一种文件的功效词提取聚合方法、系统、终端及介质与流程
本发明涉及词句提取方法的领域,尤其是涉及一种文件的功效词提取聚合方法、系统、终端及介质。
背景技术:
1、通过对专利文件进行检索、阅读和分析,是用户快速了解现有技术的一个途径,对专利文件进行检索,能够找到同行业的相关专利,对相关专利进行阅读和分析,能够使企业或个人减少出现侵权的行为,若企业或个人想将相似技术进行专利申请,对相关专利的阅读和分析,也能够帮助企业或个人对提高专利专利申请的授权概率。
2、专利文件指在申请专利时所需使用的专用文体。其中,发明专利和实用新型专利的专利文件中包含的内容有权利要求书、说明书及摘要,实用新型专利还应当有说明书附图和摘要附图,发明专利必要的时候,应当有说明书附图和摘要附图。
3、通常对一篇专利文件进行分析时,需要通篇阅读整篇专利文件,以提取用户需要的有用信息,比如对专利的优点进行分析等,每年专利高速增长,专利的内容也愈加复杂,有些文本字数也非常庞大,不方便整篇通读,基于以上原因,在专利数量多或/和专利篇幅较长时,用户阅读的效率不高。
技术实现思路
1、为了辅助用户进行文件的阅读和分析,本申请提供一种文件的功效词提取聚合方法、系统、终端及介质。
2、第一方面,本申请提供的一种文件的功效词提取聚合方法采用如下的技术方案:
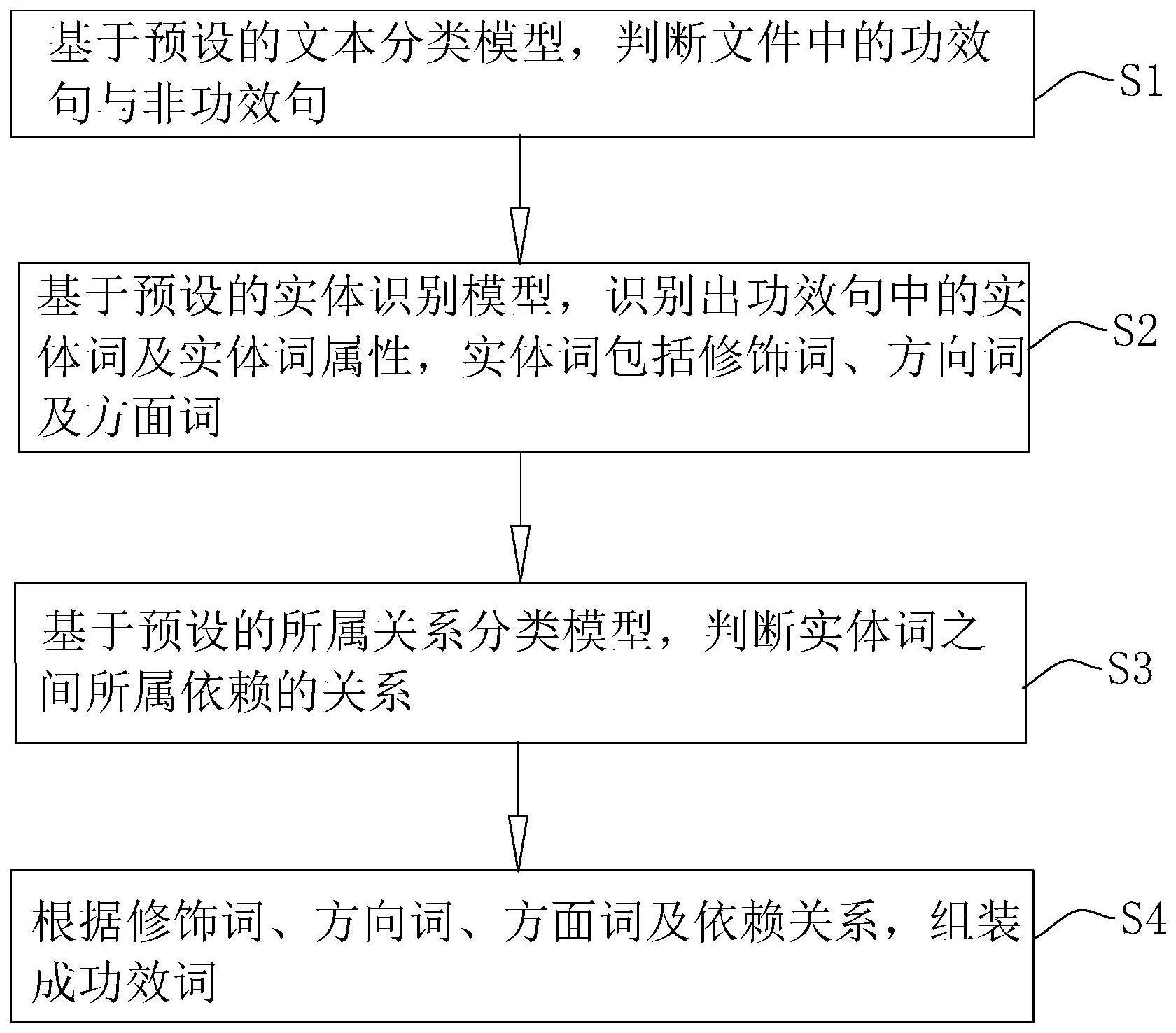
3、一种文件的功效词提取聚合方法,包括以下步骤:基于预设的文本分类模型,判断文件中的功效句与非功效句;基于预设的实体识别模型,识别出所述功效句中的实体词及实体词属性,所述实体词包括修饰词、方向词及方面词;基于预设的所属关系分类模型,判断所述实体词之间所属依赖的关系;根据所述修饰词、所述方向词、所述方面词及所述关系,组装成功效词。
4、通过采用上述技术方案,通过文本分类模型判断出专利文件中的功效句,通过实体识别模型,判断出功效句中的修饰词、方向词及方面词,通过所属关系分类模型,识别出多个实体词相互所属依赖的关系,输出修饰词、方向词及方面词及所属依赖的关系,并组装为功效词。
5、本申请通过智能模型的识别,能从海量文本中生成具体的功效词,尤其是对于专利文件,可以快速定位和抽取到专利文件中功效部分,并按照成分组装成简短的词句,呈现在用户的面前,辅助用户进行阅读和分析,提升了阅读的效率,便于高效分析专利。
6、优选的,所述基于预设的文本分类模型,判断文件中的功效句与非功效句中,包括:响应于预设的功效句样本与预设的非功效句样本输入到所述文本分类模型中,进行所述文本分类模型的模型训练。
7、优选的,所述基于预设的文本分类模型,判断文件中的功效句与非功效句中,包括:将目标文件的文本按照句号或/和分号切割成多个分句;获取输入至所述文本分类模型中所述分句,判断所述功效句与所述非功效句。
