一种基于视频序列和预训练实例分割的无监督单目三维目标检测方法
本发明涉及目标检测领域,提出了一种基于视频序列和预训练实例分割的无监督单目三维目标检测方法。
背景技术:
1、随着深度学习的发展,许多计算机视觉相关的任务都打破了传统方法的局限并得到了突破性的发展,例如新兴的自动驾驶领域,依靠着目标检测、场景语义理解等上游任务的高度精确性、可靠性,人们可以尝试通过例如三维目标检测这样的手段,完成对自动驾驶方面的相关控制。三维目标检测任务根据传感器输入数据的形式不同,可以大致分为三个流派:激光雷达式、多目式和单目式的三维目标检测。其中,单目三维目标检测的任务是指在只有单目图像作为数据输入的情况下,结合相机的参数,完成图像中目标在三维空间下的检测。
2、在这些形式中,激光雷达虽然精度较高,但是仪器价格高昂且探测距离受限,往往还需要结合多目相机共同完成一个自动驾驶传感系统的搭建,例如当今tesla、百度apollo等企业都已经有了较为成熟的多目结合激光雷达的方案。然而,如果一个自动驾驶系统能够仅仅依赖单目相机完成目标的三维检测,那么将会大大节约成本,并具有极高的推广性,这也成为了当前三维目标检测的重点和研究热点。
3、然而,单目三维目标检测存在以下几个挑战:(1)单目图像包含的信息较少,仅有rgb三个通道的颜色信息,缺乏像激光雷达或是多目图像能够获取到的空间深度信息,如何估计物体的距离、像素点的深度将是此问题的关键;(2)目前已有的三维目标检测公开数据集通常面向自动驾驶领域,图像的风格仅限于国外的乡村地区和城镇地区,将训练好的模型应用于新的场景时,其泛化性能不能得到有效保证;(3)获取一个物体真实的三维检测包围框通常需要先获取其激光雷达信息,再雇佣专业的标注人员在雷达场景下对物体进行标注,所需成本较大。目前,开发出一种在新场景下无需标注即可获得三维检测包围框的无监督方法,仍是较大的挑战。
4、为了有效提升单目三维目标检测的精确度,本方法基于视频的序列特点挖掘更多信息,并借助预训练好的实例分割网络模型来共同构建一个无需标签信息、具有良好泛化性的三维目标检测网络。
技术实现思路
1、为了有效减少三维目标检测任务在一个新场景中的高额标注开支,本发明通过利用视频连续帧之间的运动信息和在其他数据集中预训练好的实例分割网络,可以无监督地生成图像的三维目标检测包围框。
2、为实现上述目的,本发明采用的技术方案流程如下:
3、一种基于视频序列和预训练实例分割的无监督单目三维目标检测方法,其特征在于包括以下步骤:
4、(1)获取相机内参矩阵;
5、(2)使用该相机,拍摄某个场景下一定长度的视频序列帧;
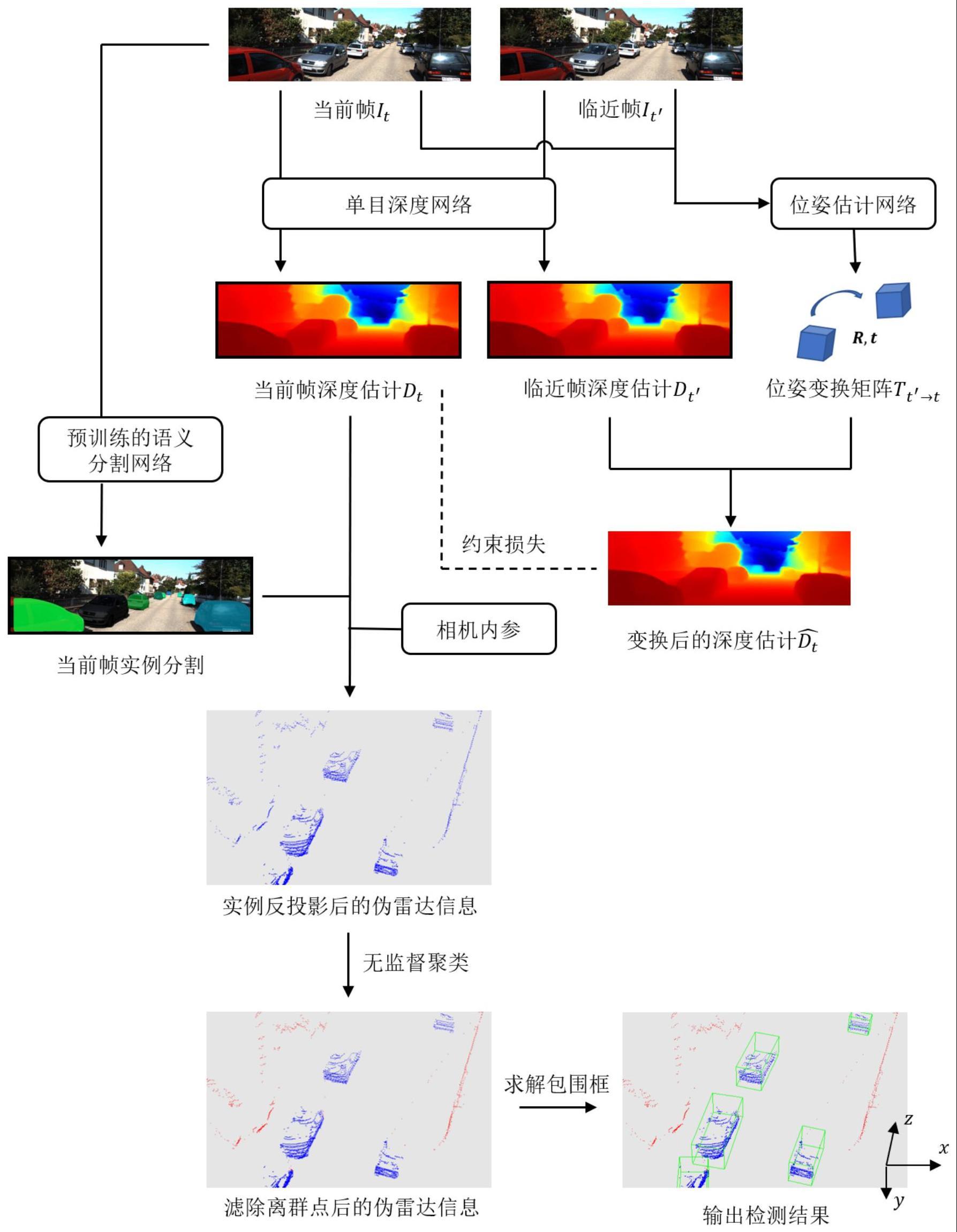
6、(3)通过自监督单目深度网络,利用序列图像之间的投影关系,自监督地训练学习,得到序列图像的单目深度估计值;
7、(4)通过预训练的实例分割网络,对图像直接预测得到其实例分割结果;
8、(5)将得到的实例分割结果,结合步骤(3)学习到的单目深度估计值,以及步骤(1)获取的相机内参矩阵,反投影至三维空间中,得到每个实例的区域三维点集;
