使用大型语言模型的自然语言处理应用的制作方法
背景技术:
1、自然语言处理(nlp)技术的应用和实现通常用于各种任务,例如语言生成或分析、语法和用法检查、或内容总结,仅列举几例。为了提供高度准确的nlp结果,使用大型语言模型可能是有利的,该模型已经用非常大的词汇和语法的训练集被训练。虽然大型语言模型(llm)可以是用于实现各种各样的复杂nlp算法的一个非常强大的通用工具,但这种大型模型计算成本很高,有时需要许多多处理器服务器或工作站来加载和执行基本计算,使这些模型远离了许多潜在用户。虽然像云提供商这样的实体可以托管一个llm供各种不同的用户或实体使用,但这样的实现可能是次优的。例如,对于独特的用例或操作,语言模型可能需要定制——这需要用一些与该用例或操作特别相关的额外数据来训练该模型。即使对大型云提供商来说,这些模型的规模和计算费用也降低了为每个此类用例或操作训练和托管不同大型模型的可行性。
技术实现思路
技术特征:
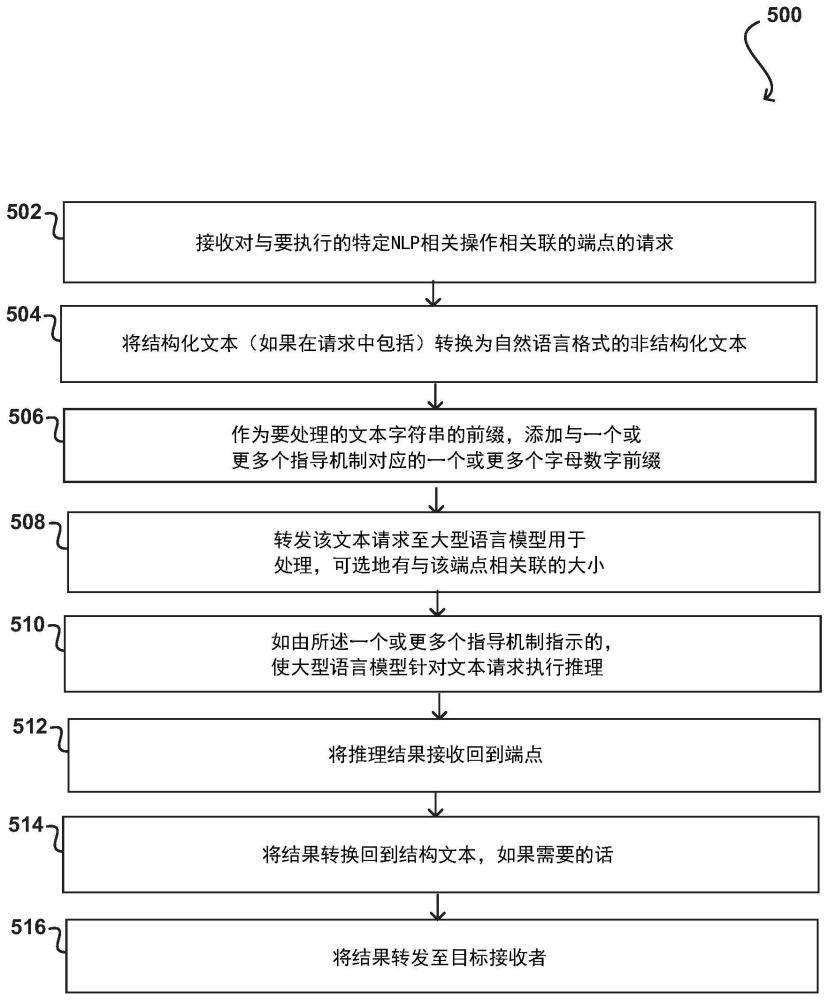
1.一种方法,包括:
2.如权利要求1所述的方法,其中所述端点是多个端点中的一个,其中所述多个端点中的各个端点与相应的任务相关联,并且其中大型语言模型没有被训练为至少执行与所述多个端点相关联的任务的子集。
3.如权利要求2所述的方法,进一步包括:
4.如权利要求1所述的方法,其中所述一个或更多个指导机制包括提示令牌,其指示将为所述任务执行的推理类型或将为所述任务返回的结果类型中的至少一个。
5.如权利要求1所述的方法,其中所述一个或更多个指导机制包括指示要参考的一个或更多个数据集的检索集标签,其中所述结果至少基于使用所述语言模型处理至少基于所述检索集标签从所述一个或更多个数据集中检索的数据来进一步生成。
6.如权利要求1所述的方法,其中所述一个或更多个指导机制包括适配器权重,用于在所述处理之前修改所述语言模型的网络权重或层结构中的至少一个。
7.如权利要求1所述的方法,进一步包括:
8.如权利要求1所述的方法,其中所述端点是多个端点中的一个,并且所述方法进一步包括:
9.如权利要求1所述的方法,其中所述语言模型与两个或更多个不同大小的模型实例相关联,并且其中所述端点针对于所述两个或更多个模型实例中的特定模型实例进行训练以执行所述任务。
10.如权利要求1所述的方法,其中所述自然语言文本字符串是根据用于配置所述端点的一个或更多个编排规则从所述请求中获得的。
11.一种处理器,包括:
12.如权利要求11所述的处理器,其中所述端点是多个端点中的一个,其中所述多个端点中的各个端点与相应的任务相关联,并且其中所述大型语言模型没有被训练为至少执行所述多个端点的任务的子集。
13.如权利要求12所述的处理器,其中所述操作进一步包括:为所述多个端点中的各个端点选择相应组一个或更多个引导机制,用于所述各个端点的相应任务。
14.如权利要求12所述的处理器,其中所述操作进一步包括:
15.如权利要求11所述的处理器,其中所述大型语言模型与两个或更多个不同大小的模型实例相关联,并且其中所述端点针对于所述两个或更多个模型实例中的特定模型实例被训练以执行所述任务。
16.如权利要求11所述的处理器,其中所述处理器被包含在以下的至少一个中:
17.一种系统,包括:
18.如权利要求17所述的系统,其中所述一个或更多个指导机制包括提示令牌、检索标签集或适配器权重中的至少一个。
19.如权利要求17所述的系统,其中所述一个或更多个指导机制被用来执行以下的至少一个:
20.如权利要求17所述的系统,其中所述系统包括以下中的至少一个:
技术总结
本公开涉及使用大型语言模型的自然语言处理应用。本文提出的方法可以提供使用大型模型的特定类型的任务的执行,而不需要重新训练模型。自定义端点可以针对特定类型的任务进行训练,如可以通过一个或更多个指导机制的规范来指示的。指导机制可以被添加到请求中或与请求一起被使用,以指导模型执行与文本字符串有关的任务类型。接收到这种请求的端点可以执行以模型要求的格式获得请求所需的任何编排,并且可以把指导机制添加到请求,例如,把一个或更多个文本字符串(或文本前缀)添加到文本格式的请求前面。接收到此字符串的模型可以根据指导机制处理文本。这样的方法可以允许各种任务由单个模型来执行。
技术研发人员:R·利里,J·科恩
受保护的技术使用者:辉达公司
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!