一种基于多模型的稽核检索方法、装置及存储介质与流程
本发明涉及数据稽核,尤其是涉及一种基于多模型的稽核方法、装置及存储介质。
背景技术:
1、目前,证券公司的内部检索主要是依据公司内部的规章制度,对自身进行专业监督自我约束的重要工作,通过加强对公司的控制达到防范经营风险、创造收益的目的。由于证券公司身处高风险的行业,加强内部稽核监督及防范经营风险是证券公司的重要任务。稽核人员在日常的工作中,不仅负责对公司内部制度进行维护与完善,还需要对公司各部门的各项工作及流程进行审计与检查。由于检查事项众多且复杂,各项检查之间的条目、范围、粒度均不一致,因此稽核人员在前期准备工作以及审计检查的过程中会耗费大量的人力进行相关资料的查阅与稽核。而现有稽核方法通常是通过关键字进行匹配,进行文字层面的查找与关联以完成稽核检索,但是现在的稽核检索方法无法全面返回检索结果,导致稽核检索的准确性较低。
技术实现思路
1、本发明提供了一种基于多模型的稽核检索方法、装置及存储介质,以解决现在的稽核检索方法无法全面返回检索结果,导致稽核检索的准确性较低的技术问题。
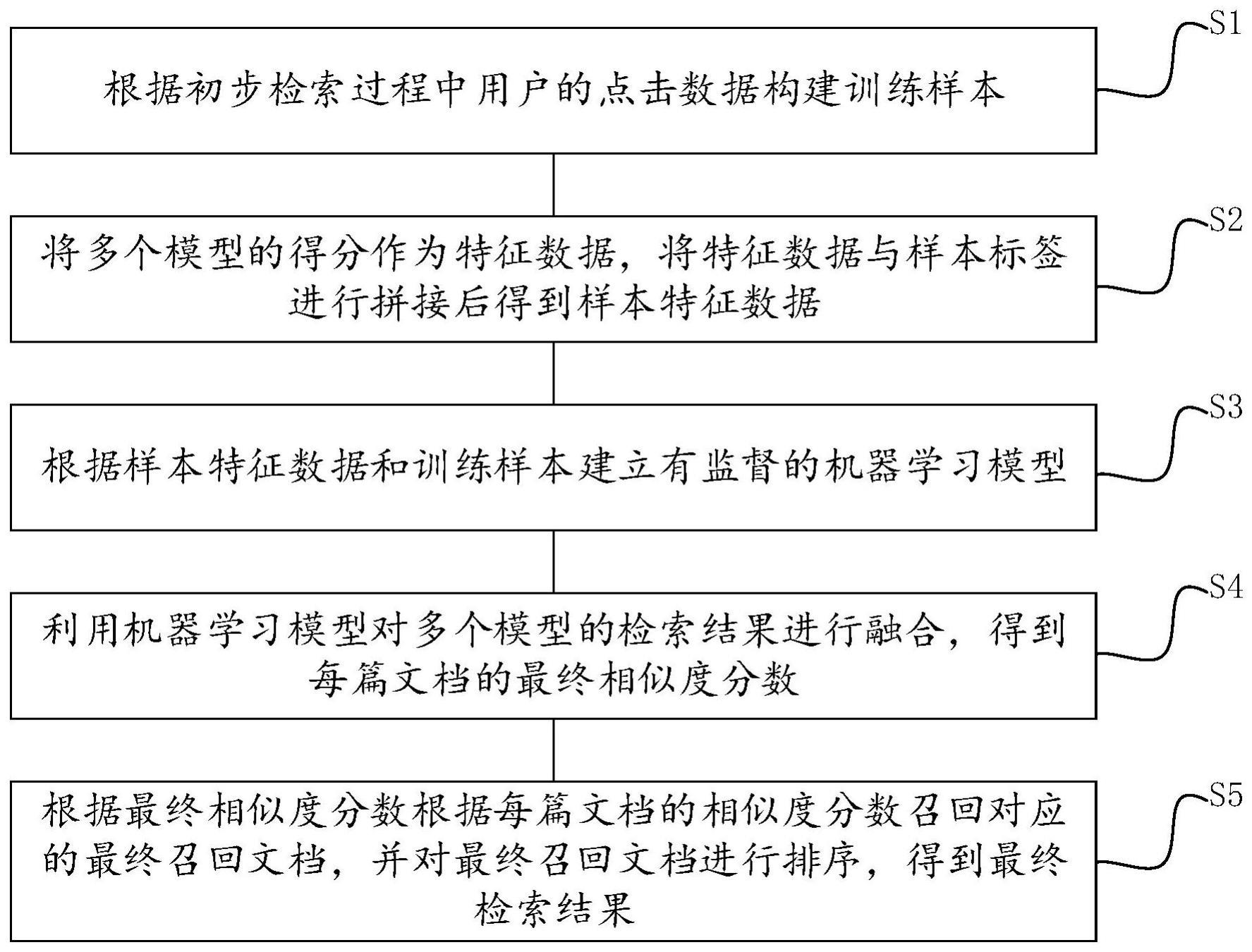
2、本发明的一个实施例提供了一种基于多模型的稽核检索方法,包括:
3、训练样本构建步骤:根据初步检索过程中用户的点击数据构建训练样本;
4、样本特征获取步骤:将多个模型的得分作为特征数据,将所述特征数据与样本标签进行拼接后得到样本特征数据;
5、机器学习模型构建步骤:根据所述样本特征数据和所述训练样本建立有监督的机器学习模型;
6、相似度分数计算步骤:利用所述机器学习模型对多个所述模型的检索结果进行融合,得到每篇文档的最终相似度分数;
7、检索结果获取步骤:根据所述最终相似度分数根据每篇文档的相似度分数召回对应的最终召回文档,并对所述最终召回文档进行排序,得到最终检索结果。
8、进一步的,所述训练样本包括正样本和负样本,所述根据初步检索过程中用户的点击数据构建训练样本,包括:
9、将被用户点击过的数据作为正样本;将向用户曝光过但未被用户点击的数据,以及未向用户曝光的数据合并后作为负样本。
10、进一步的,所述稽核检查方法还包括:
11、检测用户的点击数据的数据量,在所述数据量超过预设阈值时,从生产环境点击日志中合并新的数据流,根据所述新的数据流生成新的训练样本,根据所述新的训练样本进行重新训练,得到更新后的机器学习模型。
12、进一步的,所述检索结果获取步骤,还包括:
13、对查询语句进行意图解析得到解析结果;
14、若所述解析结果包含员工姓名以及具体稽核项目名称,则返回所述员工的基本信息,以及该员工在所述稽核项目下需要被审核的所有流程链接;
