一种磁盘故障预测模型的构建方法及应用
本发明属于磁盘故障预测,更具体地,涉及一种磁盘故障预测模型的构建方法及应用。
背景技术:
1、随着信息产业的发展,大量的数据不断生成,推动了数据存储服务的发展。存储系统的稳定性与服务供应商的效益密切相关,存储系统故障会给使用者造成巨大损失。大多数存储系统故障都来源于磁盘的故障,因此,对磁盘是否发生故障进行预测,提高磁盘的可靠性是必要且重要的。
2、随着机器学习技术的发展与应用,机器学习模型被大量应用在磁盘故障预测领域中,基于机器学习的磁盘故障预测模型,通过磁盘的日志数据,即自我监测分析和报告技术(samrt),实现了较高的磁盘故障预测准确性。然而磁盘故障预测的准确性受诸如磁盘异构、模型老化、环境差异、小样本等因素的影响较大,在现有的基于机器学习模型的磁盘故障预测方法中,一部分方法是在考虑某一具体因素的影响下进行的磁盘故障预测,通过按照某一具体因素的相应属性对磁盘smart数据进行划分后进行适应于该因素影响下的磁盘故障预测,然而这种方法只善于处理单一特定因素影响下的故障预测问题,对于多个因素同时存在的场景,预测准确性较低。
3、为了解决上述挑战,一部分方法采用迁移学习配合周期性更新的方法,使适应于磁盘异构因素影响下的磁盘故障预测模型也能够解决模型老化因素影响下的磁盘故障预测问题。然而这种方法仅适用于处理存在磁盘异构和模型老化这两个因素的场景,当磁盘异构、模型老化、环境差异、小样本等更多因素混合存在时无法进行推广。另外,适用于磁盘异构这一因素的迁移学习模型所采用的迁移学习算法大多只能实现从单个域到单个域的迁移,且这类迁移往往需要大量样本支持,在环境差异与小样本因素也混合存在的场景下,现有的磁盘故障预测模型无法达到令人满意的精确度。
技术实现思路
1、针对现有技术的以上缺陷或改进需求,本发明提供了一种磁盘故障预测模型的构建方法及应用,用以解决现有技术在多个因素混合影响的场景下,无法对磁盘是否发生故障进行准确预测的技术问题。
2、为了实现上述目的,第一方面,本发明提供了一种磁盘故障预测模型的构建方法,包括以下步骤:
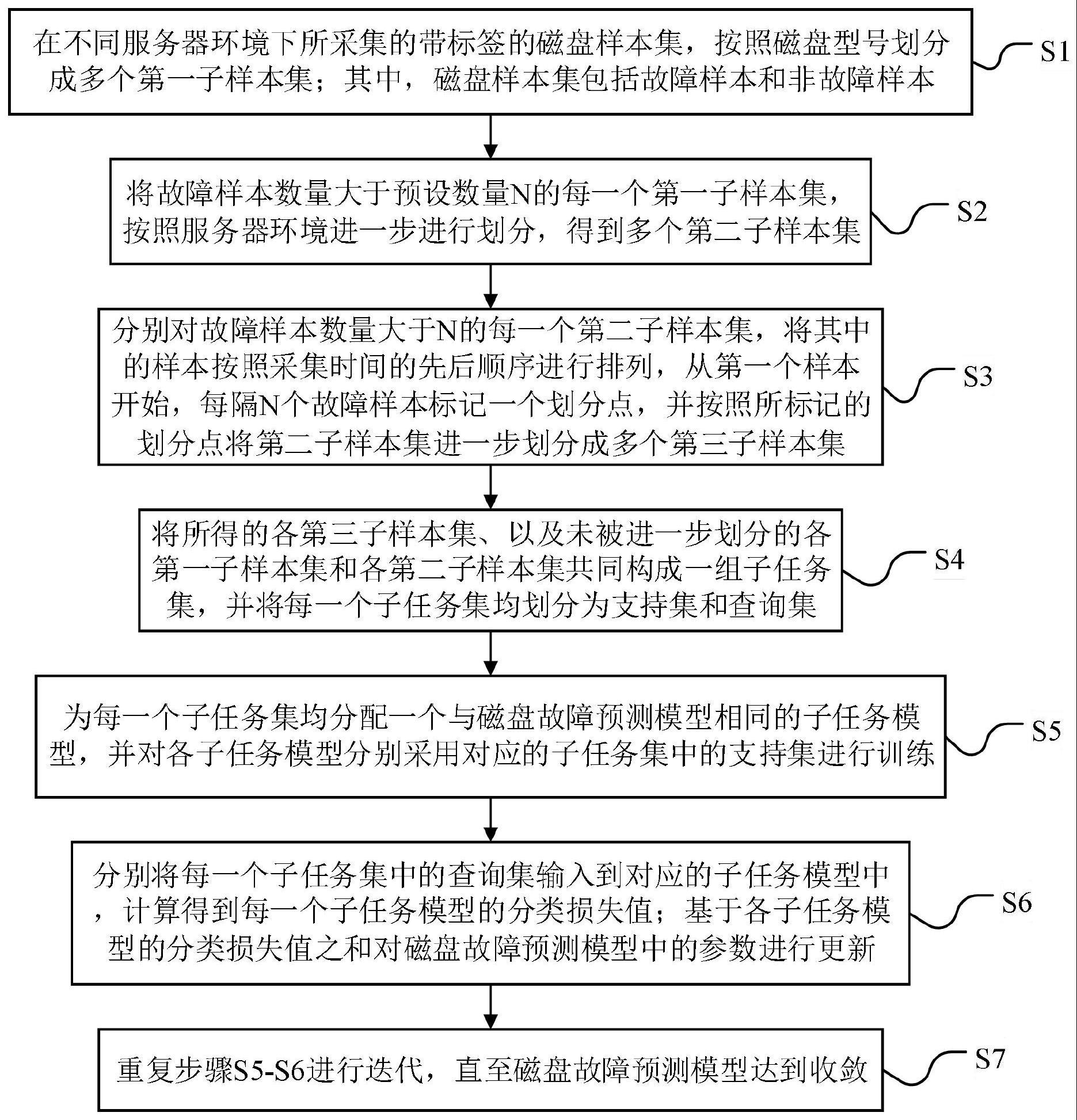
3、s1、在不同服务器环境下所采集的带标签的磁盘样本集,按照磁盘型号划分成多个第一子样本集;其中,磁盘样本集包括故障样本和非故障样本;
4、s2、将故障样本数量大于预设数量n的每一个第一子样本集,按照服务器环境进一步进行划分,得到多个第二子样本集;
5、s3、分别对故障样本数量大于n的每一个第二子样本集,将其中的样本按照采集时间的先后顺序进行排列,从第一个样本开始,每隔n个故障样本标记一个划分点,并按照所标记的划分点将第二子样本集进一步划分成多个第三子样本集;
