一种基于大数据流批一体化处理系统及其工作方法与流程
本技术涉及大数据领域,具体涉及一种基于大数据流批一体化处理系统及其工作方法。
背景技术:
1、在信息技术高速发展的今天,各个行业几乎都与数字化接轨,我们也迎来了数字经济时代。而数字的时代也意味着数据的时代,随着数字时代深入发展,发展过程中所产生数据的种类成倍增长,数据的量级更是成指数级增长,为了利用这些数据更好的推动社会发展,就需要对这些数据进行处理、存储、分析。然而数据的规模对数据存储、处理都带来了一定程度的挑战。
2、大数据行业刚兴起时数据处理存储,大都依赖hdfs(hadoop distributed filesystem,分布式文件系统)与mapreduce(分布式运算程序的编程框架),数据处理的形式以批处理为主。随着行业的发展,并结合应用实际,对于数据的处理形式已经不限于批处理,而是引入了新的数据处理思路即流处理,当下流行的流处理框架(如spark-streaming以及flink)都是一些比较成熟的流处理框架。数据存储也由单一关系型数据库,演化出nosql数据库、键值存储数据库、对象存储数据库以及时序数据库等等。如今数据来源广泛,形式多样,有效的结合批处理与流处理的方法,才能够满足日益增长的需求,
3、未来随着社会发展,将会产生更多数据,而单靠这些数据的表象我们无法发现其中蕴藏着的重要信息,只有通过分析建模对数据进行处理才可以得到我们想要的结果,因此需要一个大数据系统设计实现的模型,来实现这些数据的处理分析,进一步发挥这些数据资产的作用,为社会发展赋能。基于这个模型,可以迅速搭建起一个可靠的大数据存储、处理、可视化的系统,通过这个系统模型可以融合处理相关领域数据,也可以动态扩展数据处理算法,同时满足实时数据处理及历史数据的处理,将系统功能和数据作用发挥到极致。
4、由此,本技术提出一种基于大数据流批一体化处理系统及其工作方法,可以利用此方法设计实现相关领域的大数据存储处理系统,便于数据拥有者实现自己的数据决策中心。
技术实现思路
1、本技术的目的在于提供一种基于大数据流批一体化处理系统及其工作方法,解决了现有技术中对大数据的流处理与批处理无法有效结合的问题,对数据收集、处理、存储以及展示流程进行设计优化拓展,使得大数据应用系统开发更加规范快捷。
2、本技术通过下述技术方案实现:
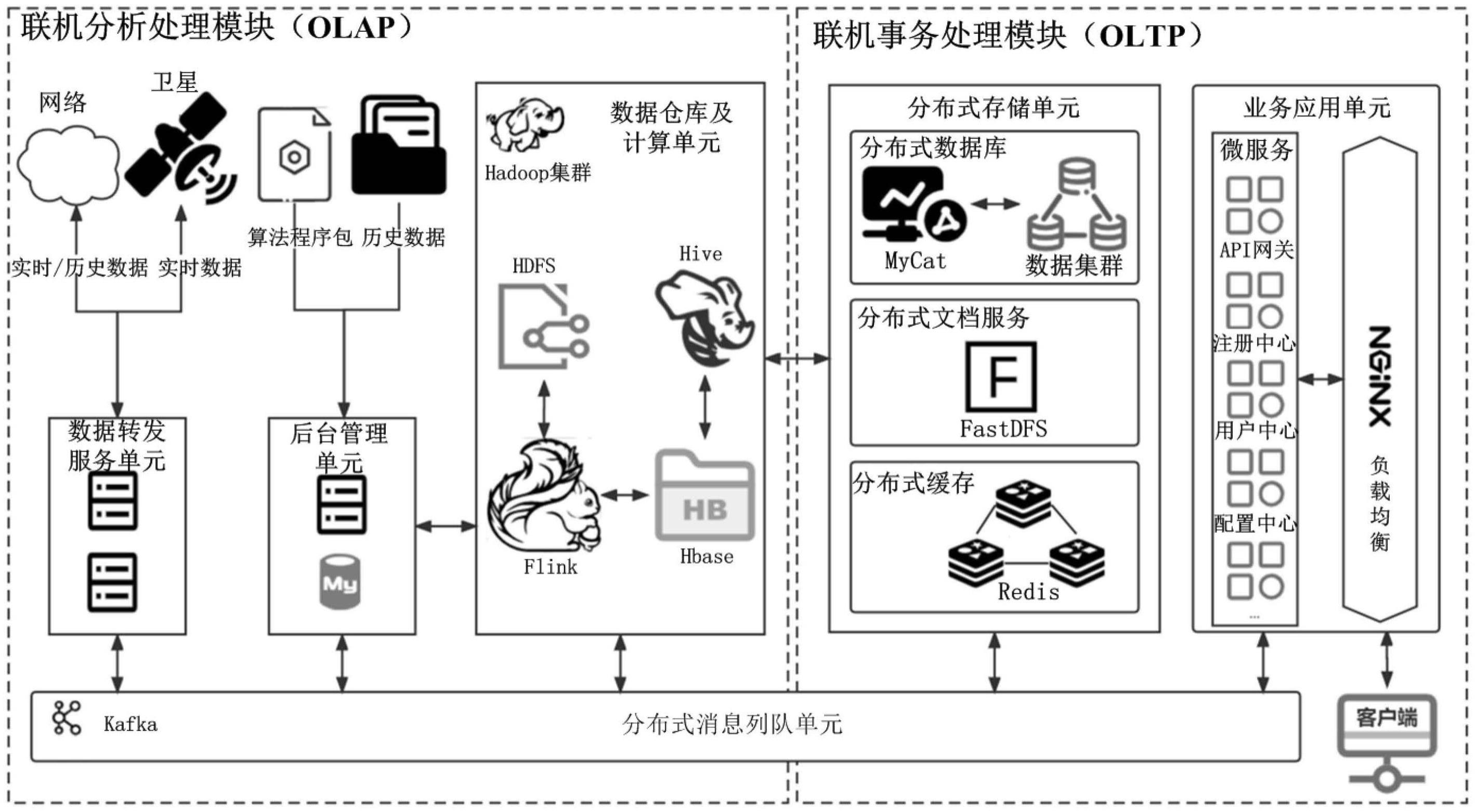
3、第一方面,本技术提供一种基于大数据流批一体化处理系统,包括用于后端处理数据的联机分析处理模块olap以及用于前端服务的联机事务处理模块oltp,所述联机分析处理模块olap与联机事务处理模块oltp相互连接;所述联机分析处理模块olap包括数据转发服务单元、后台管理单元和数据仓库及计算单元,所述联机事务处理模块oltp包括分布式存储单元、业务应用单元以及客户端;
4、所述数据转发服务单元、后台管理单元、数据仓库及计算单元、分布式存储单元以及业务应用单元通过分布式消息列队单元相互通信连接,且所述数据仓库及计算单元分别与后台管理单元通信以及分布式存储单元通信连接;
