一种基于Simhash模型的专利相关度判定方法与流程
本发明涉及专利信息处理,特别是涉及一种基于simhash模型的专利相关度判定方法。
背景技术:
1、随着科技的发展,知识产权保护越来越受到企业的关注,专利作为知识产权保护最重要的载体,各个企业为防范知识产权重大风险,提高企业知识产权风险预测预警和防控能力,针对不同的技术领域建设专利预警系统,对于专利预警系统的建设而言,分析已有的专利数据样本是一项很重要的工作,在专利数据样本分析的过程中,要将本企业的专利技术特征与相关领域专利技术特征进行比较,寻找侵权的可能性。目前,并没有专业的软件对专利样本所述的技术内容进行自动比对,大部分工作由人工完成,工作量大,效率低,易出错。
2、基于此,有必要提供一种新的专利相关度判定方法解决上述问题。
技术实现思路
1、针对现有技术中存在的不足,本发明的目的在于提供一种基于simhash模型的专利相关度判定方法,采用simhash模型计算专利之间的相似性,通过计算机实现专利之间的自动比对,提高了工作效率和准确性。
2、为了实现上述目的,本发明提供的技术方案是:
3、一种基于simhash模型的专利相关度判定方法,包括以下步骤:
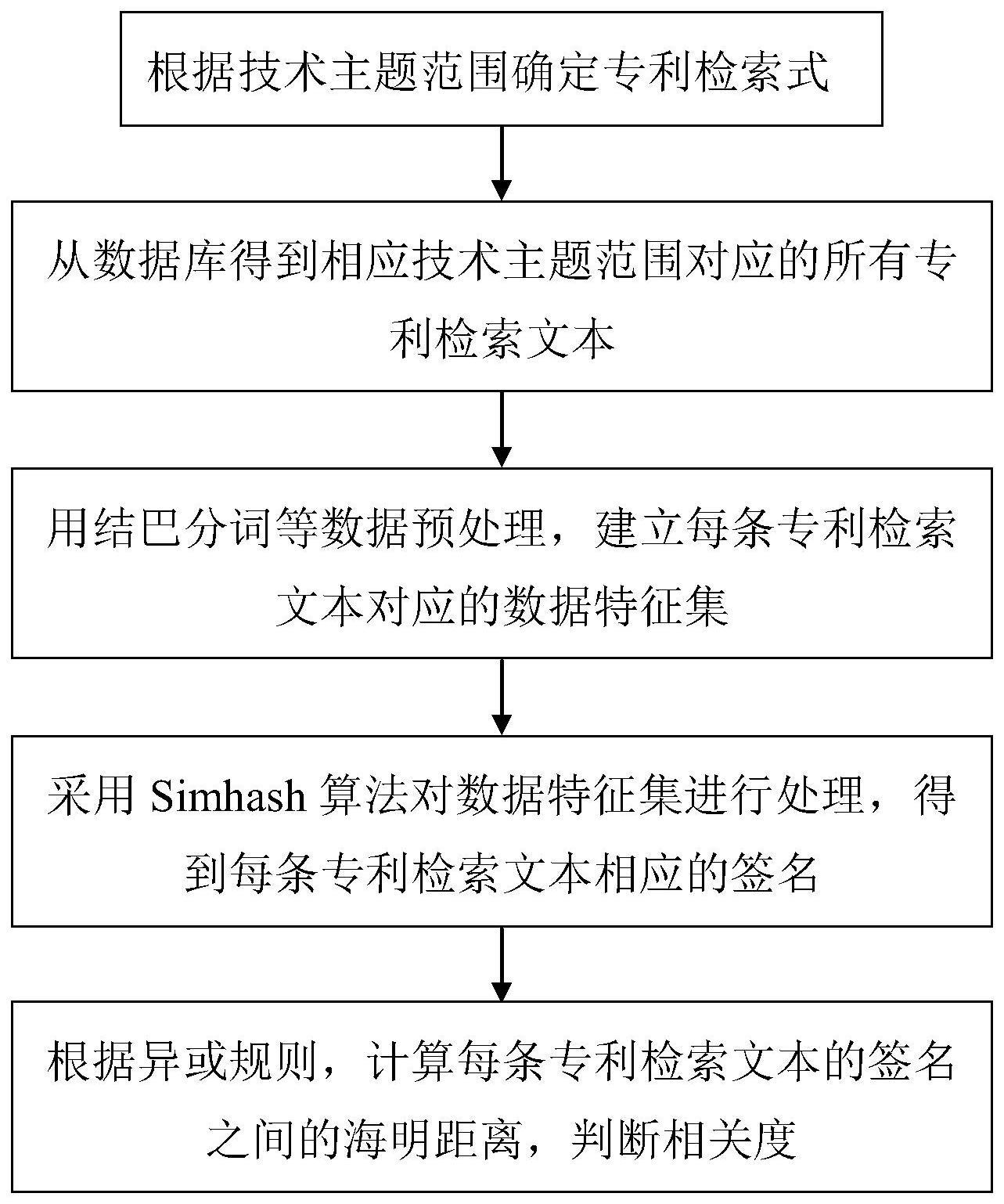
4、步骤1:根据技术主题范围确定专利检索式;
5、步骤2:用确定的专利检索式从数据库得到相应技术主题范围对应的所有专利检索文本;
6、步骤3:对得到的每条专利检索文本进行结巴分词(jieba),删除停用词、去标点符号、python同义词归一化处理,提取专利检索文本中n个特征词,建立每条专利检索文本对应的数据特征集;
7、步骤4:采用simhash算法对得到的每条专利检索文本的数据特征集进行处理,得到每条专利检索文本相应的签名;
8、步骤5:根据异或规则,计算每条专利检索文本的签名之间的海明距离,根据海明距离判定专利检索文本之间的相关度。
9、在一些实施例中,专利检索式包括关键词、ipc分类号、cpc分类号和申请人。
10、在一些实施例中,采用simhash算法对得到的每条专利检索文本的数据特征集进行处理,得到每条专利检索文本相应的签名,包括:
11、根据每条专利检索文本中特征词出现的次数计算每个特征词的权值,运用simhash算法形成每个特征词对应的签名;将每个特征词对应的签名和相对应的权值相乘,得到特征词的特征向量;然后将所有特征词对应的特征向量相加,得到一个最终向量;通过01降维,最后得到每条专利检索文本的simhash值。
12、在一些实施例中,每个特征词的权值计算公式为:
13、
