一种双向生成领域自适应数据分类方法
本发明涉及数据分类领域,尤其是涉及一种双向生成领域自适应数据分类方法。
背景技术:
1、随着迁移学习相关研究的持续发展和不断深入,涌现出了各种领域自适应迁移学习算法用以提升对异构分布数据的迁移性能,这些迁移算法按其采用的思想策略大体上可以归为两大类:
2、其一是基于统计学习的迁移学习方法。统计学习思想是最早被应用于解决迁移学习问题的方法,以源域数据与目标域数据间的统计学特征为依据,人为设计跨域迁移变换机制。此类方法大多通过分析源域数据与目标域数据间的边缘分布或条件分布差异,利用设计好的域间迁移变换函数对跨域数据的实例特征进行映射,从而降低映射后源域与目标域数据间的分布差异。其中包括基于最大均值化差异(mmd)准则的分布适配法、基于kl散度的实例权重法、基于联合分布差异的联合分布自适应(jda)算法等代表性方法。
3、其二是基于生成式对抗网络的迁移学习方法。随着迁移学习应用需求的复杂化,针对特定迁移任务人为设计域迁移变换机制的方法越来越难以满足迁移学习日益广泛的应用场景,因此模型自适应的迁移变换机制成为更高效且普适的选择,利用深度神经网络在模型训练迭代过程中自主地匹配源域数据与目标域数据间的分布特征,提高领域自适应迁移学习方法在不同源域与目标域间的迁移性能。其中具有代表性的即是基于生成式对抗网络(gan)来实现领域自适应迁移学习,如领域对抗训练网络(dann)、深度领域混合(ddc)、对抗性领域自适应(adda)、条件对抗领域自适应网络(cdan)等等,因其与深度神经网络在网络结构上具有极高的契合度,已然成为当前实现领域自适应迁移学习的主流方法。
4、目前两类方法都存在一定的缺陷和不足。基于统计学习的迁移学习方法,虽然能够稳步地降低源域与目标域数据间的分布差异,但针对不同任务需人为设计域间映射变换方法,缺乏普适性,无法满足实际应用场景中的迁移需求;基于生成式对抗网络的迁移学习方法,针对异构分布数据分类模型迁移具有更好的性能表现,但需要耗费更多的计算资源,在针对某些特定领域问题以及源域目标域间分布差异较大的情况时由于方法是单向迁移,无法充分利用目标域数据结构特征。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的缺陷而提供的一种双向生成领域自适应数据分类方法,本方法降低源域数据和目标域数据的分布差异,同时利用源域和目标域双分支分别训练两个分类器,并通过一致性损失加以约束,从而实现满足复杂任务要求的领域自适应迁移学习。
2、本发明的目的可以通过以下技术方案来实现:
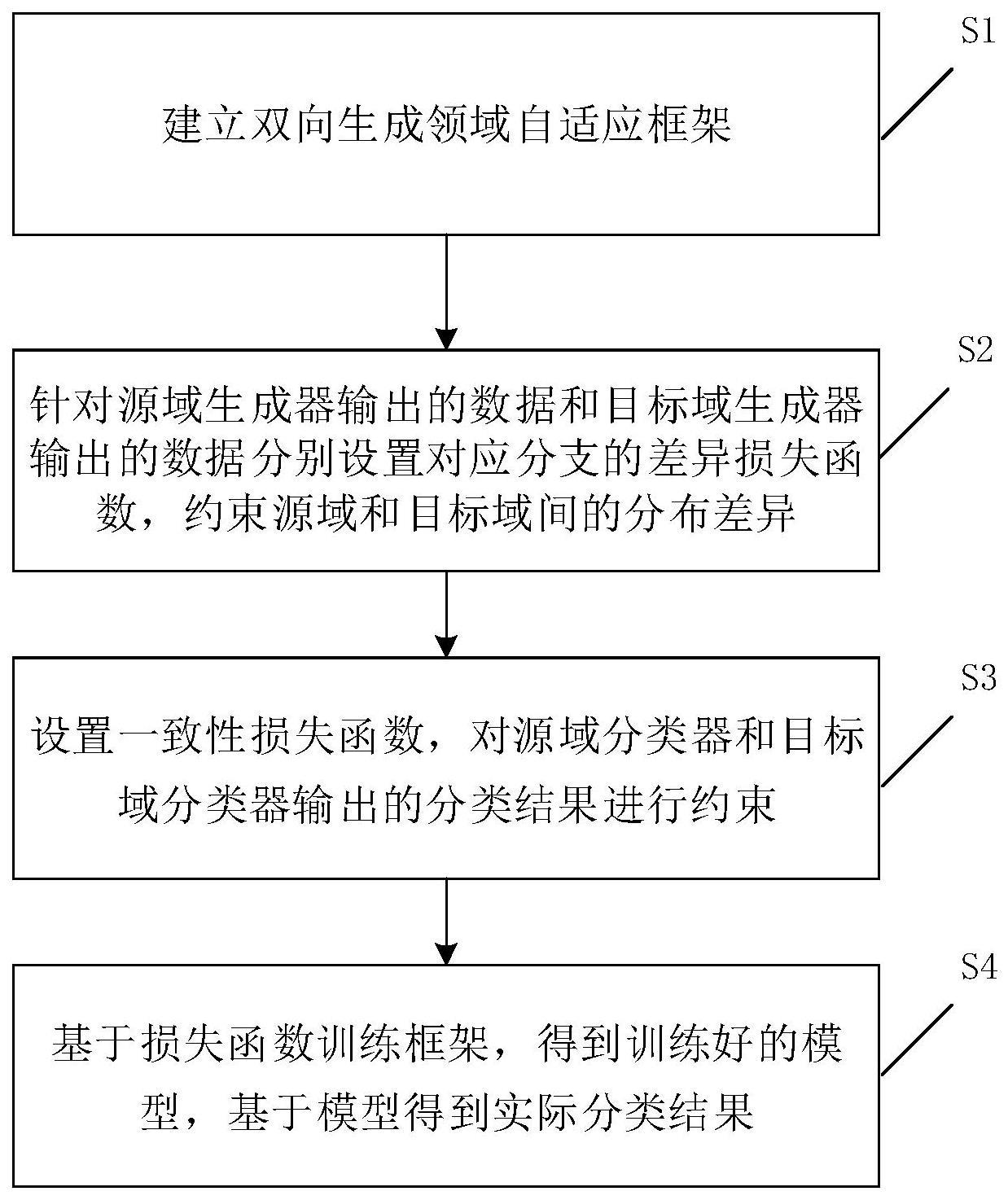
3、一种双向生成领域自适应数据分类方法,方法包括以下步骤:
4、s1、建立双向生成领域自适应框架,框架包括2个分支,分别为带标签的源域和无标签的目标域,2个分支进行双向的生成对抗和迭代训练,目标域训练过程中,采用伪标签代替目标域标签信息,
5、其中,源域包括源域生成器和源域分类器,目标域包括目标域生成器和目标域分类器,源域生成器的输入为源域数据,源域分类器的输入为源域生成器输出的数据和源域数据,目标域生成器的输入为目标域数据,目标域分类器的输入为目标域生成器输出的数据和源域生成器输出的数据,分类器输出分类结果;
6、对源域和目标域分别设置生成式对抗网络的损失函数;
7、s2、针对源域生成器输出的数据和目标域生成器输出的数据分别设置对应分支的差异损失函数,基于差异损失函数约束源域和目标域间的分布差异,其中,源域的差异损失函数的表达式为:
8、
9、其中,k为类别数目,为源域整体gmmd损失,为源域类间cmmd损失;
10、目标域的差异损失函数的表达式为:
11、
12、其中,k为类别数目,为目标域整体gmmd损失,为目标域类间cmmd损失;
13、s3、设置一致性损失函数,对源域分类器和目标域分类器输出的分类结果进行约束;
14、s4、基于生成式对抗网络的损失函数、差异损失函数和一致性损失函数对框架进行训练,得到训练完成的双向生成领域自适应模型,向训练完成的双向生成领域自适应模型输入作为模型的目标域数据的实际数据,得到实际分类结果。
15、进一步地,所述伪标签基于源域数据训练得到的分类模型得到。
16、进一步地,伪标签的表达式为:
17、
18、其中,为伪标签,xt为目标域数据,c0为基于源域数据训练得到的分类模型。
19、进一步地,目标域的差异损失函数约束目标域生成器输出的数据与源域数据之间的分布差异。
20、进一步地,源域的差异损失函数约束源域生成器输出的数据与目标域数据之间的分布差异。
21、进一步地,对于源域,生成式对抗网络的损失函数为:
22、
23、其中,为源域的生成式对抗网络的损失函数,xs为源域数据,为源域的判别误差,为源域的分类误差。
24、进一步地,对于目标域,生成式对抗网络的损失函数为:
25、
26、其中,为目标域的生成式对抗网络的损失函数,xt为目标域数据,为目标域的判别误差,为目标域的分类误差。
27、进一步地,生成式对抗网络的损失函数中的误差为交叉熵损失。
28、进一步地,对双向的生成对抗和迭代训练包括对源域分类器和目标域分类器的训练。
29、进一步地,基于一致性损失函数实现源域分类器和目标域分类器的相互迭代训练。
30、与现有技术相比,本发明具有以下优点:
31、(1)本发明针对单向生成式对抗领域自适应迁移方法无法充分利用目标域数据结构特征的问题,通过源域和目标域双向生成式对抗的双分支结构,实现源域到目标域和目标域到源域两个方向的分布匹配,高效稳定地降低源域数据与目标域数据间的分布差异,尤其适合源域与目标域间分布差异较大的复杂任务场景下的模型迁移。
