一种基于视角自适应的复杂场景下人群计数方法
本发明涉及信号处理,具体涉及一种基于视角自适应的复杂场景下人群计数方法。
背景技术:
1、经过长时间的发展,人群计数领域出现了许多新颖的发明,主流的发明使用基于密度图的方法来估计人群的数量,除了全监督学习方法外,半监督、弱监督和基于变压器的学习方法也被提出并逐渐成为近年来的发明研究的热点。但现有的这些方法都没有考虑复杂自然场景下的视角变化问题,他们无法消除高度差异带来的影响,同时也无法解决数据标签化导致的错误。
2、因此,有必要通过改进数据标签方法来提出一种视角适应的人群计数方法。
技术实现思路
1、本发明的目的是提供一种基于视角自适应的复杂场景下人群计数方法,以解决背景技术中不足。
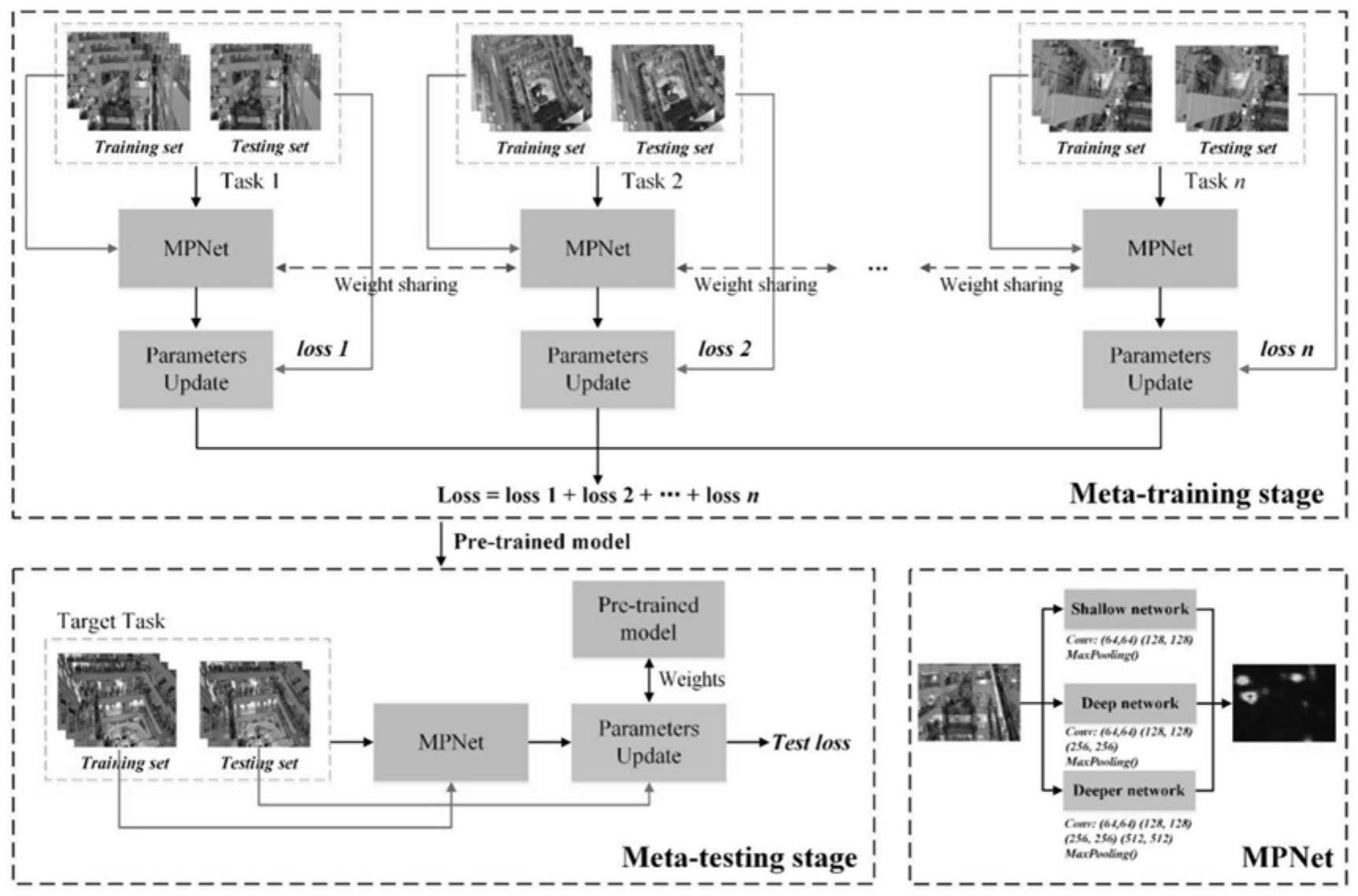
2、为了实现上述目的,本发明提供如下技术方案:一种基于视角自适应的复杂场景下人群计数方法,所述计数方法包括以下步骤:
3、s1:noomp框架通过少样本学习方法拟合自然世界;
4、s2:noomp框架通过元学习训练使视角适应多头并行网络作为noomp框架的主干;
5、s3:视角适应多头并行网络用于估计人群的密度图;
6、s4:视角适应多头并行网络在多个不同的场景中进行训练,并将子损失进行汇总。
7、优选的,步骤s1中,少样本学习方法包括元训练和元测试,还包括以下步骤:
8、s1.1:在训练阶段训练一个预先训练好的模型;
9、s1.2:在目标场景中使用标记的图像对模型进行微调。
10、优选的,所述元训练用于将与训练的模型mpre对一系列参数ln={l1,l2,l3,.....,ln}进行学习,每一个训练任务中,参数集合ln通过小批量梯度下降法进行更新,n个任务的损失函数和优化函数如等式(1)、(2)所示:
11、
12、
13、在每个任务中,子损失计算为在n个任务中,子损失被累加,对于一个任务中的图像,y(i)表示地面实况密度图,估计的密度图表示为
14、优选的,所述元测试用于将预训练的模型mpre放在目标场景中进行微调,在新场景下的损失函数计算如等式(3)所示:
15、
16、对于目标任务场景与之间存在巨大的特征差距。
17、优选的,步骤s3中,估计人群的密度图包括以下步骤:
18、s3.1:为图像中的一个人标注两个点,方差σi估计头部大小;
19、s3.2:对于路人pn,一个点位于其头的顶部,另一个点位于其头的中心,距离dn使用加权欧氏距离等式(5)来计算:
20、
21、通过距离dn来计算方差σn,其公式为等式(6):
22、σn=(dn+a)*λ(6)
23、常数a表示为距离dn的偏差,λ为超参数,且λ=2.5。
24、优选的,步骤s2包括以下步骤:
25、s2.1:初始图像i发送到视角适应多头并行网络中,大小为1024*768,i是对i1,i2,和i3的复制,三个输入对应三个不同的并行分支;
26、s2.2:i1输入到包含四个卷积层的浅网络中,i2和i3输入到更深的网络中,网络分别包含7和10个卷积层;
27、s2.3:fh1(),fh2()和fh3()表示前端网络,表示为等式(7):
28、
29、上式中,函数o表示每个分支的卷积层,wn表示不同的卷积运算,r表示relu激活函数,m表示max_pooling操作,采用3*3内核。
30、优选的,步骤s2还包括以下步骤:
31、s2.4:在前端分支之后,得到三种特征图和特征包含不同维度的信息;
32、不同维度的信息包括浅层网络中的颜色和纹理信息和深层网络中的语义信息;
33、s2.5:使用1*1内核的卷积层,对于和添加两个卷积层,内核大小为1*1;
34、s2.6:使用自适应平均池操作得到增强的特征和