6、s4、将所得的各第三子样本集、以及未被进一步划分的各第一子样本集和各第二子样本集共同构成一组子任务集,并将每一个子任务集均划分为支持集和查询集;
7、s5、为每一个子任务集均分配一个与磁盘故障预测模型相同的子任务模型,并对各子任务模型分别采用对应的子任务集中的支持集进行训练;
8、s6、分别将每一个子任务集中的查询集输入到对应的子任务模型中,计算得到每一个子任务模型的分类损失值;基于各子任务模型的分类损失值之和对磁盘故障预测模型中的参数进行更新;
9、s7、重复步骤s5-s6进行迭代,直至磁盘故障预测模型达到收敛。
10、进一步优选地,上述磁盘样本为磁盘smart数据。
11、进一步优选地,上述预设数量n取值为70。
12、进一步优选地,各子任务模型的训练过程并行执行。
13、第二方面,本发明提供了一种磁盘故障预测方法,包括以下步骤:
14、获取多个带标签的磁盘样本,构成预测支持集;其中,预测支持集中的磁盘样本与待预测磁盘样本所对应的磁盘型号相同,所处的服务器环境相同,采集时间间隔在预设时间间隔内;
15、采用预测支持集对本发明第一方面所构建的磁盘故障预测模型进行微调后,将待预测磁盘样本输入到磁盘故障预测模型中,以对待预测磁盘是否发生故障进行预测。
16、第三方面,本发明提供了一种磁盘故障预测系统,包括:存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时执行本发明第二方面所提供的磁盘故障预测方法。
17、第四方面,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序被处理器运行时控制所述存储介质所在设备执行本发明第一方面所提供的磁盘故障预测模型的构建方法和/或本发明第二方面所提供的磁盘故障预测方法。
18、总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
19、1、本发明提供了一种磁盘故障预测模型的构建方法,将磁盘异构、模型老化、环境差异等因素视作同一因素(数据异构)进行处理,并将磁盘故障预测中的小样本问题看作处理数据异构所导致的结果,通过将采集到的磁盘样本集按照磁盘故障预测中不同因素所对应的属性(磁盘型号、服务器环境、采样时间)进行分层划分,得到多个所包含的故障样本数量基本相当的子样本集,能够很好的平衡数据异构问题和小样本问题,在此基础上,将划分得到的多个子样本集视作多任务,进行多任务学习,实现了多个域下的迁移学习,能够适应多问题混合存在的磁盘故障预测场景,预测精度较高。
