一种基于多智能体强化学习的公交桥接方法
本发明涉及智能交通信息处理,更具体的说是涉及一种基于多智能体强化学习的公交桥接方法。
背景技术:
1、作为城市公共交通的重要组成部分,轨道交通受到各种自然和人为事件的影响,可能会给出行人员造成巨大不便,甚至波及地面交通网络造成大面积阻塞。为了对轨道交通扰动进行有效处置,各交通管理部门采取了诸如更改列车时刻表、出租车调、增加平行公交发车频率、公交桥接等多种方式缓解扰动所带来的负面影响并尽快疏散滞留乘客。
2、公交桥接是在轨道交通发生突发事件时,利用仓库点备用公交代替轨道交通继续将乘客输送至目的地。当前大多数研究主要基于konstantinos和matthew在2009年提出的桥接框架进行研究,该框架主要分为三部分:(1)桥接线路生成:基于算法(如最短路径算法,此处还可以使用其他算法替代最短路径算法)生成连接地铁站点的候选线路;(2)桥接线路优化:根据设定目标(如最小化接驳时间、最小化乘客等待时间和旅行时间等)确定各个线路上的接驳频率;(3)车辆派遣:将车辆派遣至响应设定的接驳线路上。
3、但是,现有的公交桥接策略还存在以下问题:(1)现有的公交桥接几乎都需预先设定公交车辆接驳路径,这很大程度上限制了公交桥接的效率;(2)在公交桥接中,当车辆选择桥接站点之后,之后滞留站点乘客分布情况会因为各个车辆的决策而发生变化;同时,各个地铁站点滞留人员的分布又会影响下一时刻点各个车辆的决策。如此反复影响直至站点所有人员疏散完毕。在这种情况下,传统的优化算法很难考虑到所有滞留人员的状态及车辆的特征进行动态决策。
4、因此,如何提供一种根据接驳车辆的属性和各个站台的滞留人员的分布情况动态决定下一访问站点的基于多智能体强化学习的公交桥接方法是本领域技术人员亟需解决的问题。
技术实现思路
1、有鉴于此,本发明提供了一种基于多智能体强化学习的公交桥接方法,可根据接驳车辆的属性和各个站台的滞留人员的分布情况动态决定下一访问站点,提升接驳效率,减少滞留人员等待时间。
2、为了实现上述目的,本发明采用如下技术方案:
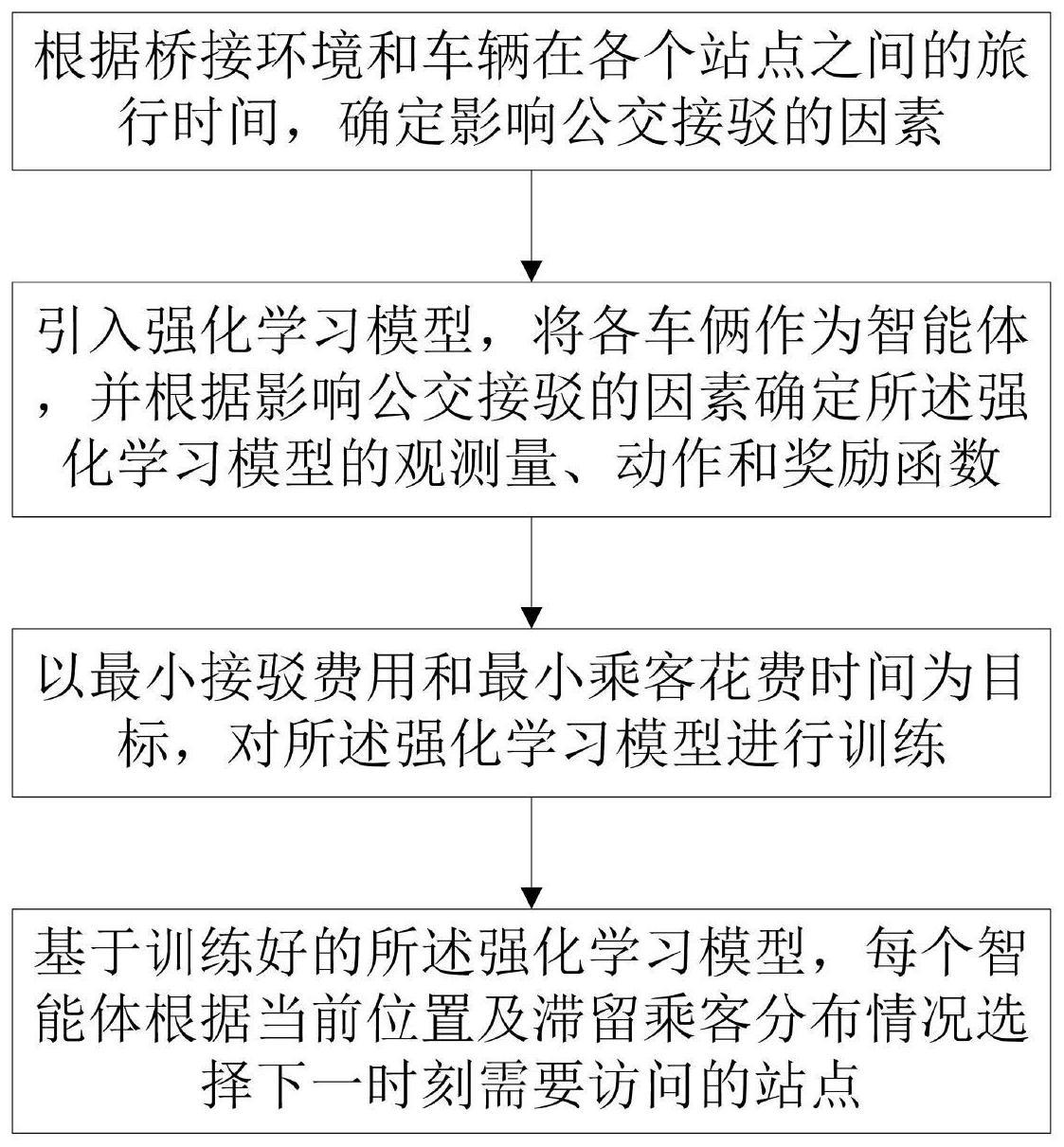
3、一种基于多智能体强化学习的公交桥接方法,包括:
4、根据桥接环境和车辆在各个站点之间的旅行时间,确定影响公交接驳的因素;
5、引入强化学习模型,并根据影响公交接驳的因素确定所述强化学习模型的观测量、动作和奖励函数;
6、以最小接驳费用和最小乘客花费时间为目标,对所述强化学习模型进行训练;
7、基于训练好的所述强化学习模型,每个智能体根据当前位置及滞留乘客分布情况选择下一时刻需要访问的站点。
8、进一步的,所述强化学习模型的观测量包括车辆自身属性和站点滞留人员情况,其表达式为:
9、
10、
11、