8、优选的,所述基于预设的实体识别模型,标记所述功效句中的修饰词、方向词及方面词中,包括:获取修饰词属性、方向词属性及方面词属性的标注数据;响应于实体词抽取指令,基于实体识别模型,抽取所述实体词及标注所述实体词的属性。
9、优选的,所述获取修饰词属性、方向词属性及方面词属性的标注数据中,包括:所述标注数据的方式为bio序列标注形式。
10、优选的,所述基于预设的所属关系分类模型,识别所述实体词之间所属依赖的关系,包括:将所述实体识别模型识别到的所述实体词,以所述方面词为中心两两打标记;基于所述所属关系分类模型,判断两个打过标记的所述实体词是否属于同组,获得所述实体词之间的所属关系关系。
11、优选的,所述响应于所属关系判断指令,判断实体词之间的所属关系中,包括:将同组的所述实体词按预设的顺序进行组装,得到所述功效词。
12、第二方面,本申请公开一种文件的功效词提取聚合系统,采用了上述文件的功效词提取聚合方法,包括:文本分类模块,用于基于预设的文本分类模型,判断文件中的功效句与非功效句;实体词识别模块,用于基于预设的实体识别模型,识别出所述功效句中的实体词及实体词属性,所述实体词包括修饰词、方向词及方面词;所属关系分类模块,用于基于预设的所属关系分类模型,判断所述实体词之间所属依赖的关系;功效词组装模块,用于根据所述修饰词、所述方向词、所述方面词及所述关系,组装成功效词。
13、通过采用上述技术方案,通过文本分类模块中的文本分类模型判断出专利文件中的功效句,通过实体词识别模块中的实体识别模型,判断出功效句中的修饰词、方向词及方面词,通过所属关系分类模块中的所属关系分类模型,识别出多个实体词相互所属依赖的关系,根据实体词以及其所属依赖关系,通过功效词组装模块组装为功效词。
14、本申请通过智能模型的识别,能从海量文本中生成具体的功效词,尤其是对于专利文件,可以快速定位和抽取到专利文件中功效部分,并按照成分组装成简短的词句,呈现在用户的面前,辅助用户进行阅读和分析,提升了阅读的效率,便于高效分析专利。
15、第三方面,本申请公开一种终端设备,包括存储器、处理器以及存储在存储器中并能够在处理器上运行的计算机程序,所述处理器加载并执行计算机程序时,采用了上述的文件的功效词提取聚合方法。
16、通过采用上述技术方案,通过上述的文件的功效词提取聚合方法生成计算机程序,并存储于存储器中,以被处理器加载并执行,从而,根据存储器及处理器制作终端设备,方便用户使用。
17、第四方面,本申请公开一种计算机可读存储介质,采用如下的技术方案:一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序被处理器加载并执行时,采用了上述的文件的功效词提取聚合方法。
