显示设备及视觉问答方法与流程
本申请涉及视觉问答,尤其涉及一种显示设备及视觉问答方法。
背景技术:
1、视觉问答(visual question answering,vqa),是一种涉及计算机视觉和自然语言处理的学习任务,视觉问答的输入可包括一张图片和一个自然语言问题,输出可包括一条自然语言答案。相关技术中,视觉问答方法是通过对输入的图片和自然语言问题进行分析,得到图像特征和文本特征,再将图像特征和文本特征进行融合得到融合特征,基于融合特征生成自然语言答案。然而,上述视觉问答方法未考虑图像特征和文本特征的关联度,得到的问答结果准确性欠佳。
技术实现思路
1、为解决上述技术问题,本申请提供了一种显示设备及视觉问答方法。
2、第一方面,本申请提供了一种显示设备,该显示设备包括:
3、显示器;
4、控制器,与所述显示器连接,所述控制器被配置为:
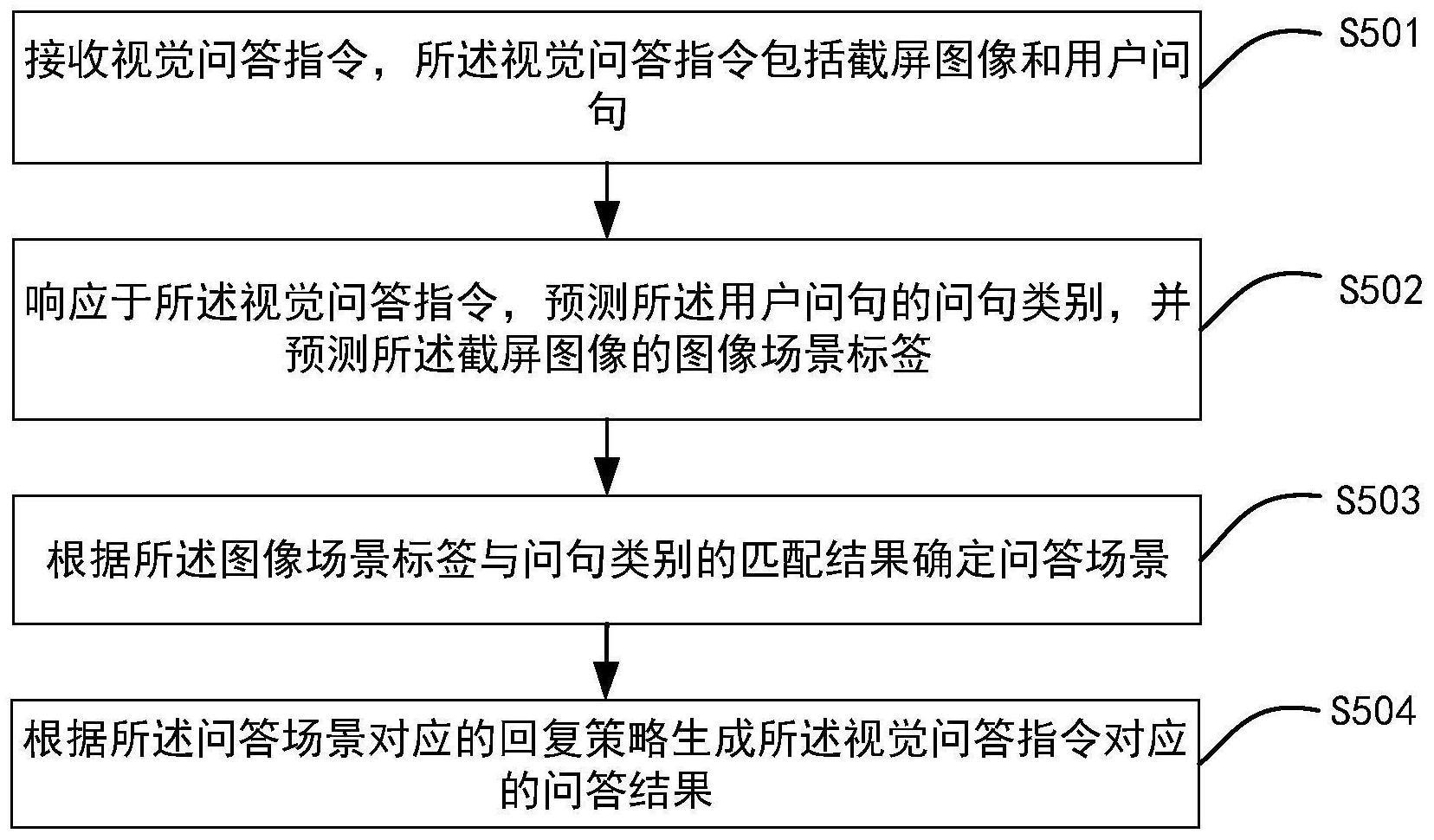
5、接收视觉问答指令,所述视觉问答指令包括截屏图像和用户问句;
6、响应于所述视觉问答指令,预测所述用户问句的问句类别,并预测所述截屏图像的图像场景标签;
7、根据所述图像场景标签与问句类别的匹配结果确定问答场景;
8、根据所述问答场景对应的回复策略生成所述视觉问答指令对应的问答结果。
9、在一些实施例中,所述根据所述图像场景标签与问句类别的匹配结果确定问答场景,包括:
10、响应于所述问句类别与图像场景标签相匹配,根据所述问句类别确定问答场景;
11、响应于所述问句类别与图像场景标签不匹配,确定所述问答场景为用户自定义场景。
12、在一些实施例中,所述根据所述问句类别确定问答场景,包括:
13、根据所述问句类别为实体类别,确定所述问答场景为影视推荐类场景;
14、根据所述问句类别不是所述实体类别,确定所述问答场景为所述问句类别对应的预设算法类场景。
15、在一些实施例中,所述根据所述问答场景对应的回复策略生成所述视觉问答指令对应的问答结果,包括:
16、根据所述问答场景为影视推荐类场景,获取目标实体的介绍信息以及所述目标实体关联的影视推荐信息,生成包含所述介绍信息和影视推荐信息的问答结果,其中,所述目标实体根据所述实体类别以及所述截屏图像中识别出的实体确定,所述图像场景标签包括所述目标实体对应的标签;
17、根据所述问答场景为预设算法类场景,调用所述问句类别对应的算法接口,以获取所述用户问句中的关键词对应的实体的预测信息,生成包含所述预测信息的问答结果。
18、在一些实施例中,所述预测所述截屏图像的图像场景标签,包括:
19、检测所述截屏图像中的实体,根据检测到的所述实体生成第一标签;
20、生成所述截屏图像的描述信息,根据所述描述信息的分词结果生成第二标签;
21、分别将所述第一标签和第二标签中属于同一场景的标签进行融合,得到融合标签;
22、将所述融合标签中属于同一场景的标签进行融合,得到图像场景标签。
23、在一些实施例中,所述将所述融合标签中属于同一场景的标签进行融合,得到图像场景标签,包括:
24、将所述融合标签中属于同一场景的标签的预测概率进行加权叠加,根据加权叠加后的预测概率从所述融合标签中筛选出图像场景标签。
25、在一些实施例中,所述预测所述用户问句的问句类别,包括:
26、通过朴素贝叶斯分类器获取所述用户问句的概率最大的预测类别;
27、响应于所述预测类别为实体类别,确定所述用户问句的问句类别为所述实体类别;
