一种基于全文语义挖掘结合对抗训练的API推荐方法
本发明属于api推荐领域,具体涉及一种基于全文语义挖掘结合对抗训练的api推荐方法。
背景技术:
1、近年来,随着面向服务的计算领域的不断扩大,web api的数量不断增加。当前业务场景的复杂性不像以前那么简单,因此,现有的单一api不再满足我们的要求。在这样的环境中,mashup通常服务于特定的上下文的(短暂的)需求,由最新的、易使用的api组成,已成为集成多种服务以满足复杂需求的重要技术。由于它的这些优点,近年来,mashup和api也被广泛开发并应用于web和移动应用。鉴于大量的api及其惊人的增长速度,mashup开发人员很难在短时间内找到满足所有需求的api,这无疑增加了mashup开发的难度。api推荐基于mashup开发人员的功能需求,以便从大量的api中选择相关的api进行推荐。开发人员希望开发一个mashup,并在执行需求分析后编写一个需求文档,然后将需求分为几个功能。为了找到实现这些功能的合适api,开发人员需要在在线的mashup-api存储平台(如programmableweb)中搜索具有所需功能的合适的api。然后从这些候选api中选择与需求功能对应的api,以组合mashup所需的功能。近年来,由于开发者在应用程序开发中有效地找到合适的api至关重要,企业和学术界都对api推荐十分关注。
2、现实世界中几乎没有相关的标签可以用来有效地集成api;因此,仅用几个关键字描述复杂的开发需求是不够的,也不能充分表达开发人员的个人需求。现有的挖掘开发人员需求进行api推荐的技术可分为两类。一类是将开发人员的api查询输入(由一组短语、句子甚至段落组成)以及每个api描述中的现有关键字存储到一个集合中,并使用fasttext技术将它们转换为向量。计算关键字的相似性产生了一组候选api,然后将其与现有mashup中的api进行比较,以提供最终的推荐列表。该方法从三个方面(开发人员、mashup和api)进行推荐,更能代表实际的应用程序开发情况。然而,如果mashup开发人员不具备专业知识,将花大量时间或是难以使用关键字、精炼的句子或段落来描述他们的开发需求。
3、另一类是利用doc2vec技术挖掘mashup和api描述信息,计算两者之间的文本相似度,然后基于相似度和现有mashup中的api信息生成推荐。这种用于处理长文本的自然语言处理技术可以有效地挖掘文本信息,因为它提取整个事件而不是关键词,并且不会破坏句子之间的语义关系。美中不足的是,仅从mashup和api两个方面挖掘信息将很难获得开发人员更加个性化的需求。
4、此外,api数量的快速增长使得mashup和api的调用数据更加稀疏,因为只有少数api被频繁调用,大多数api甚至没有被mashup调用,这影响了推荐结果的准确性。
技术实现思路
1、为解决上述技术问题,本发明提出一种基于全文语义挖掘结合对抗训练的api推荐方法,包括以下步骤:
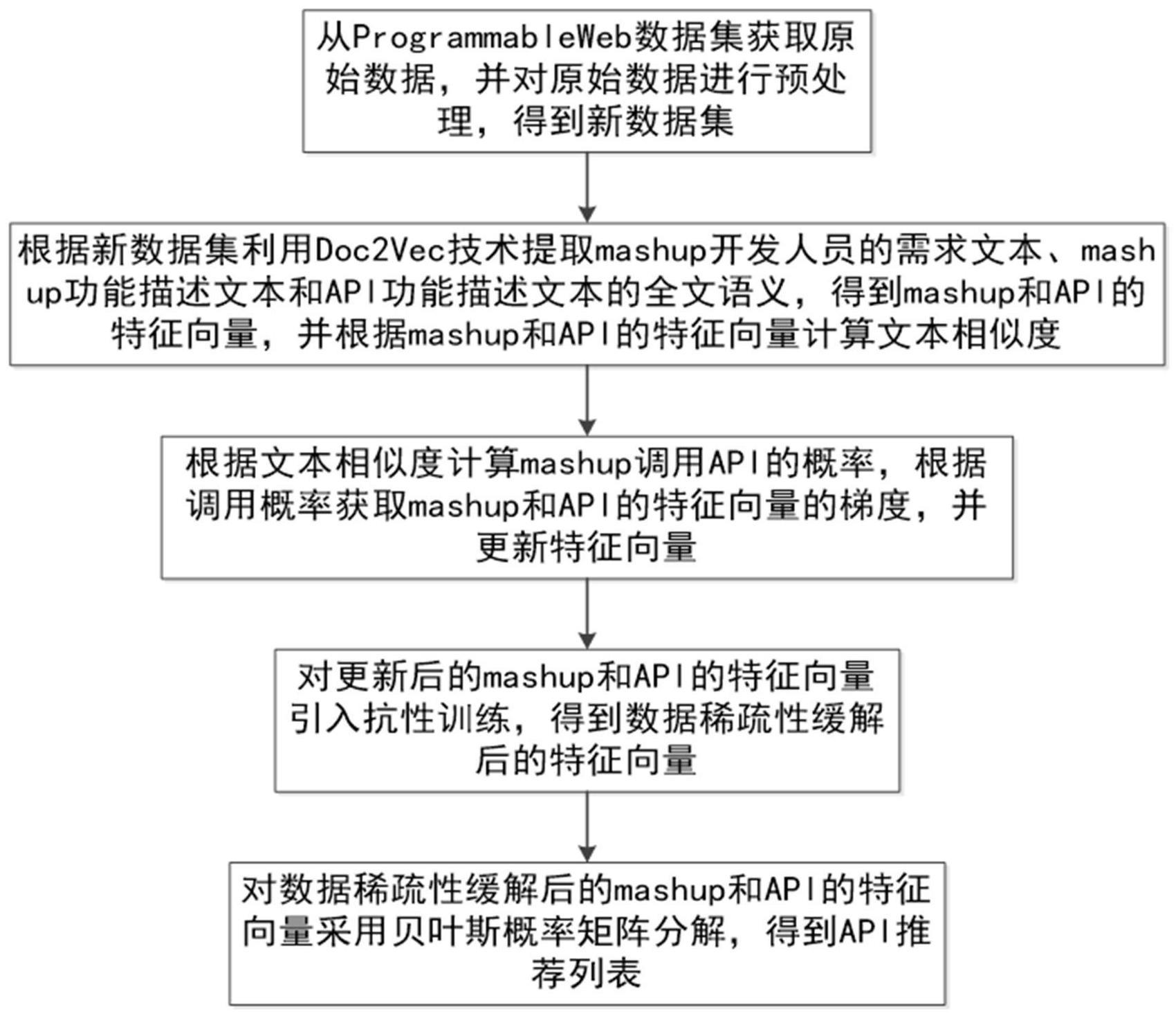
2、s1:从programmableweb数据集获取原始数据,并对原始数据进行预处理,得到新数据集;
3、所述原始数据包括:api功能描述文本、mashup功能描述文本、mashup对api的历史调用记录、mashup开发人员的需求文本;
4、s2:根据新数据集利用doc2vec技术提取mashup开发人员的需求文本、mashup功能描述文本和api功能描述文本的全文语义,得到mashup和api的特征向量,并根据mashup和api的特征向量计算文本相似度;