9、(6)利用无监督聚类方法对每个实例的区域三维点集进行聚类,进一步滤除离群点,得到实例主体三维点集,随后在bev(bird’s eye view,鸟瞰视角)中求解实例主体三维点集的最小外接矩形,得到其x-z平面的二维包围框,并求取实例主体三维点集的y轴方向最大-最小高度差,将y轴方向最大-最小高度差作为y轴高度,最终得到物体的三维检测包围框。
10、如上所述的方法,其特征在于步骤(3)中通过自监督单目深度网络,利用序列图像之间的投影关系得到序列图像的单目深度估计值,其具体过程为:先预测当前帧和临近帧的单目深度估计值和位姿变换矩阵,再将临近帧的单目深度估计值进行位姿变换,得到临近帧位姿变化后的单目深度估计值,将其与当前帧的单目深度估计计算损失,以实现自监督的训练学习。
11、如上所述的方法,其特征在于步骤(4)中所使用的预训练实例分割网络,在其预训练过程使用的数据集应该包含三维目标检测任务所需检测目标类别,并具有良好的泛化性能。
12、如上所述的方法,其特征在于步骤(5)中实例分割结果,结合单目深度估计值、相机内参矩阵反投影的具体过程为:将实例分割后的像素点p转化为齐次坐标形式p=(u,v,1),其中u,v为像素点在二维图像上的以像素为单位的横纵坐标;将步骤(3)中得到的单目深度估计dp=dt(p),结合步骤(1)得到的相机内参矩阵k,计算得到像素点p在三维场景中的坐标(u,v,w,1)t=k-1dp(u,v,1)t,其中u,v,w分别对应相机坐标系下x,y,z轴上的坐标值,该坐标值以米为单位,最终得到每个实例的区域三维点集。
13、如上所述的方法,其特征在于步骤(6)将每个实例的区域三维点集转化为实例主体三维点集,并进一步计算三维包围框的具体过程为:首先对每个实例的区域三维点集应用无监督聚类算法,得到多个聚类簇;取点数量最多的聚类簇作为实例主体三维点集,其他聚类簇所包含的点作为离群点进行点的去除;基于y轴方向求取实例主体三维点集的最大值和最小值,将两者差值作为三维包围框的y轴高度,同时在实例主体三维点集所对应的x-z平面上求解最小外接矩形,最终得到三维包围框。
14、如上所述的方法,其特征在于:对每个当前帧的临近帧,优选为当前帧的下一帧,对自监督单目深度估计网络,优选为sfm-learner、monodepth系列、sc-depth或packnet网络结构,其中用于位姿估计的网络优选为输入层通道数修改为6的resnet-18网络。
15、如上所述的方法,其特征在于:实例分割网络预训练的数据集优选mscoco数据集,网络优选mask r-cnn网络结构;对于实例分割后得到的结果,进一步优选类别置信度大于等于0.5、包围框内部像素置信度大于等于0.5的像素区域,得到最终的实例分割结果。
16、如上所述的方法,其特征在于:对于每个实例的区域三维点集进行无监督聚类的算法,优选dbscan算法,算法参数中邻域半径e优选为0.8米,邻域内最小样本数minpts优选为10个;对于满足物体垂直于地面假设的类别,实例主体三维点集在x-z平面上求解最小外接矩阵的过程,优选旋转卡壳算法。
技术特征:
1.一种基于视频序列和预训练实例分割的无监督单目三维目标检测方法,其特征在于,包括以下步骤:
2.如权利要求1所述的一种基于视频序列和预训练实例分割的无监督单目三维目标检测方法,其特征在于步骤(3)中通过自监督单目深度网络,利用序列图像之间的投影关系得到序列图像的单目深度估计值,其具体过程为:先预测当前帧和临近帧的单目深度估计值和位姿变换矩阵,再将临近帧的单目深度估计值进行位姿变换,得到临近帧位姿变化后的单目深度估计值,将其与当前帧的单目深度估计计算损失,以实现自监督的训练学习。
3.如权利要求1所述的一种基于视频序列和预训练实例分割的无监督单目三维目标检测方法,其特征在于步骤(4)中所使用的预训练实例分割网络,在其预训练过程使用的数据集应该包含三维目标检测任务所需检测目标类别,并具有良好的泛化性能。
4.如权利要求1所述的一种基于视频序列和预训练实例分割的无监督单目三维目标检测方法,其特征在于步骤(5)中实例分割结果,结合单目深度估计值、相机内参矩阵反投影的具体过程为:
5.如权利要求1所述的一种基于视频序列和预训练实例分割的无监督单目三维目标检测方法,其特征在于步骤(6)将每个实例的区域三维点集转化为实例主体三维点集,并进一步计算三维包围框的具体过程为:
6.如权利要求2所述的一种基于视频序列和预训练实例分割的无监督单目三维目标检测方法,其特征在于:对每个当前帧的临近帧,优选为当前帧的下一帧,对自监督单目深度估计网络,优选为sfm-learner、monodepth系列、sc-depth或packnet网络结构,其中用于位姿估计的网络优选为输入层通道数修改为6的resnet-18网络。
7.如权利要求3所述的一种基于视频序列和预训练实例分割的无监督单目三维目标检测方法,其特征在于:
8.如权利要求5所述的一种基于视频序列和预训练实例分割的无监督单目三维目标检测方法,其特征在于:
9.一种非临时性计算机可读存储介质,其特征在于,所述计算机可读存储介质中包括一种基于视频序列和预训练实例分割的无监督单目三维目标检测方法程序,所述基于视频序列和预训练实例分割的无监督单目三维目标检测方法程序被处理器执行时,实现如权利要求1至8中任一项所述的基于视频序列和预训练实例分割的无监督单目三维目标检测方法。
技术总结
本发明提出一种基于视频序列和预训练实例分割的无监督单目三维目标检测方法。其主要步骤为,使用已知内参的相机拍摄某个场景下一定长度的视频序列帧,再利用序列图像之间的投影关系自监督地训练单目深度网络,学习序列图像的单目深度估计值;随后通过预训练好的实例分割网络对图像直接预测其实例分割结果,将得到的实例分割结果结合相机内参和学习好的单目深度估计值反投影至三维空间中,得到每个实例的伪雷达数据;最后利用无监督聚类方法滤除离群点,在鸟瞰视角(x‑z平面)求解点集的最小外接矩形,y轴方向求解点集的最大‑最小高度差,最终得到物体的三维目标检测包围框。本发明利用视频前后帧的序列信息和预训练的实例分割网络,能够在完全无人工标注的情况下完成对任何新场景的三维目标检测,能够显著降低对新场景三维目标检测学习所需的人工标注成本。
技术研发人员:百晓,范嘉楠,郑锦
受保护的技术使用者:北京航空航天大学
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!