5、所述数据转发服务单元用于获取外部系统和业务应用单元传输的待处理数据,并将待处理数据传输接入分布式消息列队单元中,所述待处理数据为流数据,所述流数据用于表征实时数据;
6、所述后台管理单元用于配置历史数据、数据处理算法以及数据处理参数,将历史数据以及数据处理算法直接传输至数据仓库及计算单元中,以实现数据以及数据处理算法的动态扩展;并将数据处理参数通过分布式消息列队单元下发至数据仓库及计算单元,以实现数据处理参数的动态配置;获取数据仓库及计算单元对数据的分析结果,并将分析结果可视化;
7、所述数据仓库及计算单元用于获取分布式消息列队单元中的待处理数据以及数据处理参数,结合后台管理单元下发的数据处理算法对待处理数据进行流处理分析,得到流数据分析结果;以及获取数据仓库及计算单元中存储的历史数据,根据数据处理参数以及数据处理算法对历史数据进行批处理分析,得到批数据分析结果;所述流数据分析结果以及批数据分析结果共同作为分析结果,且将分析结果传输至后台管理单元以及分布式存储单元中;
8、所述分布式存储单元用于存储分析结果,并将该分析结果通过分布式存储单元传输至业务应用单元;
9、所述业务应用单元用于承载系统业务,将分布式存储单元中的数据分析结果传输至客户端。
10、在一种可能的实施方式中,获取外部系统和业务应用单元传输的待处理数据,包括:通过网络通信、串口通信以及卫星通信获取外部系统和业务应用单元传输的待处理数据。
11、在一种可能的实施方式中,所述后台管理单元上还设置有mysql数据库,所述后台管理单元响应于人机交互产生的数据处理参数传输至分布式消息列队单元中或者存储于mysql数据库中,待数据仓库及计算单元对待处理数据进行处理时,调度mysql数据库中的数据处理参数进行处理。
12、在一种可能的实施方式中,所述数据仓库及计算单元包括hadoop集群、hbase集群、hive集群以及flink集群;
13、所述hadoop集群利用其分布式文件系统hdfs存储非结构化数据;所述hbase集群存储结构化主题数据;所述flink集群对分布式文件系统hdfs中的非结构化数据、hbase集群中的结构化主题数据以及分布式消息列队单元传输的待处理数据进行分析处理,得到分析结果,并将该分析结果分别存储至后台管理单元的mysql数据库中或者分布式存储单元中;所述hive集群对hbase集群中的结构化主题数据进行分析处理,得到分析结果,并将该分析结果分别存储至后台管理单元的mysql数据库中或者分布式存储单元中。
14、在一种可能的实施方式中,所述分布式消息列队单元采用kafka集群,以实现分布式消息队列、满足数据高吞吐和完成数据缓冲。
15、在一种可能的实施方式中,所述分布式存储单元包括分布式数据库、fastdfs集群以及redis集群;所述分布式数据库包括mycat集群以及mysql集群,以实现分布式数据库以及高并发提供扩充支持。