5、s3:根据文本相似度计算mashup调用api的概率,根据调用概率获取mashup和api的特征向量的梯度,并更新特征向量;
6、s4:对更新后的mashup和api的特征向量引入抗性训练,得到数据稀疏性缓解后的特征向量;
7、s5:对数据稀疏性缓解后的mashup和api的特征向量采用贝叶斯概率矩阵分解,得到api推荐列表。
8、本发明的有益效果:
9、本发明综合了三个方面(mashup开发人员、mashup和api)的内容来进行推荐,并可以捕捉开发人员更个性化的需求;为了最大限度地满足开发人员的需求,本发明允许mashup开发人员使用文档来表达他们的个性化开发需求,使没有专业知识的mashup开发人员更容易描述他们的需求;本发明使用doc2vec技术来挖掘需求文档、mashup描述和api描述,方法是提取整个事件,而不是抓取关键字来挖掘全文语义,这确保了挖掘的信息尽可能保持语义关系,并更准确地反映了开发人员的个人需求。
10、本发明为了克服稀疏数据的问题,将获得的上下文信息用作模型中的辅助信息,并引入对抗性训练来向数据中添加扰动因子,以进一步解决该问题并提高模型的泛化鲁棒性。
技术特征:
1.一种基于全文语义挖掘结合对抗训练的api推荐方法,其特征在于,包括:
2.根据权利要求1所述的一种基于全文语义挖掘结合对抗训练的api推荐方法,其特征在于,对原始数据进行预处理,得到新数据集,包括:
3.根据权利要求1所述的一种基于全文语义挖掘结合对抗训练的api推荐方法,其特征在于,所述s2,具体包括:
4.根据权利要求3所述的一种基于全文语义挖掘结合对抗训练的api推荐方法,其特征在于,计算特征向量mi和aj之间的文本相似度,包括:
5.根据权利要求1所述的一种基于全文语义挖掘结合对抗训练的api推荐方法,其特征在于,所述s3,具体包括:
6.根据权利要求5所述的一种基于全文语义挖掘结合对抗训练的api推荐方法,其特征在于,计算mashup调用api的概率,包括:
7.根据权利要求5所述的一种基于全文语义挖掘结合对抗训练的api推荐方法,其特征在于,使用概率矩阵分解的思想获取mashup需求文本的特征向量mi调用api需求文本的特征向量aj的梯度和包括:
8.根据权利要求5所述的一种基于全文语义挖掘结合对抗训练的api推荐方法,其特征在于,通过梯度和更新mi和aj,包括:
9.根据权利要求1所述的一种基于全文语义挖掘结合对抗训练的api推荐方法,其特征在于,对更新后的mashup和api的特征向量引入抗性训练,得到数据稀疏性缓解后的特征向量,包括:
10.根据权利要求1所述的一种基于全文语义挖掘结合对抗训练的api推荐方法,其特征在于,对数据稀疏性缓解后的mashup和api的特征向量采用贝叶斯概率矩阵分解,包括:
技术总结
本发明属于API推荐领域,具体涉及一种基于全文语义挖掘结合对抗训练的API推荐方法,包括:对原始数据进行预处理;利用自然语言处理技术提取需求文档、mashup描述和API描述的全文语义,并计算文本相似度;根据文本相似度计算mashup调用API的概率,根据概率获取mashup和API的特征向量的梯度,并更新特征向量;对更新后的mashup和API的特征向量引入抗性训练,得到数据稀疏性缓解后的特征向量;对数据稀疏性缓解后的mashup和API的特征向量采用贝叶斯概率矩阵分解,得到API推荐列表。本发明有助于API平台有效挖掘开发人员的个性化开发需求,减轻开发人员的工作量,同时提高了推荐精度。
技术研发人员:桑春艳,邓欣燕,廖世根,易星宇
受保护的技术使用者:重庆邮电大学
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!