基于MLIR的FPGA神经网络模型部署方法与流程
本申请实施例涉及fpga,特别涉及一种基于mlir的fpga神经网络模型部署方法。
背景技术:
1、近年来,随着深度学习的快速发展和应用,对神经网络模型部署也越来重要。目前没有高效的方案将深度学习模型部署到fpga平台。让深度学习模型能够在fpga上去运行,目前最普遍采用的是硬件寄存器传输语言(rtl)verilog来完成的,但是这门语言的生产效率甚至低于c或c++,更不用说模型描述语言python、lua等等,因此在编程这方面,维护程序功能正确可能会占用软件的大部分成本,同时在rtl编程这方面的负担会更大,业界也一直在探索如何使用领域专用语言与系统的协同设计可以降低fpga的编程难度。
2、其中xilinx平台提供了一套vitis工具给用户部署模型。但是该工具闭源且开放性不够,有很多操作无法通过xilinx部署,很多模型中的运算符号该工具不支持,因此大大增加了部署模型的难度,同时就算是采用替代运算符号,精度也会大大损失而导致几乎不可用。
技术实现思路
1、本申请实施例提供一种基于mlir的fpga神经网络模型部署方法,解决神经网络模型部署效率低下和编程难度稿的问题,所述方法包括:
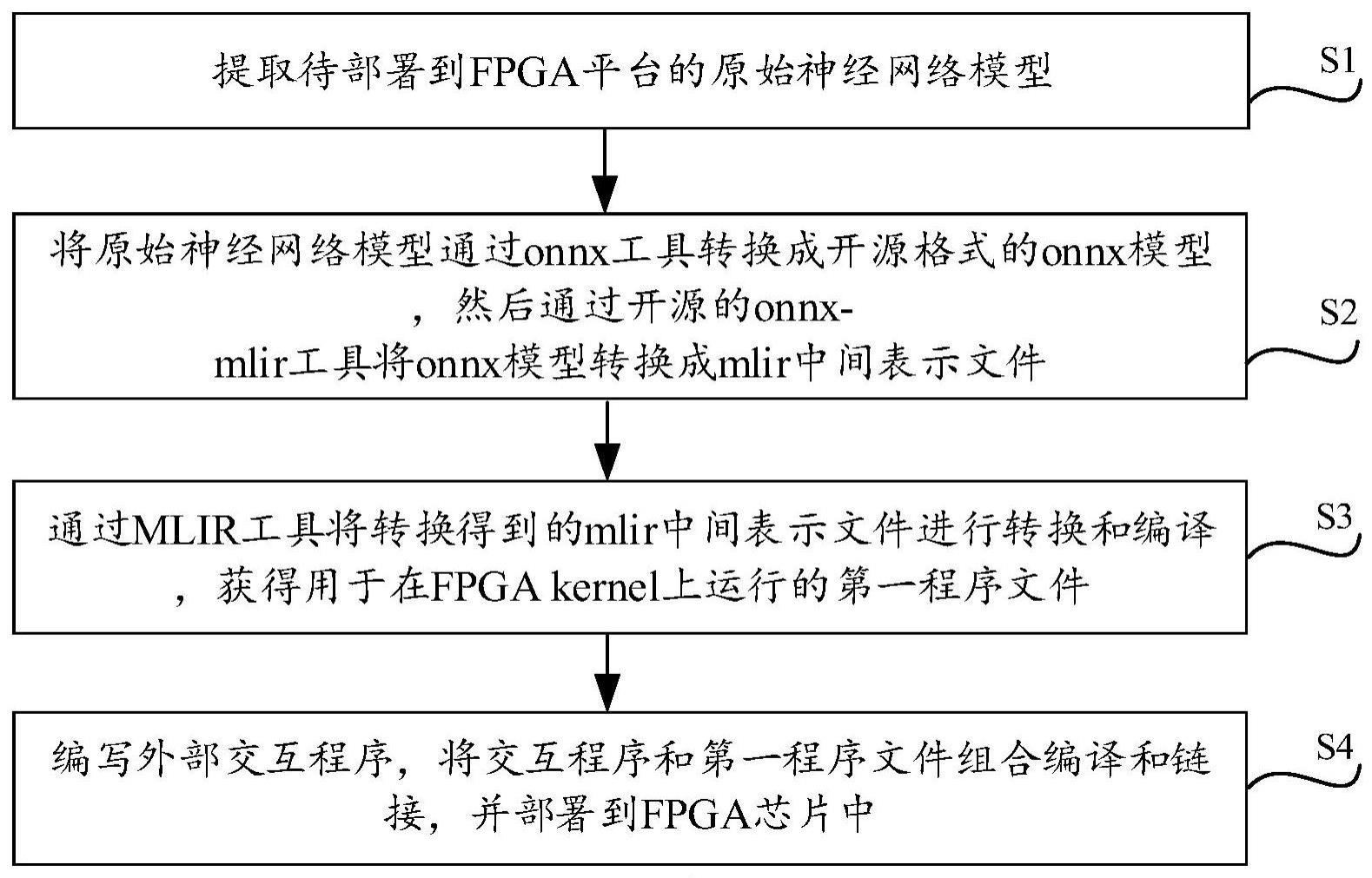
2、s1,提取待部署到fpga平台的原始神经网络模型;
3、s2,将所述原始神经网络模型通过onnx工具转换成开源格式的onnx模型,然后通过开源的onnx-mlir工具将所述onnx模型转换成mlir中间表示文件;
4、s3,通过mlir工具将转换得到的所述mlir中间表示文件进行转换和编译,获得用于在fpga kernel上运行的第一程序文件;所述第一程序文件为高级语言,用于操作fpga芯片;
5、s4,编写外部交互程序,将所述交互程序和所述第一程序文件组合编译和链接,并部署到fpga芯片中。
6、具体的,所述原始神经网络模型基于tensorflow框架、pytorch框架或mxnet框架,并使用python语言编写;模型类型为caffe模型、chainer模型、coreml模型、keras模型、libsvm模型、lightgbm模型或scikit-learn模型。
7、具体的s3包括:
8、s31,将所述mlir中间表示文件通过mlir-opt下沉转换为llvm中间表示文件,所述llvm中间表示文件是低级的中间语言表达文件;
9、s32,通过llvm工具将所述llvm中间表示文件进行编译,生成所述第一程序文件以及用于操作fpga芯片内核的调用函数。
10、具体的,llvm工具是若干组模块化、可重用的编译器,以及工具链技术组合的低级虚拟机;s32包括:
11、确定运行终端的类型,并通过其中的clang编译器将所述llvm中间表示文件编译为动态链接库;所述动态链接库中包含有驱动fpga芯片的所有驱动代码和执行计算的运算函数,运算函数至少包括加减乘除及组合操作、卷积操作、池化操作,且运算函数仅由四则运算的组合构成;
12、将所述动态链接库编译为所述第一程序文件并提供操作动态库内部方法的入口函数。
13、具体的,生成运算函数过程包括:
14、通过mlir中的linalg指令将所述llvm中间表示文件中待转换的计算函数进行重定义;
15、通过mlir-opt conv1.mlir-linalg-bufferize-arith-bufferize-tensor-bufferize-func-bufferize-finalizing-bufferize-buffer-deallocation-convert-linalg-to-loops-convert-scf-to-cf-convert-linalg-to-llvm指令,将待转换的计算函数转换为仅由四则运算组合而成的运算函数;且仅由四则运算组合而成的运算函数直接用于fpga核心运行。