18、通过采用上述技术方案,通过上述的文件的功效词提取聚合方法生成计算机程序,并存储于计算机可读存储介质中,以被处理器加载并执行,通过计算机可读存储介质,方便计算机程序的可读及存储。
技术特征:
1.一种文件的功效词提取聚合方法,其特征在于,包括:
2.根据权利要求1所述的文件的功效词提取聚合方法,其特征在于,所述基于预设的文本分类模型,判断文件中的功效句与非功效句中,包括:
3.根据权利要求1所述的文件的功效词提取聚合方法,其特征在于,所述基于预设的文本分类模型,判断文件中的功效句与非功效句中,包括:
4.根据权利要求1所述的文件的功效词提取聚合方法,其特征在于,所述基于预设的实体识别模型,标记所述功效句中的修饰词、方向词及方面词中,包括:
5.根据权利要求4所述的文件的功效词提取聚合方法,其特征在于,所述获取修饰词属性、方向词属性及方面词属性的标注数据中,包括:所述标注数据的方式为bio序列标注形式。
6.根据权利要求1-5任一项所述的文件的功效词提取聚合方法,其特征在于,所述基于预设的所属关系分类模型,识别所述实体词之间所属依赖的关系,包括:
7.根据权利要求6所述的文件的功效词提取聚合方法,其特征在于,所述响应于所属关系判断指令,判断实体词之间的所属关系中,包括:
8.一种文件的功效词提取聚合系统,其特征在于,使用了权利要求1-7任一项所述的文件的功效词提取聚合方法,包括:
9.一种终端设备,包括存储器、处理器以及存储在存储器中并能够在处理器上运行的计算机程序,其特征在于,所述处理器加载并执行计算机程序时,采用了权利要求1-7任一项所述的文件的功效词提取聚合方法。
10.一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,其特征在于,所述计算机程序被处理器加载并执行时,采用了权利要求1-7任一项所述的文件的功效词提取聚合方法。
技术总结
本发明涉及词句提取方法的领域,尤其是涉及一种文件的功效词提取聚合方法、系统、终端及介质。其中,一种文件的功效词提取聚合方法包括:基于预设的文本分类模型,判断文件中的功效句与非功效句;基于预设的实体识别模型,识别出所述功效句中的实体词及实体词属性,所述实体词包括修饰词、方向词及方面词;基于预设的所属关系分类模型,判断所述实体词之间所属依赖的关系;根据所述修饰词、所述方向词、所述方面词及所述关系,组装成功效词。本申请具有辅助用户进行文件的阅读和分析的效果。
技术研发人员:李阳,蔡子哲,张林,黄威威
受保护的技术使用者:企知道网络技术有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!