16、在一种可能的实施方式中,所述业务应用单元包括微服务子单元以及负载均衡单元,所述负载均衡单元用于实现多用户的负载均衡访问,所述微服务子单元用于承载系统业务,并将访问获取的数据传输给客户端。
17、第二方面,本技术提供一种基于大数据流批一体化处理系统的工作方法,包括流数据处理流程以及批数据处理流程;
18、所述流数据处理流程包括:
19、通过后台管理单元下发数据处理算法至数据仓库及计算单元,通过数据转发服务单元获取待处理流数据,并将所述待处理流数据传输至分布式消息列队单元中进行列队,同时后台管理单元下发与待处理流数据对应的数据处理参数至分布式消息列队单元中进行列队;
20、通过数据仓库及计算单元获取待处理流数据、数据处理算法以及数据处理参数,结合数据处理算法以及数据处理参数,并通过数据仓库及计算单元中的flink集群对待处理流数据进行分析处理,得到待处理流数据对应的结构化主题数据以及流数据分析结果;
21、将该结构化主题数据存储至hbase集群中,将流数据分析结果分别传输至后台管理单元的mysql数据库以及分布式存储单元中;
22、通过分布式存储单元将流数据分析结果传输至业务应用单元,并由业务应用单元将流数据分析结果转发至客户端进行可视化,完成流数据的处理;
23、所述批数据处理流程包括:
24、通过后台管理单元下发历史数据以及数据处理算法至数据仓库及计算单元,并通过后台管理单元下发数据处理参数至mysql数据库中;
25、通过flink集群读取hbase集群以及分布式文件系统hdfs中的历史数据,或者通过flink集群获取后台管理单元下发的历史数据,并结合数据处理算法以及后台管理单元的mysql数据库中的数据处理参数,对历史数据进行处理分析,得到批数据分析结果,并将批数据分析结果存储至分布式存储单元或mysql数据库中;
26、通过分布式存储单元将批数据分析结果传输至业务应用单元,并由业务应用单元将批数据分析结果转发至客户端可视化,或通过后台管理单元将mysql数据库中的批数据分析结果可视化,完成批数据的处理。
27、在一种可能的实施方式中,通过数据仓库及计算单元中的flink集群对待处理流数据进行分析处理,包括:
28、当flink集群首次工作时,通过flink集群读取后台管理单元的mysql数据库中的数据处理默认参数;
29、根据数据处理默认参数,对待处理流数据进行分析处理;
30、当需要改变数据处理参数时,通过后台管理单元将动态数据处理参数下发至分布式消息列队单元中,并通过分布式消息列队单元将动态数据处理参数转发至数据仓库及计算单元中,以实现动态参数配置。
31、在一种可能的实施方式中,还包括:将批数据转换为流数据,并通过flink集群对原有的流数据以及转换后的流数据进行融合分析处理。
32、本技术提供的一种基于大数据流批一体化处理系统,通过大数据存储处理框架,实现了大数据的流处理、批处理、融合处理,同时实现了处理数据与处理算法的动态扩充,并结合olap、oltp以及微服务等系统设计思想对整个系统设计进行优化,从而达到大数据系统易于实现、功能完善以及扩展性高的效果。
- 还没有人留言评论。精彩留言会获得点赞!