一种测试卡检测项目识别方法及便携干式生化分析系统与流程
1.本发明属于医疗领域,涉及一种测试卡检测项目识别方法及便携干式生化分析系统。
背景技术:
2.采用测试卡对要检测的内容进行检测,从而得到检测结果,在医疗干式生化检测领域是比较常见的技术。对于检测项目检测方法中,已上市的产品主要通过2种方法实现:1)通过试剂卡上集成二维码的方式实现:二维码内存储检测项目信息,仪器内摄像头获取并识别二维码,完成测试卡测试测试项目获取;2)每盒试纸条配备对应的id卡,通过获取id卡内检测信息,实现此盒试纸条检测项目获取。方法1)中要求试剂卡上印有二维码,仪器内集成扫码装置,这会导致试纸条足够大,能同时容纳二维码及测试项目所需试剂试纸,因此限制了仪器的便携性,提高了仪器及测试卡的制造成本,方法1)目前还主要用于大型设备上;方法2)中,检测项目信息存储在id卡芯片内,id卡与测试卡分离,测试时先插入id卡,读取试剂卡信息,由于id卡与测试卡分离,无法保证id卡信息与实际测试卡的一致性,操作失误风险高。由此可见,目前尚未有可以实现试纸条项目识别的便携式干式生化分析设备。
技术实现要素:
3.为克服上述现有技术的不足,本发明提出一种测试卡检测项目识别方法及便携干式生化分析系统。
4.本发明提供了一种测试卡检测项目识别方法,具体步骤如下:
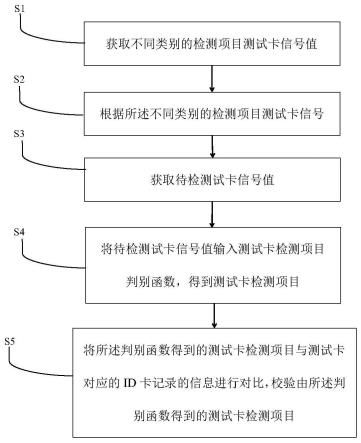
5.s1:获取不同类别的检测项目测试卡信号值;
6.s2:根据所述不同类别的检测项目测试卡信号值,基于fcm聚类获取各检测项目中心点,计算各所述中心点间距离,得到测试卡检测项目判别函数;
7.s3:获取待检测试卡信号值;
8.s4:将待检测试卡信号值输入测试卡检测项目判别函数,得到测试卡检测项目;
9.s5:将所述判别函数得到的测试卡检测项目与测试卡对应的id卡记录的信息进行对比,校验由所述判别函数得到的测试卡检测项目。
10.进一步,所述测试卡中包含多个孔,其中孔的数量至少为3。
11.进一步,s1中获取不同类别的检测项目测试卡信号值具体如下:
12.获取不同类别的检测项目测试卡前3个孔的信号序列,使用信号采集时间1-3s获取模拟光信号,通过模拟-数字转化,将反射回来的连续光信号转换为离散数字信号,各孔的信号序列内信号数量小于10个。
13.进一步,s2中根据所述不同类别的检测项目测试卡信号值,基于fcm聚类获取各检测项目中心点,计算各所述中心点间距离,得到测试卡检测项目判别函数,其具体步骤如下:
14.s21:对采集到的小于10个信离散信号进行均值处理,构建3维信号特征序列s(t),st
={q
t
};
15.s22:以第1个孔信号序列q1为x轴,第2孔信号序列q2为y轴,第3孔信号值q3为z轴,构建基于不同试剂卡类别的三维特征散点图;
16.s23:通过fcm算法对三维特征散点图进行计算得到聚类中心;
17.s24:将计算到聚类中心距离最近的函数作为类别判别函数。
18.进一步,s23中通过fcm算法对三维特征散点图进行计算得到聚类中心,其具体步骤如下:
19.s231:在满足隶属度约束条件的前提下,在0-1间初始化隶属度矩阵u;
20.s232:采用公式求解i个聚类中心;
21.其中,u
ij
为第j个点属于第i类的隶属度,n为空间内点总数,m为权重指数,且m∈[1,+∞);d
ij
为各像素到中心矢量距离;i为分类数目;
[0022]
s233:根据计算价值函数;
[0023]
其中,u为初始隶属度矩阵;d
ij
为各像素到中心矢量距离;v为聚类中心,v=(v1,v2,
…
,vi)
t
;
[0024]
s234:重复上述s231-s233的步骤,直到聚类中心v的变化小于某个阈值或基本不变时停止计算,得到最佳模糊分类矩阵及聚类中心v;
[0025]
其中,u
ij
为第j个点属于第i类的隶属度,n为空间内点总数,u为初始隶属度矩阵;m为权重指数,且m∈[1,+∞);d
ij
为各像素到中心矢量距离;v为聚类中心,v=(v1,v2,
…
,vi)
t
,i为分类数目。
[0026]
