.根据权利要求3所述的方法,其特征在于,所述将所述第一概率和第二注意力权重向量输入所述解码器的指针网络,输出所述第一候选词最终的概率,包括:
7.根据权利要求1至6任一项所述的方法,其特征在于,所述获取目标多轮对话中的场景图像对应的图像嵌入向量,以及获取所述目标多轮对话的对话文本对应的文本嵌入向量,包括:
8.一种预训练对话改写模型的训练方法,其特征在于,所述预训练对话改写模型应用于权利要求1-7任一项所述的对话处理方法,所述训练方法包括:
9.根据权利要求8所述的训练方法,其特征在于,所述基于所述多轮对话样本,训练构建的所述模型结构,得到预训练对话改写模型,包括:
10.一种预训练对话改写模型,其特征在于,包括:编码器以及与所述编码器相连的解码器;
11.一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器运行所述计算机程序以实现如权利要求1-9任一项所述的方法。
12.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述程序被处理器执行实现如权利要求1-9中任一项所述的方法。
技术总结
本申请公开了一种对话处理方法、预训练对话改写模型和电子设备。其中,该方法包括:获取目标多轮对话中的场景图像对应的图像嵌入向量,以及获取所述目标多轮对话的对话文本对应的文本嵌入向量;所述对话文本包括待改写的目标对话文本;基于所述图像嵌入向量、所述文本嵌入向量和预设词库,分别确定所述目标对话文本中各个待改写词对应的目标候选词;基于所述各个待改词对应的目标候选词,生成所述目标对话文本对应的改写文本。本申请实施例可以解决智能对话系统识别用户输入信息准确度较低的技术问题。
技术研发人员:袁一菲,施晨,王润泽,陈丽怡,姜飞俊,游源
受保护的技术使用者:浙江猫精人工智能科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!