为ML服务和模型调度异构资源的制作方法
本发明的实施例总体上涉及机器学习(ml)服务和模型的调度。更具体地,本发明的实施例涉及为ml服务和模型调度异构资源。
背景技术:
1、深度神经网络(dnn)的研究因其在不同应用场景中的最先进性能而获得了越来越大的推动力。每年,都会为对在准确性、延迟减少、隐私保护、能源效率等方面的改进要求更加严格的新兴智能服务提出大量新的dnn架构。大多数dnn专注于提高准确度,但会大大增加模型复杂度——当前最先进的神经网络模型(比如inceptionv4和resnet-50)的深度可以达到数十层甚至数百层从而在相关任务的准确度上优于以前的神经网络模型。单层可能需要多达数百万次矩阵乘法。这种计算对在计算资源有限的边缘设备上部署这些dnn模型提出了挑战。
2、边缘计算通常是指在更接近网络“边缘”或“边缘”集合的位置处实施和使用计算和资源。这种布置的目的是减少应用程序和网络延迟,提高服务能力,并提高对安全或数据隐私要求的符合性。可以执行边缘计算操作的部件(“边缘节点”)可以驻留在网络边缘的位置处(例如,在高性能计算数据中心或云设施中;在指定的边缘节点服务器、企业服务器、路边服务器、消费类设备或提供或消费边缘服务的物联网(iot)设备中)。
3、通常,ml应用程序/服务需要严格的延迟,当ml服务由边缘设备提供时,这会导致普遍存在的多对多问题(多应用程序与异构边缘设备上的多模型)。ai驱动的应用程序/服务需要将多模型分配给边缘设备的异构资源,以实现低延迟。
技术实现思路
技术特征:
1.一种计算机实施的方法,包括:
2.如权利要求1所述的方法,进一步包括:
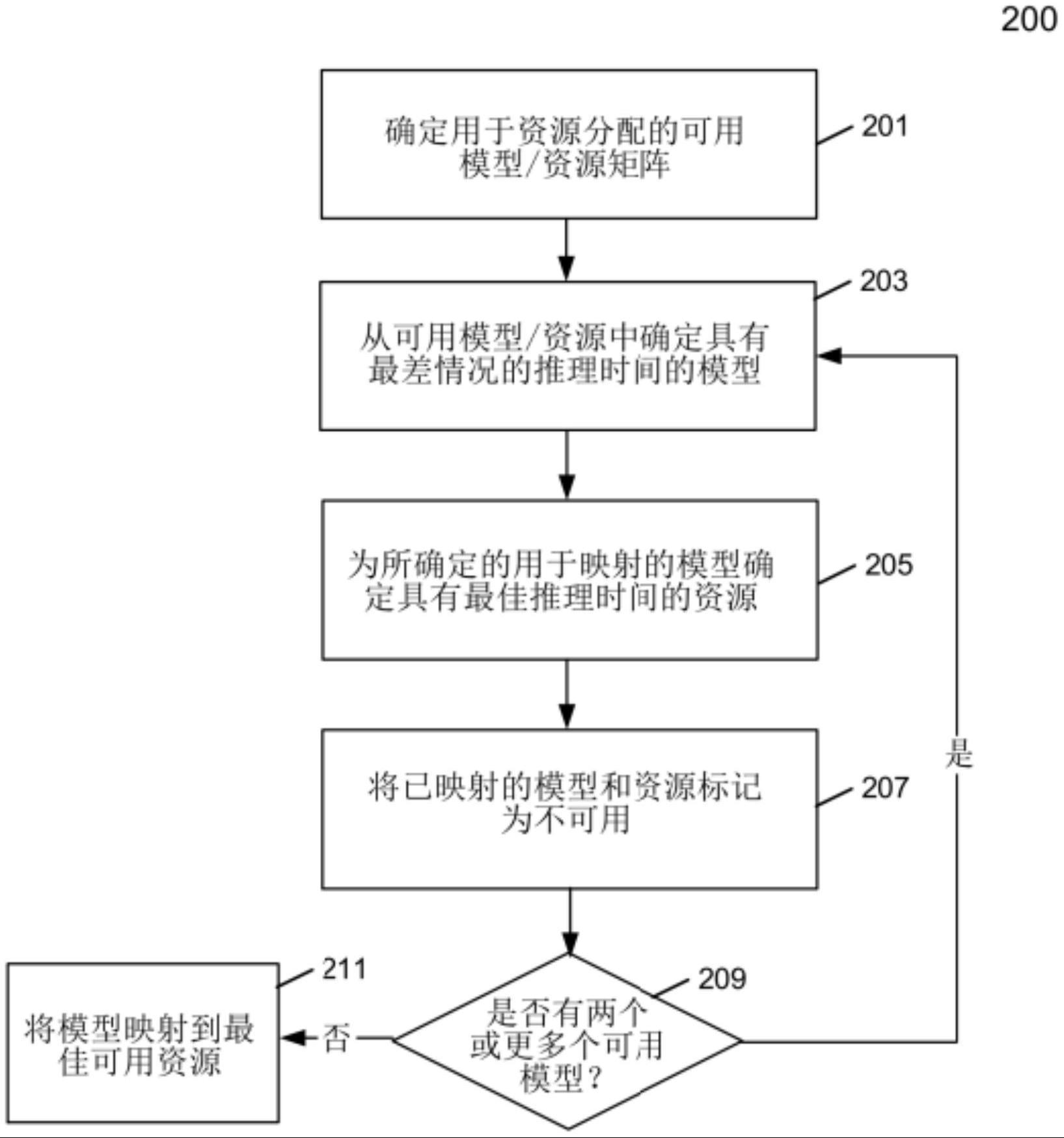
3.如权利要求1所述的方法,其中,应用服务特定的模型优先调度方案包括:应用模型优先调度方案,以将所述多个ml模型限制到特定的ml服务,并且其中,应用多服务模型优先调度方案包括:应用所述模型优先调度方案,以将所述多个ml模型限制到多个ml服务。
4.如权利要求3所述的方法,其中,应用所述模型优先调度方案包括:
5.如权利要求1所述的方法,其中,应用服务特定的硬件优先调度方案包括:应用硬件优先调度方案,以将所述多个ml模型限制到特定的ml服务,并且其中,应用多服务硬件优先调度方案包括:应用所述硬件优先调度方案,以将所述多个ml模型限制到多个服务。
6.如权利要求5所述的方法,其中,应用所述硬件优先调度方案包括:
7.如权利要求1所述的方法,其中,所述多个处理资源包括中央处理单元(cpu)、图形处理单元(gpu)或视觉处理单元(vpu)。
8.如权利要求1所述的方法,其中,所述计算设备是边缘设备、智能电话或物联网(iot)设备。