15、若所述解析结果包含部门名称以及具体稽核项目名称时,返回所述部门在所述稽核项目下需要被审核的所有流程链接;
16、若所述解析结果中包含具体事件名称,则返回流程名称中包含所述事件名称的所有流程链接。
17、进一步的,所述多个模型包括词袋模型、word2vec模型、l da模型及bert模型。
18、进一步的,所述稽核检查方法还包括初步检索步骤:
19、采用多个模型将文档库文档和查询语句转换为不同类型的语义向量;
20、根据所述语义向量,在索引库中查询符合预设条件的文档;
21、根据每个模型在测试集上的表现,对每个模型赋予不同的初始权重,利用所述初始权重计算多个所述模型的加权和,得到每篇文档的相似度分数;
22、根据每篇文档的相似度分数召回对应的召回文档,并对所述召回文档进行排序,得到检索结果。
23、进一步的,所述根据所述语义向量,在索引库中查询符合预设条件的文档,包括:
24、根据每个模型对应的语义向量,采用限量检索算法在索引库中查询与源语句最相近的top k个文档;其中,k为大于等于1的正整数。
25、进一步的,所述利用所述初始权重计算多个所述模型的加权和,得到每篇文档的相似度分数,包括:
26、p(x)=α1*scorea1+α2*scoreb1+…+mn*scoreb4
27、其中,p(x)为相似度分数,scoren表示第n个模型计算出的每篇文档与查询语句的相似度分数,αn表示第n个算法模型对应的初始权重,0≤scoren≤1,0≤αn≤1。
28、本发明的一个实施例提供了一种基于多模型的稽核检索装置,包括:
29、训练样本构建模块,用于根据初步检索过程中用户的点击数据构建训练样本;
30、样本特征获取模块,用于将多个模型的得分作为特征数据,将所述特征数据与样本标签进行拼接后得到样本特征数据;
31、机器学习模型构建模块,用于根据所述样本特征数据和所述训练样本建立有监督的机器学习模型;
32、相似度分数计算模块,用于利用所述机器学习模型对多个所述模型的检索结果进行融合,得到每篇文档的最终相似度分数;
33、检索结果获取模块,用于根据所述最终相似度分数根据每篇文档的相似度分数召回对应的最终召回文档,并对所述最终召回文档进行排序,得到最终检索结果。
34、本发明的一个实施例提供了一种终端设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器在执行所述计算机程序时实现如上述的基于多模型的稽核检索方法。
35、本发明实施例利用机器学习模型对多个模型的检索结果进行融合,对查询语句的相关文档进行分析和检索,从而能够有效召回文字表达不同但语义相同的文档,能够全面返回检索的结果,从而能够有效提高稽核检索的准确性。