进一步,步骤s5中校验由所述判别函数得到的测试卡检测项目具体是在检验过程中在校验成功后提示进入加样检测,完成样本测试;在校验失败提示id卡信息与测试卡不符,提示操作者存在测试异常情况。
[0027]
本发明还提供一种便携干式生化分析系统,所述系统包括多项目联检测试卡、干式生化分析仪;所述多项目联检测试卡用于插入到所述干式生化分析仪内;所述干式生化分析仪实现上述所述测试卡检测项目识别方法。
[0028]
综上所述,与现有上述技术相比,本发明有如下优点:
[0029]
(1)利用不同检测项目间,起始反射信号值差异,构建差异最大化的特征序列,降低了后续识别复杂度,提高识别效率;
[0030]
(2)通过分析干式生化测试卡的信号值可实现反应项目识别,仪器内无需集成扫码装置,极大的提高了仪器便携性,降低了仪器成本;
[0031]
(3)识别信息可与id卡存储信息进行校验,防止由操作失误引起的异常测试情况,提高检测有效性。
附图说明
[0032]
图1示出依据本发明的实施方式,测试卡检测项目识别方法流程图。
[0033]
图2示出依据本发明的实施方式,基于fcm的判别函数获取流程图。
[0034]
图3示出依据本发明的实施方式,测试卡特征三维散点图。
[0035]
图4示出依据本发明的实施方式,计算聚类中心的流程图。
[0036]
图5示出依据本发明的实施方式,便携干式生化分析系统结构图。
具体实施方式
[0037]
以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其他优点与功效。本发明亦可通过其他不同的具体实施例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰和变更。
[0038]
如图1所示,给出了测试卡检测项目识别方法的流程图,具体步骤如下:
[0039]
s1:获取不同类别的检测项目测试卡信号值;
[0040]
其中,所述测试卡中包含多个孔,其中孔的数量至少为3;获取不同类别的检测项目测试卡信号值可以是获取不同类别的检测项目测试卡前3个孔的信号序列,使用信号采集时间1-3s获取模拟光信号,通过模拟-数字转化,将反射回来的连续光信号转换为离散数字信号,各孔的信号序列内信号数量小于10个。
[0041]
s2:根据所述不同类别的检测项目测试卡信号值,基于fcm聚类获取各检测项目中心点,计算各所述中心点间距离,得到测试卡检测项目判别函数;
[0042]
s3:获取待检测试卡信号值;
[0043]
s4:将待检测试卡信号值输入测试卡检测项目判别函数,得到测试卡检测项目;
[0044]
s5:将所述判别函数得到的测试卡检测项目与测试卡对应的id卡记录的信息进行对比,校验由所述判别函数得到的测试卡检测项目。
[0045]
其中,在步骤s5中校验由所述判别函数得到的测试卡检测项目具体是在检验过程中在校验成功后提示进入加样检测,完成样本测试;在校验失败提示id卡信息与测试卡不符,提示操作者存在测试异常情况。
[0046]
如图2所示,给出了基于fcm的判别函数获取流程图,具体步骤如下:
[0047]
s21:对采集到的小于10个信离散信号进行均值处理,构建3维信号特征序列s(t),s
t
={q
t
};
[0048]
在具体实施中,为避免信噪声和环境干扰,根据仪器所产生信号类型,对采集到的《10个信离散信号进行均值处理,在去噪的同时,尽最大保留信号的细节信息;根据各检测项目试纸条特点,取前3个孔内信号值,构建3维信号特征序列s(t),t为孔序列号,t=j时,代表试剂卡第j个孔处信号值,t《4。为避免不同批次试剂卡批件差异,本发明中获取5批次,各项目批次10片测试卡的信号值构建50*3维特征序列:
[0049]
si={qj}
[0050]
其中i为试剂卡类别,i∈{血脂血糖测试卡,肝功能测试卡,肾功能测试卡,代谢测试卡,献血筛查测试卡},j为孔序号,qj为试剂卡第j个孔处信号均值,j《4。
[0051]
s22:以第1个孔信号序列q1为x轴,第2孔信号序列q2为y轴,第3孔信号值q3为z轴,构建基于不同试剂卡类别的三维特征散点图;
[0052]
s23:通过fcm算法对三维特征散点图进行计算得到聚类中心;
[0053]
