基于提示微调预训练大模型的行人属性识别方法
本发明属于计算机视觉,涉及一种基于提示微调预训练大模型的行人属性识别方法。
背景技术:
1、行人属性识别的目标是使用一组预定义的属性(如年龄、身高、发型、服装)来描述人的中间层语义信息。它在计算机视觉领域,特别是智能视频监控和自动驾驶领域发挥着重要作用,同时也促进了其他视觉任务的研究,包括行人重识别、行人搜索和行人检测。在人工智能的帮助下,如cnn(卷积神经网络)和rnn(递归神经网络),这一研究领域受到了广泛的关注并取得了很大的进展。然而,由于在极端情况下(包括运动模糊、阴影、遮挡、低分辨率、多视图和夜间)成像质量较差,行人属性识别仍然是一项具有挑战性的任务。
2、现有大多数行人属性方法是基于cnn和rnn网络的,难以利用行人的高级语义信息导致识别精度低,并且基于cnn的方法没有考虑到行人属性的语义相关性,导致性能次优,而基于rnn的方法过度依赖于人工预定义的属性顺序而难以达到最好的性能。例如,在论文《deep-camp:deep convolutional action&attribute mid-level patterns》中,结合了基于部件的模型和基于cnn的行人属性识别,并加速了cnn的训练,以便从较小的数据集中学习更强的规范化特征。此种通过cnn网络作为主干网络的方式存在着缺陷,由于行人属性之间存在内部关联,比如“长头发”和“女性”这两个属性高度相关,因而采用这类纯视觉的行人属性方法,存在忽略了属性的语义信息导致次优的问题;虽然现有技术中已经有基于transformer的工作融合了视觉和文本信息,一定程度解决了上述问题,但由于采用的是独立预训练的视觉文本的编码器,导致视觉文本的特征之前存在较大差异,这样在后续的视觉文本模态融合过程中,可能因此受到限制导致识别精度会降低。另外,现有的行人属性识别方法大多采用在单模态数据集上预训练的模型,这导致模型的泛化能力较差,并且图像和文本的特征之间存在较大差异。
技术实现思路
1、本发明的目的在于如何设计一种基于提示微调预训练大模型的行人属性识别方法,以解决现有技术中没有充分利用行人图像与属性标签之间的关系而导致的次优以及泛化能力差的问题。
2、本发明是通过以下技术方案解决上述技术问题的:
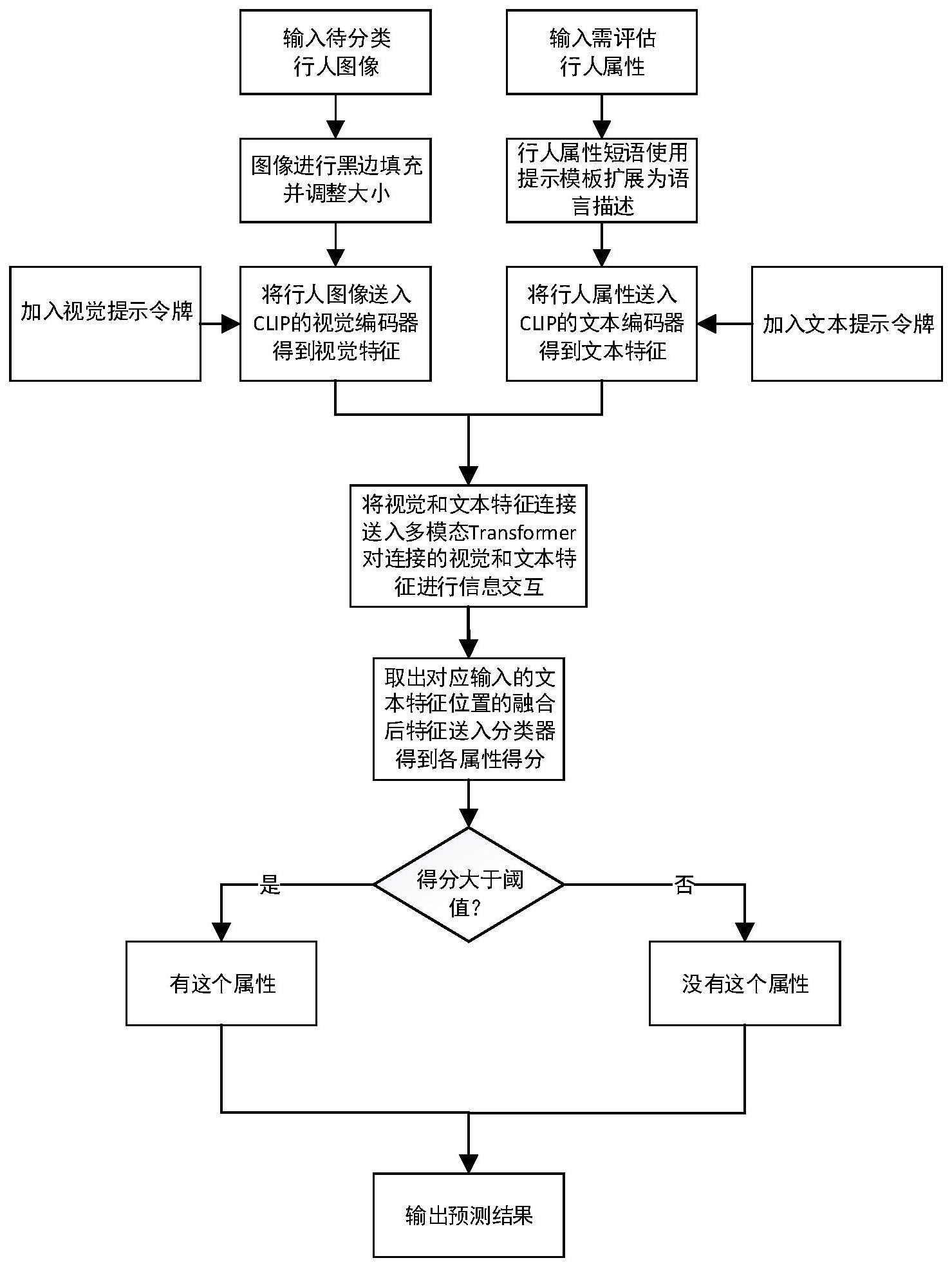
3、基于添加提示微调的预训练大模型的行人属性识别方法,所述的预训练大模型包括:clip视觉编码器、clip文本编码器、多模态transformer模块和分类器模块;所述的clip视觉编码器以及clip文本编码器是视觉语言模型clip的视觉和文本特征提取器;所述的多模态transformer模块通过多头自注意力机制对属性进行自适应融合和长距离建模,经过多层transformer编码器层后得到融合后的特征;所述的分类器模块采用ffn,用于得到每个属性的得分并输出分类结果;
4、所述的行人属性识别方法包括以下步骤:
5、步骤一:对输入的待分类的行人图像和需要评估的行人属性进行预处理;
6、步骤二:将待分类的行人图像和需要评估的行人属性分别送入预训练大模型中,从而分别得到视觉特征和文本特征;
7、步骤三:将得到视觉特征和文本特征连接后送入多模态transformer模块,对连接的视觉特征和文本特征进行模态融合和信息交互,得到融合交互后的特征;