35、s2.7:使用concat()操作收集特征和
36、优选的,还包括
37、s5:通过平均绝对误差和均方根误差评价noomp框架,表达式为等式(8)和等式(9):
38、
39、
40、n表示测试图像的总数,对于测试图像xi,参数yi表现地面实况,参数表示估计结果。
41、在上述技术方案中,本发明提供的技术效果和优点:
42、1、本发明中,由于日常生活中常见的场景通常都是有高度差的,这使得人群计数需要在复杂视角下进行。因此本发明提出一种新的标记方法,绝对几何高斯生成方法(absolute-geometry gaussian generation)。该方法只需对图像中的每个人增加一个点,便能获得较好的精度;
43、2、本发明noomp框架采用了元学习与少样本的方式来训练计数模型。这使得发明能够在有效的实现视角自适应的同时,也解决标签成本过高的问题;
44、3、本发明提出了一种新的用于noomp的多头并行网络(mpnet)来提取人群特征。mpnet是一种由浅层网络和深层网络组成的混合结构。该网络有效地保留了浅层网络和深层网络的特征,使mpnet在noomp中具有良好的性能;
45、4、本发明收集了一个新的用于noomp的数据集。该数据集名为商场多重高度差异(multiple height differences in mall(mhdm))数据集。其包含来自购物中心和超市的图像。这些图像具有不同视角和高度差异。基于mhdm和其他基准测试的实验表明,noomp框架具有良好的精度,能够很好地解决视角变化问题。
技术特征:
1.一种基于视角自适应的复杂场景下人群计数方法,其特征在于:所述计数方法包括以下步骤:
2.根据权利要求1所述的一种基于视角自适应的复杂场景下人群计数方法,其特征在于:步骤s1中,少样本学习方法包括元训练和元测试,还包括以下步骤:
3.根据权利要求2所述的一种基于视角自适应的复杂场景下人群计数方法,其特征在于:所述元训练用于将与训练的模型mpre对一系列参数ln=[l1,l2,l3,.....,ln}进行学习,每一个训练任务中,参数集合ln通过小批量梯度下降法进行更新,n个任务的损失函数和优化函数如等式(1)、(2)所示:
4.根据权利要求2所述的一种基于视角自适应的复杂场景下人群计数方法,其特征在于:所述元测试用于将预训练的模型mpre放在目标场景中进行微调,在新场景下的损失函数计算如等式(3)所示:
5.根据权利要求1所述的一种基于视角自适应的复杂场景下人群计数方法,其特征在于:步骤s3中,估计人群的密度图包括以下步骤:
6.根据权利要求5所述的一种基于视角自适应的复杂场景下人群计数方法,其特征在于:步骤s2包括以下步骤:
7.根据权利要求6所述的一种基于视角自适应的复杂场景下人群计数方法,其特征在于:步骤s2还包括以下步骤:
8.根据权利要求1-7任一项所述的一种基于视角自适应的复杂场景下人群计数方法,其特征在于:还包括
技术总结
本发明公开了一种基于视角自适应的复杂场景下人群计数方法,所述计数方法包括以下步骤:NOOMP框架通过少样本学习方法拟合自然世界;NOOMP框架通过元学习训练使视角适应多头并行网络作为NOOMP框架的主干;视角适应多头并行网络用于估计人群的密度图;视角适应多头并行网络在多个不同的场景中进行训练,并将子损失进行汇总。本发明提出一种新的标记方法,绝对几何高斯生成方法,该方法只需对图像中的每个人增加一个点,便能获得较好的精度。
技术研发人员:闵卫东,邹怡,赵浩宇,李伟铭
受保护的技术使用者:南昌大学
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!