28、响应于所述预测类别不是所述实体类别,确定所述用户问句的问句类别包括所述预测类别和目标类别,所述目标类别为所述用户问句的概率最大的实体类别。
29、在一些实施例中,所述根据所述图像场景标签与问句类别的匹配结果确定问答场景,包括:
30、将所述问句类别中的实体类别与所述图像场景标签进行匹配;
31、响应于所述实体类别与图像场景标签相匹配,根据所述预测类别确定问答场景;
32、响应于所述实体类别与图像场景标签不匹配,确定所述问答场景为用户自定义场景。
33、第二方面,本申请提供了一种视觉问答方法,该方法包括:
34、接收视觉问答指令,所述视觉问答指令包括截屏图像和用户问句;
35、响应于所述视觉问答指令,预测所述用户问句的问句类别,并预测所述截屏图像的图像场景标签;
36、根据所述图像场景标签与问句类别的匹配结果确定问答场景;
37、根据所述问答场景对应的回复策略生成所述视觉问答指令对应的问答结果。
38、在一些实施例中,所述根据所述图像场景标签与问句类别的匹配结果确定问答场景,包括:
39、响应于所述问句类别与图像场景标签相匹配,根据所述问句类别确定问答场景;
40、响应于所述问句类别与图像场景标签不匹配,确定所述问答场景为用户自定义场景。
41、本申请提供的显示设备及视觉问答方法的有益效果包括:
42、本申请实施例在预测出用户问句的问句类别和截屏图像的图像场景标签后,通过将图像场景标签与问句类别进行匹配,根据匹配结果确定问答场景,基于问答场景确定回复策略,进而生成问答结果,通过图像场景标签与问句类别的匹配结果表征用户问句与截屏图像的关联度,实现了根据用户问句与截屏图像的关联度确定回复策略,提高了问答结果的准确性,提升了视觉问答体验。
技术特征:
1.一种显示设备,其特征在于,包括:
2.根据权利要求1所述的显示设备,其特征在于,所述根据所述图像场景标签与问句类别的匹配结果确定问答场景,包括:
3.根据权利要求2所述的显示设备,其特征在于,所述根据所述问句类别确定问答场景,包括:
4.根据权利要求3所述的显示设备,其特征在于,所述根据所述问答场景对应的回复策略生成所述视觉问答指令对应的问答结果,包括:
5.根据权利要求1所述的显示设备,其特征在于,所述预测所述截屏图像的图像场景标签,包括:
6.根据权利要求5所述的显示设备,其特征在于,所述将所述融合标签中属于同一场景的标签进行融合,得到图像场景标签,包括:
7.根据权利要求1所述的显示设备,其特征在于,所述预测所述用户问句的问句类别,包括:
8.根据权利要求7所述的显示设备,其特征在于,所述根据所述图像场景标签与问句类别的匹配结果确定问答场景,包括:
9.一种视觉问答方法,其特征在于,包括:
10.根据权利要求9所述的视觉问答方法,其特征在于,所述根据所述图像场景标签与问句类别的匹配结果确定问答场景,包括:
技术总结
本申请提供了一种显示设备及视觉问答方法,显示设备包括:显示器;控制器,控制器被配置为:接收视觉问答指令,所述视觉问答指令包括截屏图像和用户问句;响应于所述视觉问答指令,预测所述用户问句的问句类别,并预测所述截屏图像的图像场景标签;根据所述图像场景标签与问句类别的匹配结果确定问答场景;根据所述问答场景对应的回复策略生成所述视觉问答指令对应的问答结果。本申请提高了视觉问答体验。
技术研发人员:柳杰
受保护的技术使用者:海信电子科技(武汉)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!