8、步骤四:取出其中文本特征对应位置的融合后的令牌(token),送入分类器后得到每个属性的得分;
9、步骤五:判断得分是否大于阈值,大于阈值的属性视为属性存在,否则视为属性不存在,每个属性均与阈值进行对比后输出预测结果。
10、进一步地,所述的clip视觉编码器采用resnet或者视觉transformer编码器;所述的clip文本编码器是基于transformer的编码器设计的,使用的是clip vit-l/14的模型参数。
11、进一步地,步骤一中所述的对输入的待分类的行人图像和需要评估的行人属性进行预处理的方法如下:对输入的行人图像进行预处理:提前将行人图像进行黑边填充,以防止在后续的大小调整过程中导致行人特征畸变,将行人图像大小调整到224*224,在训练过程中执行随机水平翻转,随机裁剪的数据增强;对输入的行人图像进行预处理:对输入的行人属性集使用提示模板将属性短语扩展为语言描述,以适应clip文本编码器。
12、进一步地,步骤二中所述的预训练大模型的训练方法如下:所述的clip视觉编码器和clip文本编码器加载clip vit-l/14的模型参数,多模态tranformer模块加载在imagenet-21k数据集上进行预训练,并在imagenet-1k数据集上进行微调vit-b/16的模型参数。
13、进一步地,步骤二中所述的得到视觉特征的方法如下:在clip视觉编码器每一层的transformer编码器层的输入令牌中都加入多个可学习的提示令牌,位置是在分类令牌和图像块令牌之间,以此来微调clip视觉编码器,经过多层transformer编码器层后得到视觉特征。
14、进一步地,步骤二中所述的得到文本特征的方法如下:将分割和扩充后属性句子令牌化后,经过嵌入层后得到文本的嵌入并送入clip文本编码器,在clip文本编码器每一层的transformer编码器层的输入令牌中都加入多个可学习的提示令牌,位置是在文本令牌之后,以此来微调clip文本编码器,经过多层transformer编码器层后得到文本的特征。
15、本发明的优点在于:
16、(1)本发明针对现有行人属性识别方法无法充分利用属性语义信息,泛化性差的特点,采用clip的视觉和文本编码器提取图像特征和属性特征,通过多模态transformer模块对两个模态特征融合后,经过前馈网络得到预测结果,通过将行人属性识别问题建模为视觉语言融合问题,使用预训练的视觉语言大模型作为主干网络,提取模态间联系更好的视觉和文本特征,再通过多模态的transformer建模视觉和文本之间的联系,充分利用了属性语义信息,并且可以看出通过提示微调的方式保留了预训练大模型较好的泛化能力,模型实用性更强。
17、(2)本发明的方法通过transformer的全局建模能力,对连接起来的视觉文本特征进行融合,较好的利用了属性的语义信息。
18、(3)本发明的方法选择使用在4亿图像文本对上预训练的clip大模型来缓解这些问题,但是使用大模型作为主干网络会带来的计算量的提升,通过引入提示微调(prompttuning)的方法来减少调整的参数量。
技术特征:
1.基于提示微调预训练大模型的行人属性识别方法,其特征在于,所述的预训练大模型包括:clip视觉编码器、clip文本编码器、多模态transformer模块和分类器模块;所述的clip视觉编码器以及clip文本编码器是视觉语言模型clip的视觉和文本特征提取器;所述的多模态transformer模块通过多头自注意力机制对属性进行自适应融合和长距离建模,经过多层transformer编码器层后得到融合后的特征;所述的分类器模块采用ffn,用于得到每个属性的得分并输出分类结果;
2.根据权利要求1所述的基于提示微调预训练大模型的行人属性识别方法,其特征在于,所述的clip视觉编码器采用resnet或者视觉transformer编码器;所述的clip文本编码器是基于transformer的编码器设计的,使用的是clip vit-l/14的模型参数。
3.根据权利要求1所述的基于提示微调预训练大模型的行人属性识别方法,其特征在于,步骤一中所述的对输入的待分类的行人图像和需要评估的行人属性进行预处理的方法如下:对输入的行人图像进行预处理:提前将行人图像进行黑边填充,以防止在后续的大小调整过程中导致行人特征畸变,将行人图像大小调整到224*224,在训练过程中执行随机水平翻转,随机裁剪的数据增强;对输入的行人图像进行预处理:对输入的行人属性集使用提示模板将属性短语扩展为语言描述。
4.根据权利要求3所述的基于提示微调预训练大模型的行人属性识别方法,其特征在于,步骤二中所述的预训练大模型的训练方法如下:所述的clip视觉编码器和clip文本编码器加载clip vit-l/14的模型参数,多模态tranformer模块加载在imagenet-21k数据集上进行预训练,并在imagenet-1k数据集上进行微调vit-b/16的模型参数。
5.根据权利要求4所述的基于提示微调预训练大模型的行人属性识别方法,其特征在于,步骤二中所述的得到视觉特征的方法如下:在clip视觉编码器每一层的transformer编码器层的输入令牌中都加入多个可学习的提示令牌,位置是在分类令牌和图像块令牌之间,以此来微调clip视觉编码器,经过多层transformer编码器层后得到视觉特征。
6.根据权利要求5所述的基于提示微调预训练大模型的行人属性识别方法,其特征在于,步骤二中所述的得到文本特征的方法如下:将分割和扩充后属性句子令牌化后,经过嵌入层后得到文本的嵌入并送入clip文本编码器,在clip文本编码器每一层的transformer编码器层的输入令牌中都加入多个可学习的提示令牌,位置是在文本令牌之后,以此来微调clip文本编码器,经过多层transformer编码器层后得到文本的特征。
技术总结
一种基于提示微调预训练大模型的行人属性识别方法,属于计算机视觉技术领域,解决现有技术中没有充分利用行人图像与属性标签之间的关系而导致的次优以及泛化能力差的问题。本发明采用CLIP的视觉和文本编码器提取图像特征和属性特征,通过多模态Transformer模块对两个模态特征融合后,经过前馈网络得到预测结果,通过将行人属性识别问题建模为视觉语言融合问题,使用预训练的视觉语言大模型作为主干网络,提取模态间联系更好的视觉和文本特征,再通过多模态的Transformer建模视觉和文本之间的联系,充分利用了属性语义信息,并且可以看出通过提示微调的方式保留了预训练大模型较好的泛化能力,模型实用性更强。
技术研发人员:李成龙,金建东,王逍,汤进,章程
受保护的技术使用者:安徽大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!