14、其中,wv表示特征词v的权值,nij表示特征词v在专利检索文本dj中出现的次数,∑knk,j表示在专利检索文本dj中所有特征词的出现次数之和,a表示相应技术主题范围对应的所有专利检索文本数量,m表示相应技术主题范围对应的所有专利检索文本中包含特征词v的专利检索文本的数量。
15、在一些实施例中,01降维是指,采用simhash算法对得到的每条专利检索文本的数据特征集进行处理的过程中,对最终向量中对应的每一位数,若大于0,则取1,若小于0,则取0,得到每条专利检索文本的simhash值。
16、在一些实施例中,根据异或规则,计算每条专利检索文本的签名之间的海明距离,根据海明距离判定专利检索文本之间的相关度,包括:计算每两条专利检索文本的各自simhash值相对位置不相同的个数,根据相对位置不相同的个数判断每两条专利检索文本之间的相关度。
17、在一些实施例中,根据相对位置不相同的个数判断每两条专利检索文本之间的相关度包括:如果相对位置不相同的个数大于3,则判定为高相关专利,如果相对位置不相同的个数小于3,则判定为低相关专利。
18、在一些实施例中,数据库为智慧芽。
19、在一些实施例中,对得到的每条专利检索文本进行结巴分词(jieba),删除停用词、去标点符号、python同义词归一化处理,步骤为:依次进行结巴分词、删除停用词、去标点符号、python同义词归一化处理。
20、在一些实施例中,特征词是计算机提取出来的,n与专利检索文本有关。
21、本发明的有益效果为:
22、本发明的基于simhash模型的专利相关度判定方法,通过数据挖掘技术来代替现有的传统专利分析方法,用simhash算法获取大量专利数据中原来无法挖掘到的内容和规律,充分发挥了数据挖掘技术应用在专利分析中的作用;通过对专利数据进行分词、提取特征词并建立特征词权值模型,同时结合simhash算法对专利进行相关度分析,筛选出高相关专利,在企业知识产权保护工作中节约了大量人工阅读的时间并提高了专利相关性判定的准确性。
技术特征:
1.一种基于simhash模型的专利相关度判定方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于simhash模型的专利相关度判定方法,其特征在于,所述专利检索式包括关键词、ipc分类号、cpc分类号和申请人。
3.根据权利要求2所述的基于simhash模型的专利相关度判定方法,其特征在于,所述采用simhash算法对得到的所述每条专利检索文本的数据特征集进行处理,得到所述每条专利检索文本相应的签名,包括:
4.根据权利要求3所述的基于simhash模型的专利相关度判定方法,其特征在于,所述每个特征词的权值计算公式为:
5.根据权利要求3所述的基于simhash模型的专利相关度判定方法,其特征在于,所述01降维是指,采用simhash算法对得到的所述每条专利检索文本的数据特征集进行处理的过程中,对所述最终向量中对应的每一位数,若大于0,则取1,若小于0,则取0,得到所述每条专利检索文本的simhash值。
6.根据权利要求3所述的基于simhash模型的专利相关度判定方法,其特征在于,根据异或规则,计算所述每条专利检索文本的签名之间的海明距离,根据海明距离判定所述专利检索文本之间的相关度,包括:计算每两条专利检索文本的各自simhash值相对位置不相同的个数,根据相对位置不相同的个数判断所述每两条专利检索文本之间的相关度。
7.根据权利要求6所述的基于simhash模型的专利相关度判定方法,其特征在于,所述根据相对位置不相同的个数判断所述每两条专利检索文本之间的相关度包括:如果相对位置不相同的个数大于3,则判定为高相关专利,如果相对位置不相同的个数小于3,则判定为低相关专利。
8.根据权利要求1所述的基于simhash模型的专利相关度判定方法,其特征在于,所述数据库为智慧芽。
9.根据权利要求1所述的基于simhash模型的专利相关度判定方法,其特征在于,所述对得到的每条专利检索文本进行结巴分词,删除停用词、去标点符号、python同义词归一化处理,步骤为:依次进行结巴分词、删除停用词、去标点符号、python同义词归一化处理。
10.根据权利要求3所述的基于simhash模型的专利相关度判定方法,其特征在于,所述特征词是计算机提取出来的,所述n与所述专利检索文本有关。
技术总结
一种基于Simhash模型的专利相关度判定方法,包括:根据技术主题范围确定专利检索式;用确定的专利检索式从数据库得到相应技术主题范围对应的所有专利检索文本;对得到的每条专利检索文本进行结巴分词,删除停用词、去标点符号、Python同义词归一化处理,提取专利检索文本中n个特征词,建立每条专利检索文本对应的数据特征集;采用Simhash算法对得到的每条专利检索文本的数据特征集进行处理,得到每条专利检索文本相应的签名;根据异或规则,计算每条专利检索文本的签名之间的海明距离,根据海明距离判定专利检索文本之间的相关度。本发明方法通过数据挖掘技术来获取大量专利数据中原来无法挖掘到的内容和规律,节约人工阅读时间并提高专利相关性判定准确性。
技术研发人员:侯腾飞,吴优,李佳,何睿
受保护的技术使用者:攀钢集团攀枝花钢铁研究院有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!