20、2、在本发明所提供的磁盘故障预测模型的构建方法中,各子任务模型的训练过程可以并行执行,能够以较低的时间开销提升磁盘故障预测模型的预测性能。
21、3、本发明所提供的磁盘故障预测模型的构建方法能够简单的推广到其他影响磁盘故障预测模型精度的因素上,也能够在未知任务,即未知磁盘型号、服务器环境、采样时间下的样本构成的任务上快速适收敛,消除了小样本因素的影响,具有更高的泛用性。举例而言,某些场景下,空气湿度这一因素对磁盘的故障与否影响显著,可以按照磁盘所处的湿度等级将样本进一步划分得到更细粒度的数据子集,把这些子集当做任务,亦可直接套用本发明使用的训练、预测方式进行处理。
技术特征:
1.一种磁盘故障预测模型的构建方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的磁盘故障预测模型的构建方法,其特征在于,所述磁盘样本为磁盘smart数据。
3.根据权利要求1所述的磁盘故障预测模型的构建方法,其特征在于,所述预设数量n取值为70。
4.根据权利要求1-3任意一项所述的磁盘故障预测模型的构建方法,其特征在于,各所述子任务模型的训练过程并行执行。
5.一种磁盘故障预测方法,其特征在于,包括以下步骤:
6.一种磁盘故障预测系统,其特征在于,包括:存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时执行权利要求5所述的磁盘故障预测方法。
7.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序被处理器运行时控制所述存储介质所在设备执行权利要求1-4任意一项所述的磁盘故障预测模型的构建方法和/或权利要求5所述的磁盘故障预测方法。
技术总结
本发明公开了一种磁盘故障预测模型的构建方法及应用,属于磁盘故障预测技术领域,本发明将磁盘异构、模型老化、环境差异等因素视作数据异构这一因素进行处理,并将磁盘故障预测中的小样本问题看作处理数据异构所导致的结果,通过将采集到的磁盘样本集按照磁盘故障预测中不同因素所对应的属性(磁盘型号、服务器环境、采样时间)进行分层划分,得到多个所包含的故障样本数量基本相当的子样本集,能够很好的平衡数据异构问题和小样本问题,在此基础上,将划分得到的多个子样本集视作多任务,进行多任务学习,实现了多个域下的迁移学习,能够适应多问题混合存在的磁盘故障预测场景,预测精度较高。
技术研发人员:刘渝,关云川,周可,李强,李娟,张海军
受保护的技术使用者:华中科技大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!