一种基于自监督表示学习的企业单位地址匹配方法及装置与流程
本发明涉及金融企业单位地址文本序列、电商平台相关性匹配等中文自然语言处理领域,具体而言,涉及一种基于自监督表示学习的企业单位地址匹配方法及装置。
背景技术:
1、文本匹配,或者说是文本相关性匹配是自然语言处理领域的一个重要分支,通过对文本进行相关性匹配,我们可以发现用户潜在的兴趣,可以通过相关技术方法给用户提供更好的内容。在金融、电信、交通、电商、营销等领域都有重要的应用价值。例如在搜索平台或者是电商领域,我们经常会根据需要去搜索感兴趣的内容。例如,“最好吃的四川火锅”或者“杭州市西湖区的工商银行”等相关话题。由于有时搜索内容和平台提供内容不完全一致,所以我们需要对平台展示内容或者相关文本做一个相关(相似)性的判断,来给用户展示最准确的内容,提升平台和公司的用户粘性。
2、目前对于文本匹配的处理技术主要分为两大类:传统机器学习方法:首先需要进行特征工程,特征工程结束即可建立模型。其优点是训练速度快,同时也能保证一定的精度,但是特征工程量巨大;深度学习方法:深度学习模型在此领域分为两种基于交互的模型与基于表示的模型,如图1所示,基于交互模型会首先融合两个序列进行处理,经过模型隐藏层得到特征向量在输出层输出相似度。基于表示模型会对两个序列分别进行特征提取,向量表示,最终通过相似度算法计算两个向量的相似度。
3、上述介绍的文本匹配的技术都有一些缺点。传统机器学习的特征工程构建过程太复杂,需要建立文本和字符本身和交融特征,然后还需要评估有效性。深度学习的基于表示和交互的方法存在模型结构复杂,但是在特定场景的效果较差。例如,在企业单位地址这个强序列场景中,文本匹配的规则和一般的相关性场景会不同,交换地址token序列的顺序,可能会出现不相关性的情况。
4、综上所述,现有的文本匹配技术无法同时满足下面的要求:
5、1)一套通用简介的文本处理框架;
6、2)对特定场景的文本匹配有补充处理能力;
7、3)评价指标超出行业平均水平。
技术实现思路
1、针对现有的文本匹配处理方式产生的问题,本发明提出了一种基于自监督表示学习的企业单位地址匹配方法及装置,提供一种基于深度学习模型的文本匹配技术,使得可以通过制定正负训练样本和模型训练方式,对一对以及多对文本对之间进行相关或相似性匹配,在少量标注样本的情况下,学习特定场景下更具有区分度的语义表征,并且实现单位地址的精准匹配,同时在评价指标上优于近几年最先进的模型。
2、本发明的目的是通过以下技术方案来实现的:第一方面,本发明提供了一种基于自监督表示学习的企业单位地址匹配方法,该方法包括以下步骤:
3、(1)获取单位地址匹配场景下的地址,将地址数据标注成地址token序列的方式对其进行构造;
4、(2)初始化正样本集合和负样本集合,在地址token长度的范围内初始化一个整数k,遍历地址token序列,随机选取k个位置对token进行修改,得到正负地址token样本加入到对应的集合中,将所有的地址串和对应的标签拼接,得到正样本训练集和负样本训练集;
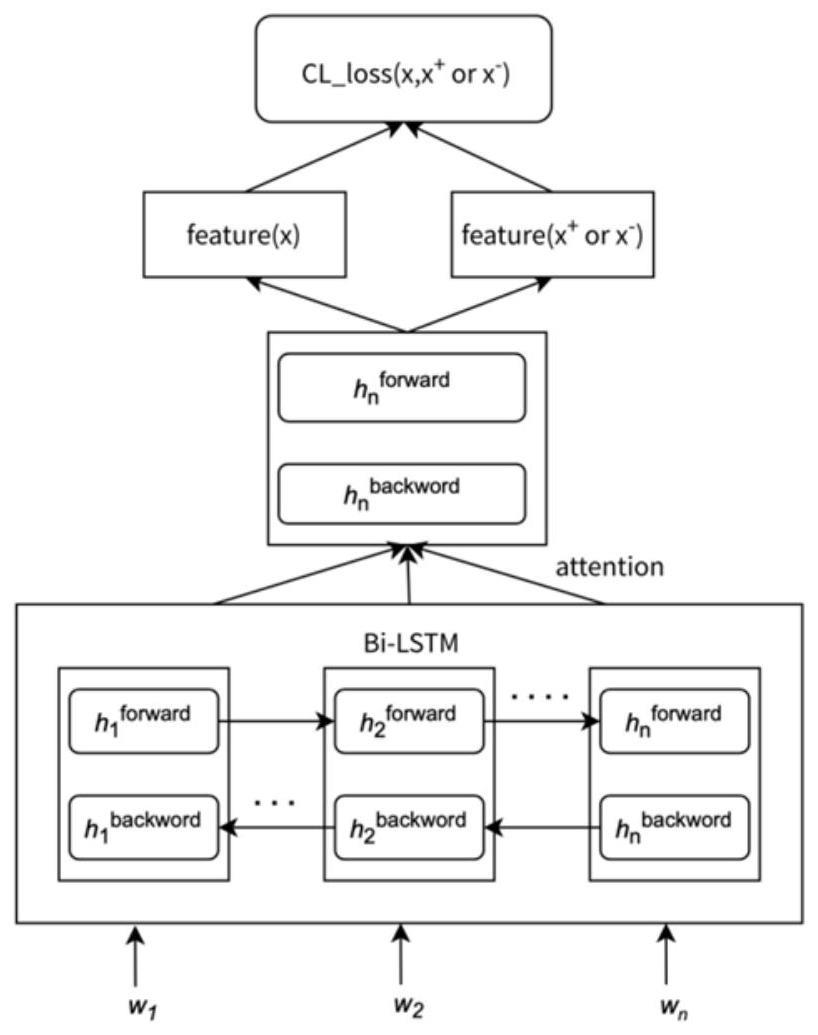
5、(3)构建文本匹配模型,该模型将输入的文本进行编码,获取到经过编码的字向量表征后,采用注意力模块用代表着句向量的最后时间步的隐向量和字向量进行注意力操作,得到最终加权的句向量。
6、(4)基于正样本训练集和负样本训练集对文本匹配模型通过有监督的学习方式进行训练;然后再通过无监督的方式对文本匹配模型进行训练,反向传播优化自监督表示学习的损失函数,得到训练后的文本匹配模型;
7、(5)基于训练好的文本匹配模型,直接将需要匹配的文本对,依次输入到文本匹配模型中获取文本的特征表达,采用相似度算法来计算文本匹配模型输出的文本特征向量的相似度,将计算出的相似度和相似度阈值比较,得到企业单位地址匹配。