s24:将计算到聚类中心距离最近的函数作为类别判别函数。
[0054]
应用matlab 2019a,采用本发明所提出的方法对项目信号进行提取,绘制3维空间散点图,例如针对血脂血糖、肝功能、肾功能、代谢、献血筛查的测试卡绘制如图3所示的测
试卡特征三维散点图。如图4所示,给出了通过fcm算法对三维特征散点图进行计算得到聚类中心的流程图,具体步骤如下:
[0055]
s231:在满足隶属度约束条件的前提下,在0-1间初始化隶属度矩阵u;
[0056]
s232:采用公式求解i个聚类中心;
[0057]
所述公式推导过程如下:
[0058]
对于某一多联试剂卡特征序列s为{q1,q2,q3},以q1为x轴,q2为y轴,q3为z轴,则s可表示为三维空间内一点。设u
ij
为第j个点属于第i类的隶属度,n为空间内点总数,则聚类目标函数如下:
[0059][0060]
其中,u为初始隶属度矩阵;m为权重指数,且m∈[1,+∞);d
ij
为各像素到中心矢量距离;v为聚类中心,v=(v1,v2,
…
,vi)
t
,即分类数目为i.。隶属度及聚类中心确定后,利用拉格朗日乘法,令:
[0061]
求解上述方程组(2),便可得到:
[0062][0063][0064]
其中,u
ij
为第j个点属于第i类的隶属度,n为空间内点总数,u为初始隶属度矩阵;m为权重指数,且m∈[1,+∞);d
ij
为各像素到中心矢量距离;v为聚类中心,v=(v1,v2,
…
,vi)
t
,i为分类数目。
[0065]
s233:根据计算价值函数;
[0066]
s234:重复上述s231-s233的步骤,直到聚类中心v的变化小于某个阈值或基本不变时停止计算,得到最佳模糊分类矩阵及聚类中心v;
[0067]
具体的,通过fcm算法计算得到聚类中心后,获取类别判别函数fi,以此判别函数为模板,将模板存储于id卡内:
[0068][0069]
其中,(x0,y0,z0)为需要判别的试剂卡的特征值,(xi,yi,zi)为第i个聚类中心的对应的特征值,fi为数组中最小值对应的i值,即类别值。
[0070]
在具体实施中,使用本发明所提出的方法计算判别函数后对采集的血脂血糖,肝功能,肾功能,代谢,献血筛查各50片测试卡起始信号值进行识别,本发明方法对各测试卡
识别率为100%。
[0071]
如图5所示,给出了便携干式生化分析系统的结构图,所述系统包括多项目联检测试卡、干式生化分析仪;所述多项目联检测试卡用于插入到所述干式生化分析仪内;所述干式生化分析仪实现上述所述测试卡检测项目识别方法。
[0072]
其中,多项目联检测试卡插入干式生化分析仪内,仪器内光学检测系统启动,获取联检卡信号值;仪器内分析系统自动识别测试卡类别,并与配套id卡内信息配准;配准成功后,提示进入加样检测,完成样本测试;配准失败提示id卡信息与检测卡不符,提示操作者存在测试异常情况。
[0073]
在具体实施过程中,针对血脂血糖测试卡、肝功能测试卡、肾功能测试卡、代谢测试卡、献血筛查测试卡进行识别,利用光信号发射-采集装置,获取干式生化设备及其配套测试卡前3个孔信号序列si(t),其中iε{血脂血糖测试卡,肝功能测试卡,肾功能测试卡,代谢测试卡,献血筛查测试卡},t为信号值;构建i中试纸卡3维散点图,其中测试卡数据量》50;模糊c均值聚类获取各项目三维空间中心点,计算各类别中心点距离;获取中心点距离位置平面函数f,以此平面为三维空间判别模板,将模板存储于id卡内;将待测测试卡插入仪器,仪器内发射-采集装置获取试剂卡前3个内孔信号序列;将信号序列与id卡内模板进行配准,获取信号序列类别即待测试剂卡项目类别;将配准得到的类别与id卡内固有类别进行配准,一致则说明测试卡正确,返回配准结果。
[0074]
可见,该系统是不依赖二维码的可进行测试卡项目识别的便携式干式生化分析系统,可利用配套测试卡信号特征即可完成测试卡检测项目识别,无需添加扫码装置;识别信息可与id卡存储信息进行校验,防止由操作失误引起的异常测试情况,提高检测有效性。
[0075]
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1