减少生成语言模型的偏差的制作方法
背景技术:
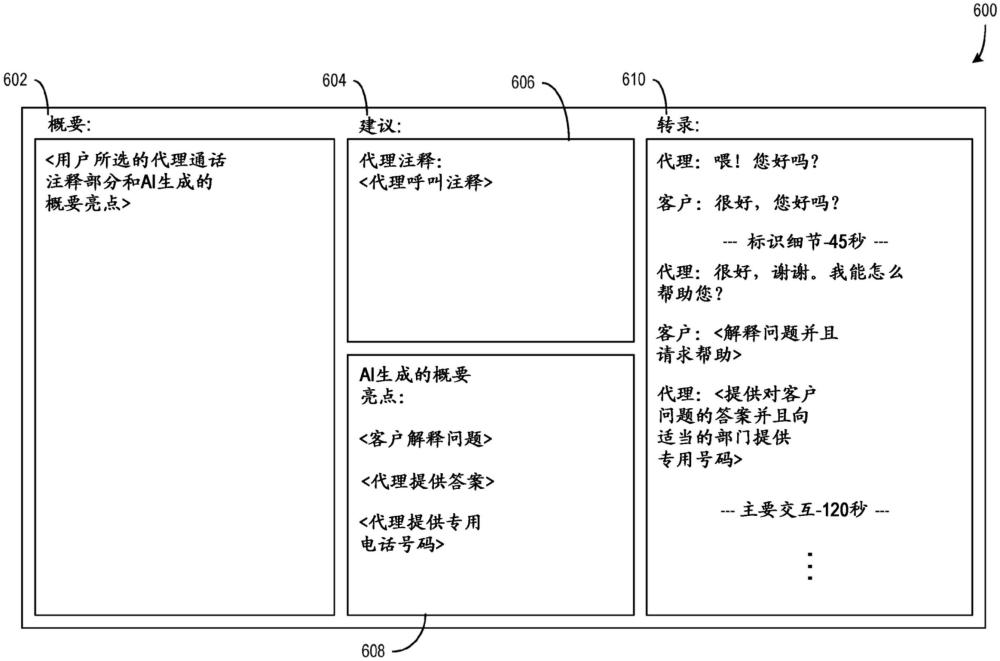
1、客户关系管理(crm)对话和其他相关的多方通信是利润丰厚的分析目标。在某些域,报告的起草和/或呼叫和其他对话的概括需要代理的显著时间和精力,否则他们将能够与更多客户进行对话或以其他方式提供其他服务。现有的文本概括方法旨在总结纯文本和/或单方文本(诸如新闻文章),但这些解决方案在与这样的多方通信一起使用时存在不足。准确且有效地概括多方对话提出了重大挑战。
2、另外,经训练以生成文本概要的模型有时会基于训练数据中特定于域的词或短语的使用或以其他方式与模型的稍后使用不相关而产生偏差(bias)。这样的偏差可能会抑制这样的模型的准确性和灵活性。减少或消除来自模型的输出中的这样的偏差代表着对现有技术的重大改进。
技术实现思路
1、提供本
技术实现要素:
是为了以简化的形式介绍一些概念的选择,这些概念将在下面的具体实施方式中进一步描述。本发明内容不旨在标识所要求保护的主题的关键特征或基本特征,也不旨在被用作确定所要求保护的主题的范围的帮助。
2、一种用于减少由生成语言模型生成的输出中的训练偏差的计算机化方法被描述。与通信相关联的通信段由生成语言模型的至少一个处理器获得。与通信段相关联的输出值由生成语言模型生成。输出值被映射到与生成语言模型相关联的训练偏差值集合,并且基于输出值到该训练偏差值集合中的训练偏差值的映射,备选输出值被生成。备选输出值在针对通信段的生成的段输出中被使用。
技术特征:
1.一种用于减少由生成语言模型生成的输出中的训练偏差的系统,所述系统包括:
2.根据权利要求1所述的系统,其中所述通信包括第一方与第二方之间的通信,并且其中所述通信段包括标识哪方是所述通信段的每个部分的源的方身份数据;并且
3.根据权利要求2所述的系统,其中所述计算机程序代码被配置为与所述至少一个处理器一起还使所述至少一个处理器:
4.根据权利要求2至3中任一项所述的系统,其中所述计算机程序代码被配置为与所述至少一个处理器一起还使所述至少一个处理器:
5.根据权利要求1至4中任一项所述的系统,其中所述训练偏差值集合包括以下至少一项:在被用于训练所述生成语言模型的训练数据中高频出现的词,以及被标识为域特定于所述训练数据的域的词,所述训练数据被用于训练所述生成语言模型。
6.根据权利要求5所述的系统,其中所述计算机程序代码被配置为与所述至少一个处理器一起还使所述至少一个处理器:
7.根据权利要求1至6中任一项所述的系统,其中由所述生成语言模型生成与所述通信段相关联的输出值包括:
8.一种用于减少由生成语言模型生成的输出中的训练偏差的计算机化方法,所述计算机化方法包括:
9.根据权利要求8所述的计算机化方法,其中所述通信包括第一方与第二方之间的通信,并且其中所述通信段包括标识哪方是所述通信段的每个部分的源的方身份数据;以及
10.根据权利要求9所述的计算机化方法,还包括:
11.根据权利要求9至10中任一项所述的计算机化方法,还包括:
12.根据权利要求8至11中任一项所述的计算机化方法,其中所述训练偏差值集合包括以下至少一项:在被用于训练所述生成语言模型的训练数据中高频出现的词,以及被标识为特定于所述训练数据的域的词,所述训练数据被用于训练所述生成语言模型。
13.根据权利要求12所述的计算机化方法,还包括生成训练偏差词集合,其中所述训练偏差词集合的所述生成包括:
14.根据权利要求8至13中任一项所述的计算机化方法,其中由所述生成语言模型的所述至少一个处理器生成与所述通信段相关联的输出值包括:
15.一种或多种计算机存储介质,具有计算机可执行指令,所述计算机可执行指令用于减少由生成语言模型生成的输出中的训练偏差,所述计算机可执行指令在由处理器执行时使所述处理器至少:
技术总结
本文的公开描述了减少由生成语言模型生成的输出中的训练偏差。与通信相关联的通信段由生成语言模型的至少一个处理器获得。与通信段相关联的输出值由生成语言模型生成。输出值被映射到与生成语言模型相关联的训练偏差值集合,并且基于输出值到该训练偏差值集合中的训练偏差值的映射,备选输出值被生成。备选输出值被使用在用于通信段的生成的段输出中。通过减少或消除生成语言模型的训练偏差,由生成语言模型生成的段输出的准确性被提高。
技术研发人员:A·阿赛,Y·库珀,R·罗南,王松,O·戈登博格,S·R·比密斯,E·奥塔斯,毛祎,陈伟柱
受保护的技术使用者:微软技术许可有限责任公司
技术研发日:
技术公布日:2024/1/25
- 还没有人留言评论。精彩留言会获得点赞!