汽车类文本数据增强方法、装置、电子设备及存储介质与流程
本公开涉及自然语言处理,尤其涉及一种汽车类文本数据增强方法、装置、电子设备及存储介质。
背景技术:
1、在涉及汽车领域自然语言处理场景中,经常利用语言处理模型从海量的文本数据中识别出具有场景针对性的汽车领域文本数据,这就要求语言处理模型对汽车领域的文本数据具有较高的识别准确率。
2、若用于训练语言处理模型的汽车类文本数据较少,会导致所训练出的语言处理模型的泛化能力有限,对汽车领域文本数据的识别准确率较低,不能满足使用需求,因此需要对汽车类文本数据进行增强处理,以扩大可用于训练语言处理模型的汽车类文本数据的数据量。
3、但是,在对汽车类文本数据进行增强处理的过程中,多采用随机地对已有的文本数据中的词组进行替换,这种方式所得到的新的文本数据经常出现逻辑错误、或语句不通顺等问题,不满足作为训练样本数据的基本要求。
技术实现思路
1、为了解决上述技术问题,本公开提供了一种汽车类文本数据增强方法、装置、电子设备及存储介质。
2、第一方面,本公开提供了一种汽车类文本数据增强方法,包括:
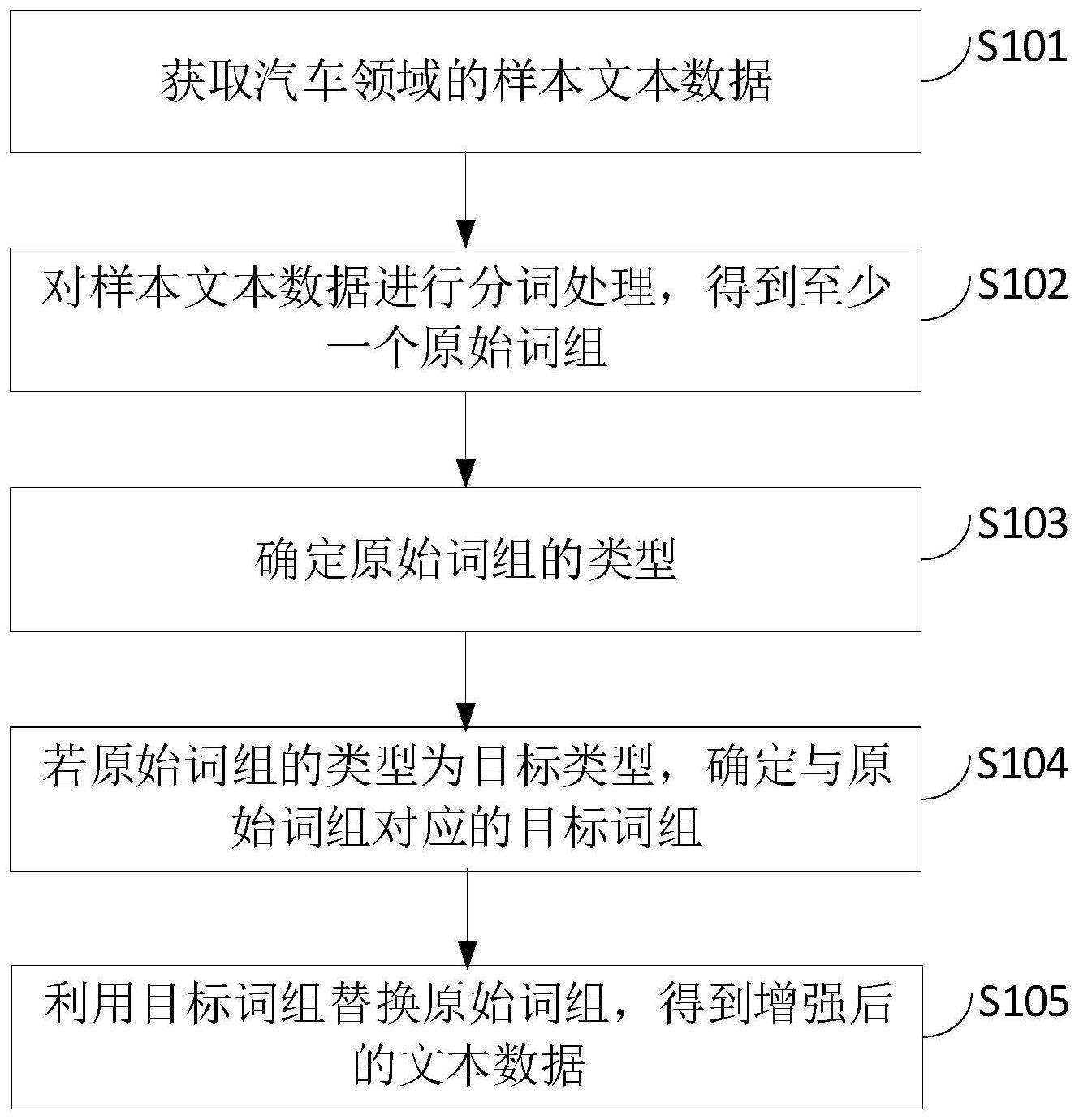
3、获取汽车领域的样本文本数据;
4、对所述样本文本数据进行分词处理,得到至少一个原始词组;
5、确定所述原始词组的类型;
6、若所述原始词组的类型为目标类型,确定与所述原始词组对应的目标词组;
7、利用所述目标词组替换所述原始词组,得到增强后的文本数据。
8、第二方面,本公开还提供了一种汽车类文本数据增强装置,包括:
9、获取模块,用于获取汽车领域的样本文本数据;
10、分词模块,用于对所述样本文本数据进行分词处理,得到至少一个原始词组;
11、第一确定模块,用于确定所述原始词组的类型;
12、第二确定模块,用于若所述原始词组的类型为目标类型,确定与所述原始词组对应的目标词组;
13、替换模块,用于利用所述目标词组替换所述原始词组,得到增强后的文本数据。
14、第三方面,本公开还提供了一种电子设备,包括:处理器和存储器;
15、处理器通过调用存储器存储的程序或指令,用于执行上述任一方法的步骤。
16、第四方面,本公开还提供了一种计算机可读存储介质,计算机可读存储介质存储程序或指令,程序或指令使计算机执行上述任一方法的步骤。
17、本公开实施例提供的技术方案与现有技术相比具有如下优点:
18、本公开实施例提供的技术方案,通过对样本文本数据进行分词处理,得到至少一个原始词组;确定原始词组的类型;若原始词组的类型为目标类型,确定与原始词组对应的目标词组;利用目标词组替换原始词组,得到增强后的文本数据,可实现对原始词组进行合理归类,有选择性地对目标类型的原始词组进行替换,以确保原始词组和对应的目标词组语义尽可能接近、感情色彩尽可能接近、使用场景尽可能接近,进而达到降低替换后的句子出现逻辑错误、或语句不通顺等问题的几率的目的,进而达到扩大可用于训练语言处理模型的汽车类文本数据的数据量,使得所训练出的语言处理模型对汽车领域的文本数据具有较高的识别准确率。
技术特征:
1.一种汽车类文本数据增强方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述对所述样本文本数据进行分词处理,包括:
3.根据权利要求1所述的方法,其特征在于,所述确定与所述原始词组对应的目标词组,包括:
4.根据权利要求1所述的方法,其特征在于,所述确定与所述原始词组对应的目标词组,包括:
5.根据权利要求4所述的方法,其特征在于,所述确定所述原始词组和所述备选词组集合中各所述备选词组的相似度,包括:
6.根据权利要求1所述的方法,其特征在于,所述确定与所述原始词组对应的目标词组,包括:
7.根据权利要求4或6所述的方法,其特征在于,所述筛选条件为相似度最高,且相似度大于第三阈值。
8.一种汽车类文本数据增强装置,其特征在于,包括:
9.一种电子设备,其特征在于,包括:处理器和存储器;
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储程序或指令,所述程序或指令使计算机执行如权利要求1至7任一项所述方法的步骤。
技术总结
本公开涉及一种汽车类文本数据增强方法、装置、电子设备及存储介质,方法包括:获取汽车领域的样本文本数据;对所述样本文本数据进行分词处理,得到至少一个原始词组;确定所述原始词组的类型;若所述原始词组的类型为目标类型,确定与所述原始词组对应的目标词组;利用所述目标词组替换所述原始词组,得到增强后的文本数据。其可实现对原始词组进行合理归类,有选择性地对目标类型的原始词组进行替换,以确保原始词组和对应的目标词组语义尽可能接近、感情色彩尽可能接近、使用场景尽可能接近,进而达到降低替换后的句子出现逻辑错误、或语句不通顺等问题的几率的目的。
技术研发人员:黄海涛,焦俊铭,乔举义,王阳,康清国,李波
受保护的技术使用者:北京罗克维尔斯科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!