用于执行深度神经网络的计算的硬件加速器和包括其的电子设备的制作方法
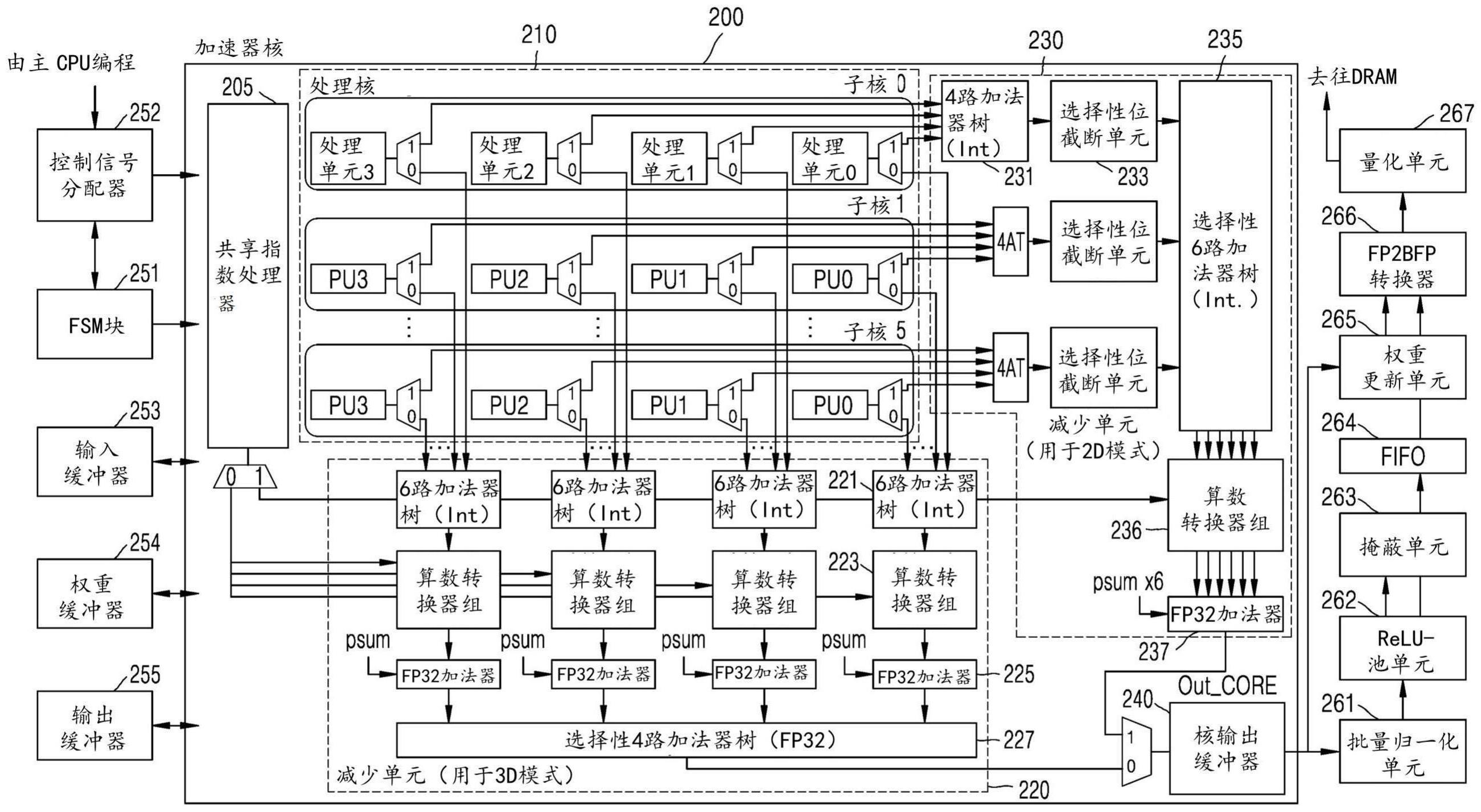
本公开涉及一种用于执行深度神经网络的计算的硬件加速器以及包括该硬件加速器的电子设备,并且更具体地,涉及一种通过使用块浮点来支持具有各种精度的学习和推断操作并且在学习操作的每个阶段以高效率操作的硬件加速器以及包括该硬件加速器的电子设备。
背景技术:
1、受高性能计算系统和不断增长的开源数据集的影响,深度学习发展得非常迅速。此外,随着精度的提高,深度学习技术正在许多应用中使用,诸如计算机视觉、语言建模或自主驾驶。
2、为了在应用中使用深度学习,需要称为训练的过程。在深度学习中,训练是指通过特定数据集更新深度神经网络(dnn)的权重的过程。权重更新得越好,dnn可以越好地执行给定任务。
3、训练包括前向传递步骤、后向传递步骤、权重更新步骤等。前向传递步骤是计算训练过程中的损失的过程,后向传递步骤是计算损失函数的梯度的过程。梯度通常通过链式法则获得,并且在与前向传递步骤的方向相反的方向上传播到构成dnn的所有层。权重更新步骤是对构成dnn的权重进行更新的过程,通过从当前的权重中减去将权重的损失函数的梯度乘以学习速率而得到的值来进行更新。
4、这样的训练过程需要相当大量的计算,并且因此当在中央处理单元(cpu)上执行时花费大量时间。图形处理单元(gpu)更适合于并行处理,因此比cpu消耗更少的时间,但由于其结构特性而显示出低利用率。
5、最近,已经提出了许多专用硬件加速器来克服cpu和gpu的缺点。然而,现有技术中的加速器仅支持特定精度或仅针对特定训练步骤(例如,前向传递步骤和后向传递步骤)表现出高效率。
技术实现思路
1、另外的方面将部分地在下面的描述中阐述,并且部分地将从描述中显而易见,或者可以通过实践本公开的所呈现的实施例来学习。
2、根据本公开的一个方面,一种硬件加速器包括多个乘法器,所述多个乘法器在第一张量的符号和尾数与第二张量的符号和尾数之间执行一维(1d)子字并行化。所述硬件加速器可以包括第一处理设备,所述第一处理设备在二维(2d)操作模式下操作以输出多个乘法器的计算结果。硬件加速器可以包括以三维(3d)操作模式操作的第二处理设备,用于在通道方向上累加多个乘法器的计算结果,并输出累加计算结果的结果。
3、根据本公开的另一方面,一种电子设备包括硬件加速器,该硬件加速器通过使用多个乘法器在第一张量的符号和尾数与第二张量的符号和尾数之间执行1d子字并行化,并且通过使用共享指数处理器在第一张量的共享指数与第二张量的共享指数之间执行处理。电子设备可以包括处理器,该处理器被配置为执行至少一个指令以基于深度神经网络信息来控制硬件加速器,该深度神经网络信息包括深度神经网络中的层的数量、层的类型、张量的形状、张量的维度、操作模式、位精度、批量归一化的类型、池化层的类型和修正线性单元(relu)函数的类型中的至少一个。电子设备可以包括存储至少一个指令和深度神经网络的存储器。
技术特征:
1.一种用于执行深度神经网络的计算的硬件加速器,所述硬件加速器包括:
2.如权利要求1所述的硬件加速器,其中,所述多个乘法器中的第一组执行第一张量中包括的第一值的一系列子字与第二张量中包括的第二值的一系列子字之中的第一子字之间的乘法操作,并且
3.如权利要求1所述的硬件加速器,其中,在深度神经网络的计算中,硬件加速器在执行权重梯度计算、逐深度(dw)卷积、扩张卷积或向上卷积时在2d操作模式下操作,其中计算结果不在通道方向上累加,并且在执行卷积、逐点卷积或全连接层计算时在3d操作模式下操作,其中计算结果在通道方向上累加。
