网格深度强化学习模型构建方法及应用方法与流程
本发明属于机器学习,尤其是涉及一种网格深度强化学习模型构建方法及应用方法。
背景技术:
1、大数据时代应用场景对于无人机路径规划方法提出了智能化发展、复杂场景的处理和场景中各类数据的高效组织、管理与表达三点新需求。现有的路径规划算法有a*算法、人工势场法、rrt算法、深度强化学习算法等等。在geosot编码体系应用愈加广泛的趋势下,a*算法等方法已经与其实现结合,且已证明geosot编码体系加入的有效性。与此同时,深度强化学习在路径规划领域的研究愈发火热,有着超越传统算法的效能。但是深度强化学习与geosot编码体系仍未实现有效结合,geosot编码体系在深度强化学习领域能够发挥的优势亟待探索。
2、深度强化学习模型普遍存在训练不稳定问题。在无人机路径规划任务中,训练不稳定问题可能是致命的。有的任务对时间要求比较紧迫,比如灾难救援的场景下,这个时候时间因素不满足深度强化学习算法进行多次训练,而要求尽可能地一次成功。
3、现有的路径规划环境框架主要有局部单一网格体系、经纬度体系和全球剖分网格体系三种。局部单一尺度网格体系作为无人机路径规划环境框架存在“局部”和“单一尺度”两个问题。经纬度体系作为无人机路径规划环境框架存在难以描述区域性特征、难以关联多图层数据和计算复杂度较高三个问题。以上两种体系的问题可以总结为低效性问题(消耗时间与资源)和数据关联与表达困难问题。
技术实现思路
1、针对现有技术中存在的问题,本发明提供了一种网格深度强化学习模型构建方法及应用方法,至少部分的解决现有技术中存在的路径规划应用中与深度强化学习结合不稳定的问题。
2、第一方面,本公开实施例提供了一种网格深度强化学习模型构建方法,包括:
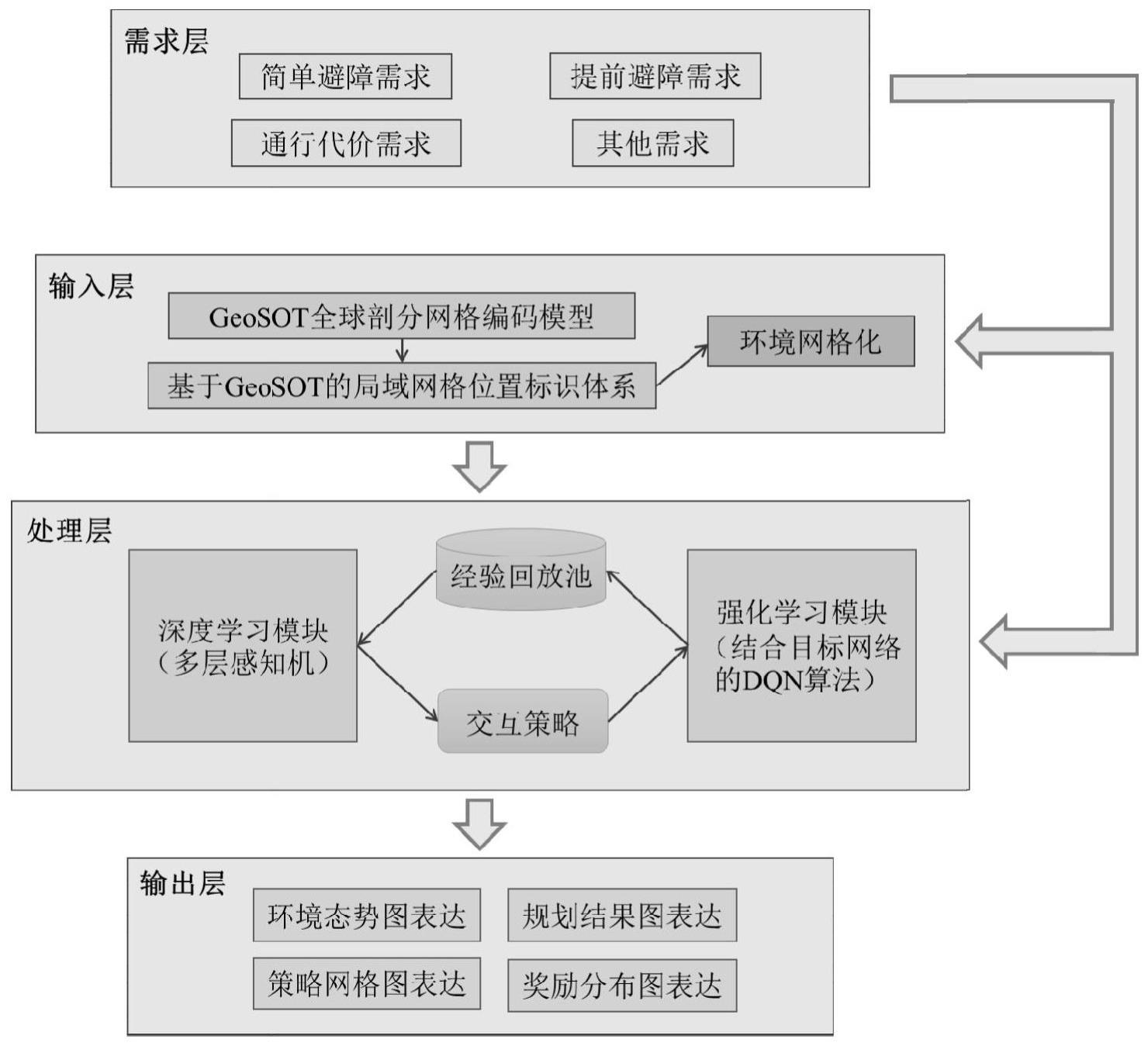
3、基于获取路径规划任务场景和需求构建模型的需求层;
4、采用geosot全球剖分网格编码模型对环境数据进行组织与管理得到输入层;
5、基于深度学习模块、强化学习模块和经验回放池构建处理层;
6、基于环境态势图、规划结果图、策略网格图和奖励分布图构建输出层;
7、输入层和处理层基于需求层的任务需求进行修改;
8、所述处理层对输入层的数据进行处理后经输出层输出。
9、第二方面,本公开实施例还提供了一种网格深度强化学习模型应用方法,基于第一方面任一所述方法构建的网格深度强化学习模型,包括:
10、明确路径规划任务需求;
11、根据路径规划任务的因素确定相应经纬度区域的局域网格编码集合和相应经纬度区域在相应层级的确定的网格层级中包含的数据;
12、确定强化学习框架和经验回放池;
13、确定深度学习模块中的深度学习神经网络;
14、基于确定的深度学习神经网络训练网格深度强化学习模型;
15、基于训练的网格深度强化学习模型、相应经纬度区域的局域网格编码集合和网格层级中包含的数据得到规划结果。
16、本发明提供的网格深度强化学习模型构建方法,基于geosot全球剖分网格编码体系,采取改进网络输入形式,构建了面向路径规划的、更稳定的智能化深度强化学习网格模型,形成“需求-输入-处理-输出”的工作流程,为路径规划应用提供与深度强化学习相结合的智能模型,从而达到在路径规划应用中与深度强化学习稳定结合的目的。