16、具体的,s4包括:
17、s41,确定原始神经网络模型的模型参数和执行运算函数的输入数据;
18、s42,编写程序入口函数并生成可执行文件,通过gcc编译器编译所述第一程序文件和可执行文件,将其部署到具有fpga芯片的终端设备上。
19、具体的,所述gcc编译器的编译过程包括:
20、根据fpga核心、输入数据和运算函数生成目标计算操作的目标编译代码;所述目标编译代码为操作fpga核心的写操作函数,用于直接将数据矩阵传递到对应的fpga核心;fpga核心至少包括卷积核心、乘法核心、除法核心、加法核心、减法核心以及池化核心,分别用于执行相应的计算。
21、具体的,所述gcc编译器还生成有对应写操作的读操作函数,当fpga核心接收并计算完成后,通过传入读操作函数获取计算结果。
22、本申请实施例提供的技术方案带来的有益效果至少包括:将原始神经网络模型通过onnx工具将其转换为开源的onnx模型后,将其开放化,方便通过onnx-mlir工具将onnx模型转换成mlir文件;进而就可以通过本方案设计的mlir-opt将其转换为低级的中间语言表达文件,然后通过组合的llvm工具建议转化为可以直接载入并在fpga kernel上运行的第一程序文件,这样在执行部署操作时,就可以直接通过外部写入一些少量的交互程序将第一程序文件组合编译写入到fpga设备上,整个过程不在需要写入低效率的rtl文件,提高部署效率的同时,也有利于fpga的高效执行。
技术特征:
1.一种基于mlir的fpga神经网络模型部署方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于mlir的fpga神经网络模型部署方法,其特征在于,所述原始神经网络模型基于tensorflow框架、pytorch框架或mxnet框架,并使用python语言编写;模型类型为caffe模型、chainer模型、coreml模型、keras模型、libsvm模型、lightgbm模型或scikit-learn模型。
3.根据权利要求2所述的基于mlir的fpga神经网络模型部署方法,其特征在于,s3包括:
4.根据权利要求3所述的基于mlir的fpga神经网络模型部署方法,其特征在于,llvm工具是若干组模块化、可重用的编译器,以及工具链技术组合的低级虚拟机;s32包括:
5.根据权利要求4所述的基于mlir的fpga神经网络模型部署方法,其特征在于,生成运算函数过程包括:
6.根据权利要求5所述的基于mlir的fpga神经网络模型部署方法,其特征在于,s4包括:
7.根据权利要求6所述的基于mlir的fpga神经网络模型部署方法,其特征在于,所述gcc编译器的编译过程包括:
8.根据权利要求7所述的基于mlir的fpga神经网络模型部署方法,其特征在于,所述gcc编译器还生成有对应写操作的读操作函数,当fpga核心接收并计算完成后,通过传入读操作函数获取计算结果。
技术总结
本申请公开基于MLIR的FPGA神经网络模型部署方法,涉及FPGA领域,提取待部署到FPGA平台的原始神经网络模型;将原始神经网络模型通过onnx工具转换成开源格式的onnx模型,然后通过开源的onnx‑mlir工具将onnx模型转换成mlir中间表示文件;通过MLIR工具将转换得到的mlir中间表示文件进行转换和编译,获得用于在FPGA kernel上运行的第一程序文件;第一程序文件为高级语言,用于操作FPGA芯片;编写外部交互程序,将交互程序和第一程序文件组合编译和链接,部署到FPGA芯片中。该方案避免编写低效的RTL相关模型代码,高效地将深度神经网络模型运行在FPGA上,提高部署效率。
技术研发人员:请求不公布姓名
受保护的技术使用者:深存科技(无锡)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!