9.如权利要求1所述的方法,其中,多个ml服务包括人脸检测服务、人员检测服务或车辆检测服务。
10.如权利要求1所述的方法,其中,人脸检测包括年龄/性别识别、情绪识别、人脸关键点、头部姿势估计或人员属性识别,其中,人员检测包括人员属性识别和人员重新识别,其中,车辆检测包括车牌照识别和车辆属性识别ml模型。
11.如权利要求1所述的方法,其中,默认映射按照cpu、gpu和vpu的默认顺序、根据其可用性为所述多个ml模型中的每一个ml模型分配所述多个处理资源。
12.一种其中存储有指令的非暂态机器可读介质,所述指令当由处理器执行时使所述处理器执行操作,所述操作包括:
13.如权利要求12所述的非暂态机器可读介质,其中,所述操作进一步包括:
14.如权利要求12所述的非暂态机器可读介质,其中,应用服务特定的模型优先调度方案包括:应用模型优先调度方案,以将所述多个ml模型限制到特定的ml服务,并且其中,应用多服务模型优先调度方案包括:应用所述模型优先调度方案,以将所述多个ml模型限制到多个ml服务。
15.如权利要求14所述的非暂态机器可读介质,其中,应用所述模型优先调度方案包括:
16.如权利要求12所述的非暂态机器可读介质,其中,应用服务特定的硬件优先调度方案包括:应用硬件优先调度方案,以将所述多个ml模型限制到特定的ml服务,并且其中,应用多服务硬件优先调度方案包括:应用所述硬件优先调度方案,以将所述多个ml模型限制到多个ml服务。
17.如权利要求16所述的非暂态机器可读介质,其中,应用所述硬件优先调度方案包括:
18.一种数据处理系统,包括:
19.如权利要求18所述的数据处理系统,其中,所述操作进一步包括:
20.如权利要求18所述的数据处理系统,其中,应用服务特定的模型优先调度方案包括:应用模型优先调度方案,以将所述多个ml模型限制到特定的ml服务,并且其中,应用多服务模型优先调度方案包括:应用所述模型优先调度方案,以将所述多个ml模型限制到多个ml服务。
技术总结
一种确定与由计算设备的多个处理资源执行多个机器学习(ML)模型所花费的推理时间相对应的时序矩阵的系统。所述处理资源至少包括第一类型和第二类型的处理资源。所述系统应用服务特定的模型优先调度方案或服务特定的硬件优先调度方案以获得对应的服务特定映射。所述系统从所述对应的服务特定映射中确定最佳映射。所述系统根据所述最佳映射将每个ML模型调度到所述处理资源中的对应处理资源。所述系统使用对应的映射处理资源执行所述ML模型。
技术研发人员:寇浩锋,黄岱,张满江,李幸,王磊,郑惠猛,陈振,程瑞昌
受保护的技术使用者:百度时代网络技术(北京)有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!