36、进一步的,本发明实施例基于用户的点击数据以及各个模型的得分构建样本特征数据进行训练与预测,并通过机器学习模型学习得到文档的最终相似度分数,根据最终相似度分数召回对应的文档,能够进一步提高稽核检索的准确性,同时还可以通过扩展检索模型个数以及特征维度,以提高稽核检索的扩展性;而且本发明实施在模型训练过程中能够根据用户的点击数据对模型训练进行自动更新和迭代,从而能够保证机器学习模型持续的有效性,进一步提高了稽核检索的准确性。
技术特征:
1.一种基于多模型的稽核检索方法,其特征在于,包括:
2.如权利要求1所述的基于多模型的稽核检索方法,其特征在于,所述训练样本包括正样本和负样本,所述根据初步检索过程中用户的点击数据构建训练样本,包括:
3.如权利要求1所述的基于多模型的稽核检索方法,其特征在于,还包括:
4.如权利要求1所述的基于多模型的稽核检索方法,其特征在于,所述检索结果获取步骤,还包括:
5.如权利要求1所述的基于多模型的稽核检索方法,其特征在于,所述多个模型包括词袋模型、word2vec模型、lda模型及bert模型。
6.如权利要求1所述的基于多模型的稽核检索方法,其特征在于,还包括初步检索步骤:
7.如权利要求6所述的基于多模型的稽核检索方法,其特征在于,所述根据所述语义向量,在索引库中查询符合预设条件的文档,包括:
8.如权利要求6所述的检索方法,其特征在于,所述利用所述初始权重计算多个所述模型的加权和,得到每篇文档的相似度分数,包括:
9.一种基于多模型的稽核检索装置,其特征在于,包括:
10.一种终端设备,其特征在于,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器在执行所述计算机程序时实现如权利要求1-8中任一项所述的基于多模型的稽核检索方法。
技术总结
本发明公开了一种基于多模型的稽核检索方法、装置及存储介质,其中方法包括:根据初步检索过程中用户的点击数据构建训练样本;将多个模型的得分作为特征数据,将特征数据与样本标签进行拼接后得到样本特征数据;根据样本特征数据和训练样本建立机器学习模型;利用机器学习模型对多个模型的检索结果进行融合,得到每篇文档的最终相似度分数;根据最终相似度分数根据每篇文档的相似度分数召回对应的最终召回文档,并对最终召回文档进行排序。本发明实施例利用机器学习模型对多个模型的检索结果进行融合,对查询语句的相关文档进行分析和检索,从而能够全面返回检索的结果,从而能够有效提高稽核检索的准确性。
技术研发人员:张岩,李衡,邹杰,张汉林
受保护的技术使用者:广发证券股份有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!