4.如权利要求1所述的硬件加速器,其中,所述处理核包括六个子核,
5.如权利要求4所述的硬件加速器,其中,在深度神经网络的conv3层的计算的情况下,基于第一张量的符号和尾数的大小为16位,与conv3层的一个输入通道相对应的第一张量被广播到构成一个子核的四个处理单元,
6.如权利要求4所述的硬件加速器,其中,在深度神经网络的conv3层的计算的情况下,基于第二张量的符号和尾数的大小为16位,与conv3层的一个输出通道相对应的第二张量被分发到构成一个子核的四个处理单元,
7.如权利要求4所述的硬件加速器,其中,所述第一处理设备包括:
8.如权利要求4所述的硬件加速器,其中,所述第二处理设备包括:
9.如权利要求4所述的硬件加速器,其中,所述处理单元中的每一个包括:
10.如权利要求1所述的硬件加速器,还包括共享指数处理器,被配置为处理第一张量的共享指数和第二张量的共享指数。
11.如权利要求1所述的硬件加速器,其中,所述处理核被配置为通过使用与控制信号相对应的多种数据类型来执行计算,并且
12.如权利要求1所述的硬件加速器,其中,所述第一张量的共享指数的大小和第二张量的共享指数的大小是8位,
13.如权利要求12所述的硬件加速器,其中,所述第一张量的符号和尾数的大小或第二张量的符号和尾数的大小是基于训练深度神经网络的前向传递步骤、后向传递步骤或权重更新步骤来确定的。
14.如权利要求1所述的硬件加速器,还包括核输出缓冲器,被配置为在权重更新步骤中输出第一处理设备的输出值,并且在前向传递步骤和后向传递步骤中输出第二处理设备的输出值。
15.如权利要求14所述的硬件加速器,还包括:
16.如权利要求1所述的硬件加速器,其中,所述多个乘法器中的每一个包括:
17.如权利要求16所述的硬件加速器,其中,通过由保持信号生成的反馈环路来维持存储在第二寄存器中的值。
18.一种用于执行深度神经网络的训练和推断的电子设备,所述电子设备包括:
19.如权利要求18所述的电子设备,其中,所述至少一个处理器还被配置为执行所述至少一个指令以基于用户输入获得深度神经网络的位精度和块大小中的至少一个,基于所获得的位精度和块大小中的至少一个设置第一张量和第二张量的位精度和块大小中的至少一个,并且基于所述设置控制硬件加速器训练所述深度神经网络。
20.如权利要求18所述的电子设备,其中,所述硬件加速器还被配置为在二维(2d)操作模式下操作,在二维操作模式中,输出多个乘法器的计算结果而不在通道方向上累加,或者在三维(3d)操作模式下操作,在三维操作模式中,在通道方向上累加多个乘法器的计算结果并且输出累加所述计算结果的结果。
技术总结
一种硬件加速器,包括:处理核,包括多个乘法器,所述多个乘法器被配置为在第一张量的符号和尾数与第二张量的符号和尾数之间执行一维(1D)子字并行化,第一处理设备被配置为在二维(2D)操作模式下操作,在二维操作模式中,输出多个乘法器的计算结果,以及第二处理设备,被配置为在三维(3D)操作模式下操作,在三维操作模式中,在通道方向上累加多个乘法器的计算结果,然后输出累加计算结果的结果。
技术研发人员:卢锡焕,弓在河,具滋铉
受保护的技术使用者:财团法人大邱庆北科学技术院
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!