12、
13、其中,为车辆i在m时刻的观测量,为车辆i自身属性,为环境状态;分别为车辆i的位置、到达下一站点所需步数以及车辆状态;rrsps,m为剩余人员占比;是车辆i从当前位置前往站台j的效用函数;为车辆前往站台j的时间,rrspes,m,j为站台j剩余人员占比;rspes,m,j为在m时刻从站台s前往站台j的剩余滞留乘客数量,rspes,0,j为接驳开始时从站台s前往站台j的滞留乘客数量;
14、所有车辆在时间步m的观测量表示为:
15、
16、进一步的,所述强化学习模型将动作设置为车辆即将访问的站点的id索引,将动作空间设置为损坏站点的数目n,车辆在行驶途中时,其动作空间在原有基础上增加1。
17、进一步的,所述强化学习模型的奖励函数表示为:
18、
19、上式中,为滞留乘客惩罚,为下车乘客奖励,为上车乘客奖励,为每一时间步的车辆费用,时间步差距惩罚,为单个车辆接驳任务完成奖励。
20、进一步的,滞留乘客惩罚的表达式为:
21、
22、上式中,a为滞留乘客惩罚系数,rsps,m为m时刻所有站台剩余滞留乘客数量,rsps,0为接驳开始时滞留乘客数量,10和5为常量;
23、下车乘客奖励的表达式为:
24、
25、上式中,为车辆i在下一站下车的乘客数量,cdrop为每一个下车乘客的奖励;
26、上车乘客奖励的表达式为:
27、
28、上式中,是车辆i在下一站点上车的乘客数量,cby为每一个上车乘客的奖励,其中,cdrop>cby;
29、每一时间步的车辆费用表达式为:
30、
31、上式中,b为车辆在每一时间步的费用;
32、时间步差距惩罚表达式为:
33、
34、上式表示当车辆i的时间步大于当前所有车辆的最小时间步时给予惩罚d;
35、单个车辆接驳任务完成奖励的表达式为:
36、
37、上式中,表示智能体i的接驳任务已完成。接驳任务完成后给予奖励e;
38、所有车辆接驳任务完成奖励表达式为:
39、
40、上式中,表示所有智能体的接驳任务已完成,接驳任务完成后给予智能体奖励f。
41、进一步的,所述强化学习模型还包括:竞争奖励函数,其表达式为:
42、
43、其中,i(ai=aj)为指示函数,当智能体i和智能体j选择相同的动作时,i(ai=aj)=1,否则i(ai=aj)=0;α1>α2,表示当智能体i的奖励大于智能体j的奖励时,智能体i将会被奖励,否则将会被惩罚;
44、智能体i的奖励值重写为:
45、所有智能体在时间步m时的奖励值为:
46、进一步的,所述强化学习模型的目标函数为:
47、
48、其中,max r(metro)为最大化地铁系统韧性,d,b,s分别为仓库、车辆及受扰动站点集合,p为滞留乘客集合;ω1和ω2分别是接驳费用和乘客花费时间的权重;为仓库d派遣的车辆b是否由站点i驶向站点j,如果是,否则c是单个时间步中的花费,由旅行时间或油耗表示;为乘客p在m时刻的时间花费,由等待时间和在车时间之和表示。