8、进一步地,步骤(2)中,以一定的概率对token进行删除、替换和简写来生成正样本,然后通过对token打乱的方式来生成负样本。
9、进一步地,步骤(4)中,所述无监督的学习方式利用模型中的dropout mask,对每一个句子进行两次前向传播,得到两个不同的embeddings向量,将同一个句子得到的向量对作为正样本对,对于每一个向量,选取其他句子产生的embeddings向量作为负样本,以此来训练文本匹配模型。
10、进一步地,步骤(4)中,自监督表示学习的损失函数定义如下:
11、
12、第二方面,本发明提供了一种基于自监督表示学习的企业单位地址匹配装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,用于实现所述的基于自监督表示学习的企业单位地址匹配方法的步骤。
13、第三方面,本发明提供了一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现所述的基于自监督表示学习的企业单位地址匹配方法的步骤。
14、本发明的有益效果:
15、1.本发明所提出的一种基于自监督表示学习的企业单位地址匹配方法,能实现单位地址的精准匹配;
16、2.本发明所提出的基于自监督表示学习对单位地址的匹配和通过无监督和有监督结合的方式,能够在少量标注样本的情况下学习到特定场景中更具有区分度的语义表征;
17、3.本发明实施例提供的基于自监督表示学习的企业单位地址匹配装置和计算机可读存储介质,能够在执行时实现基于自监督表示学习的企业单位地址匹配方法的步骤。
技术特征:
1.一种基于自监督表示学习的企业单位地址匹配方法,其特征在于,该方法包括以下步骤:
2.根据权利要求1所述的一种基于自监督表示学习的企业单位地址匹配方法,其特征在于,步骤(2)中,以一定的概率对token进行删除、替换和简写来生成正样本,然后通过对token打乱的方式来生成负样本。
3.根据权利要求1所述的一种基于自监督表示学习的企业单位地址匹配方法,其特征在于,步骤(4)中,所述无监督的学习方式利用模型中的dropout mask,对每一个句子进行两次前向传播,得到两个不同的embeddings向量,将同一个句子得到的向量对作为正样本对,对于每一个向量,选取其他句子产生的embeddings向量作为负样本,以此来训练文本匹配模型。
4.根据权利要求1所述的一种基于自监督表示学习的企业单位地址匹配方法,其特征在于,步骤(4)中,自监督表示学习的损失函数定义如下:
5.一种基于自监督表示学习的企业单位地址匹配装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,其特征在于,所述处理器执行所述可执行代码时,用于实现如权利要求1-4中任一项所述的基于自监督表示学习的企业单位地址匹配方法的步骤。
6.一种计算机可读存储介质,其上存储有程序,其特征在于,该程序被处理器执行时,实现如权利要求1-4中任一项所述的基于自监督表示学习的企业单位地址匹配方法的步骤。
技术总结
本发明公开了一种基于自监督表示学习的企业单位地址匹配方法及装置,该方法首先根据具体应用场景规则制定正负样本对,同时通过无监督和有监督结合的这两种方式进行深度学习模型的训练学习。通过两种训练方式的结合,可以在少量标注样本的情况下,学习到特定场景下更具有区分度的语义表征,实现对企业单位地址的精准匹配;本发明方法主要分为三个部分:正负训练样本对的规则制定、无监督和有监督结合的模型训练方式、基于自监督表示学习对单位地址的匹配。本发明方法可在少量标注样本的情况下,学习特定场景下更具有区分度的语义表征,并且实现单位地址的精准匹配,同时在评价指标上优于近几年最先进的模型。
技术研发人员:李莹,金路,汪陈笑,陈盼盼,邓静
受保护的技术使用者:浙江邦盛科技股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!