技术特征:
1.一种网格深度强化学习模型构建方法,其特征在于,包括:
2.根据权利要求1所述的网格深度强化学习模型构建方法,其特征在于,
3.根据权利要求1所述的网格深度强化学习模型构建方法,其特征在于,所述基于深度学习模块、强化学习模块和经验回放池构建处理层,包括:
4.根据权利要求1所述的网格深度强化学习模型构建方法,其特征在于,
5.根据权利要求1所述的网格深度强化学习模型构建方法,其特征在于,
6.一种网格深度强化学习模型应用方法,基于权利要求1至5任一所述方法构建的网格深度强化学习模型,其特征在于,包括:
7.根据权利要求6所述的网格深度强化学习模型应用方法,其特征在于,
8.根据权利要求6所述的网格深度强化学习模型应用方法,其特征在于,
9.根据权利要求6所述的网格深度强化学习模型应用方法,其特征在于,所述确定深度学习模块中的深度学习神经网络,包括:
10.根据权利要求6所述的网格深度强化学习模型应用方法,其特征在于,所述训练网格深度强化学习模型,包括:
11.根据权利要求7所述的网格深度强化学习模型应用方法,其特征在于,所述根据环境数据的空间属性,构造该经纬度区域的剖分索引大表;确定该经纬度区域在该层级的确定的网格层级中包含的数据中的剖分索引大表,
12.根据权利要求11所述的网格深度强化学习模型应用方法,其特征在于,所述网格是否属于障碍物区域中采用面积占比法确定网格的可通行性;所述面积占比法,包括设定阈值为ε,在二维平面中,如果障碍物的面积大于ε,则网格不可通行,标记为1;如果障碍物的面积小于等于ε,则网格可通行,标记为0。
13.根据权利要求6所述的网格深度强化学习模型应用方法,其特征在于,所述确定强化学习框架,包括:
14.根据权利要求12所述的网格深度强化学习模型应用方法,其特征在于,所述奖励函数设置包括:
15.根据权利要求14所述的网格深度强化学习模型应用方法,其特征在于,奖励函数与当前网格n距终点区域的曼哈顿距离呈负相关,当前点距离终点的曼哈顿距离越小,奖励值越大。
16.根据权利要求13所述的网格深度强化学习模型应用方法,其特征在于,所述确定强化学习框架,还包括定义行进策略与探索策略,
技术总结
本发明提供了一种网格深度强化学习模型构建方法及应用方法,其中网格深度强化学习模型构建方法,包括:基于获取路径规划任务场景和需求构建模型的需求层;采用GeoSOT全球剖分网格编码模型对环境数据进行组织与管理得到输入层;基于深度学习模块、强化学习模块和经验回放池构建处理层;基于环境态势图、规划结果图、策略网格图和奖励分布图构建输出层;输入层和处理层基于需求层的任务需求进行修改;所述处理层对输入层的数据进行处理后经输出层输出。形成“需求‑输入‑处理‑输出”的工作流程,为路径规划应用提供与深度强化学习相结合的智能模型,从而达到在路径规划应用中与深度强化学习稳定结合的目的。
技术研发人员:刘杰,任伏虎,徐谦,伍学民,王丽娜
受保护的技术使用者:北斗伏羲中科数码合肥有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!