49、经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于多智能体强化学习的公交桥接方法,有益效果是:
50、(1)本发明相比于以往的公交桥接,无需提前设定车辆需要行驶在高速路线或者站站停路线上,各车辆根据自身属性和各个站点滞留人员分布情况动态确定下一时刻访问的站点,其一可以防止车辆为完成一个往返旅途中的某一方向上空驶而避免资源车辆浪费;其二,即使车辆的位置以及站点滞留人员分布情况发生变化,本发明也能够根据其变化生成对应策略,体现出了对动态变化环境更强的适应性。
51、(2)本发明可适用于单条线路突发故障和多条线路突发故障时的应急接驳,具有非常广阔的落地应用前景。
技术特征:
1.一种基于多智能体强化学习的公交桥接方法,其特征在于,包括:
2.根据权利要求1所述的一种基于多智能体强化学习的公交桥接方法,其特征在于,所述强化学习模型的观测量包括车辆自身属性和站点滞留人员情况,其表达式为:
3.根据权利要求1所述的一种基于多智能体强化学习的公交桥接方法,其特征在于,所述强化学习模型将动作设置为车辆即将访问的站点的id索引,将动作空间设置为损坏站点的数目n,车辆在行驶途中时,其动作空间在原有基础上增加1。
4.根据权利要求1所述的一种基于多智能体强化学习的公交桥接方法,其特征在于,所述强化学习模型的奖励函数表示为:
5.根据权利要求4所述的一种基于多智能体强化学习的公交桥接方法,其特征在于,滞留乘客惩罚的表达式为:
6.根据权利要求1所述的一种基于多智能体强化学习的公交桥接方法,其特征在于,所述强化学习模型还包括:竞争奖励函数,其表达式为:
7.根据权利要求1所述的一种基于多智能体强化学习的公交桥接方法,其特征在于,所述强化学习模型的目标函数为:
技术总结
本发明公开了一种基于多智能体强化学习的公交桥接方法,包括:根据桥接环境和车辆在各个站点之间的旅行时间,确定影响公交接驳的因素;引入强化学习模型,将各车俩作为智能体,并根据影响公交接驳的因素确定强化学习模型的观测量、动作和奖励函数;以最小接驳费用和最小乘客花费时间为目标,对强化学习模型进行训练;基于训练好的所述强化学习模型,每个智能体根据当前位置及滞留乘客分布情况选择下一时刻需要访问的站点。本发明可根据接驳车辆的属性和各个站台的滞留人员的分布情况动态决定下一访问站点,提升接驳效率,减少滞留人员等待时间。
技术研发人员:马晓磊,谭二龙,刘兵,曹晨航
受保护的技术使用者:北京航空航天大学
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!