32、(2)源域生成器的差异损失函数中设置整体和类间两种损失,作为距离约束,更好地降低跨域数据间的概率分布差异,在匹配源域数据和目标域数据整体分布特征的同时,进一步减少源域与目标域相同类别数据间的分布差异,从而明确目标域数据间的类别边界,避免目标域数据类间重叠对模型自适应迁移性能的影响。
33、(3)针对不同的应用场景,本发明可以灵活调整模型结构,具有较好的普适性。
技术特征:
1.一种双向生成领域自适应数据分类方法,其特征在于,方法包括以下步骤:
2.根据权利要求1所述的一种双向生成领域自适应数据分类方法,其特征在于,所述伪标签基于源域数据训练得到的分类模型得到。
3.根据权利要求2所述的一种双向生成领域自适应数据分类方法,其特征在于,伪标签的表达式为:
4.根据权利要求1所述的一种双向生成领域自适应数据分类方法,其特征在于,目标域的差异损失函数约束目标域生成器输出的数据与源域数据之间的分布差异。
5.根据权利要求1所述的一种双向生成领域自适应数据分类方法,其特征在于,源域的差异损失函数约束源域生成器输出的数据与目标域数据之间的分布差异。
6.根据权利要求1所述的一种双向生成领域自适应数据分类方法,其特征在于,对于源域,生成式对抗网络的损失函数为:
7.根据权利要求1所述的一种双向生成领域自适应数据分类方法,其特征在于,对于目标域,生成式对抗网络的损失函数为:
8.根据权利要求6或7所述的一种双向生成领域自适应数据分类方法,其特征在于,生成式对抗网络的损失函数中的误差为交叉熵损失。
9.根据权利要求1所述的一种双向生成领域自适应数据分类方法,其特征在于,对双向的生成对抗和迭代训练包括对源域分类器和目标域分类器的训练。
10.根据权利要求1所述的一种双向生成领域自适应数据分类方法,其特征在于,基于一致性损失函数实现源域分类器和目标域分类器的相互迭代训练。
技术总结
本发明涉及一种双向生成领域自适应数据分类方法,方法包括以下步骤:S1、建立双向生成领域自适应框架;S2、针对源域生成器输出的数据和目标域生成器输出的数据分别设置对应分支的差异损失函数;S3、设置一致性损失函数;S4、向训练完成的双向生成领域自适应模型输入实际数据,得到实际分类结果。与现有技术相比,本发明降低源域数据和目标域数据的分布差异,同时利用源域和目标域双分支分别训练两个分类器,并通过一致性损失加以约束,从而实现满足复杂任务要求的领域自适应迁移学习。
技术研发人员:康琦,赵俣,姚思雅,李浩军,徐其慧
受保护的技术使用者:同济大学
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!