一种面向长文本的文本匹配方法及系统与流程
本发明涉及计算机,尤其是涉及一种面向长文本的文本匹配方法及系统。
背景技术:
1、文本匹配作为社区问答、信息检索和对话系统等自然语言处理应用中一项关键任务,旨在分析和判断源文本与目标文本之间的语义关联。长文本匹配是文本匹配领域中的一个重要子方向,可以迅速判断两个篇章之间的关系,鉴别二者主题表达相似与否,具有重大的研究与应用价值。
2、文本匹配模型有两种解决思路:传统模型和深度模型。传统模型的解决思路:通过人工定义和抽取特征,并以抽取特征衡量文本匹配程度。此方法存在人工提取特征成本高、提取特征不全面等问题。并且,其本质上是一种表层匹配方法,无法实现更深层次语义匹配任务。
3、基于深度模型的解决思路:利用深度神经网络强大的语言表征能力对文本进行编码,挖掘文本深度语义信息,在语义空间中进行匹配操作。此方法无需人工设定特征,能够达到较高准确率。目前,多数深度模型为针对短文本设计(即短文本深度匹配模型),长文本间细粒度匹配信号通常较为稀疏。利用短文本深度匹配模型匹配长文本时,难以从大量噪声信号中识别出匹配信号,导致匹配效果不理想。
技术实现思路
1、为了克服现有技术的上述缺点,本发明提供了一种面向长文本的文本匹配方法及系统。
2、本发明解决其技术问题所采用的技术方案是:一种面向长文本的文本匹配方法,所述文本匹配方法包括以下步骤:
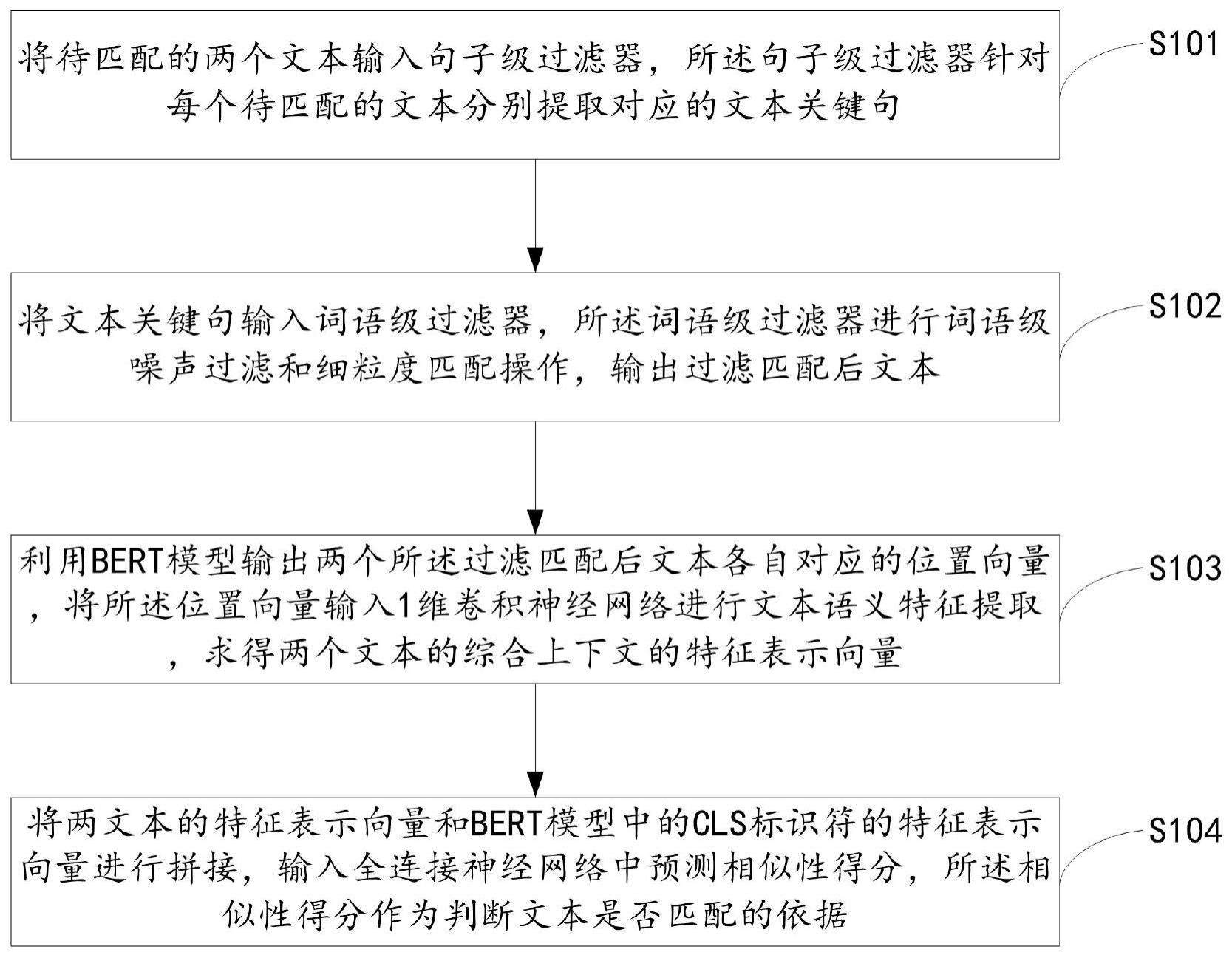
3、将待匹配的两个文本输入句子级过滤器,所述句子级过滤器针对每个待匹配的文本分别提取对应的文本关键句;
4、将文本关键句输入词语级过滤器,所述词语级过滤器进行词语级噪声过滤和细粒度匹配操作,输出过滤匹配后文本;
5、利用bert模型输出两个所述过滤匹配后文本各自对应的位置向量,将所述位置向量输入1维卷积神经网络进行文本语义特征提取,求得两个文本的综合上下文的特征表示向量;
6、将两文本的特征表示向量和bert模型中的cls标识符的特征表示向量进行拼接,输入全连接神经网络中预测相似性得分,所述相似性得分作为判断文本是否匹配的依据。
7、进一步地,所述句子级过滤器提取文本关键句的步骤具体包括:
8、通过textrank算法构建图模型;
9、所述图模型捕获文本内部的句子间相似度和文本之间的句子间相似度;
10、根据所述文本内部的句子间相似度及文本之间的句子间相似度,提取文本关键句。
11、进一步地,所述通过textrank算法构建图模型的步骤具体包括:
12、将源文本和目标文本所有句子输入,所述l1,l2分别为源文本和目标文本中句子总数,所述是源文本中每个句子,所述是目标文本中每个句子,所述ds是源文本句子集合,所述dt是目标文本句子集合;
13、组合ds以及dt,得到所有句子集合
14、以s中句子为顶点,句子间相似度作为边的权重,构建图模型。
15、进一步地,所述句子间相似度的计算方式为:计算共现词语数占句子词语总数的比例,句子si和句子sj间相似度sim(si,sj)计算公式如式(1)所示:
16、
17、所述si和sj分别为i第个句子和第j个句子,所述sim(si,sj)为si和sj间相似度,所述wk为在si和sj中同时出现的词语。
18、进一步地,在所述通过textrank算法构建图模型的步骤之后还包括步骤:
19、利用textrank算法对句子进行打分,再依据评分大小提取文本关键句,句子si的评分数值w(si)由式(2)迭代得到:
20、
21、所述w(si)为句子si的权重值,所述w(sj)为句子sj的权重值,所述d为阻尼系数,代表从图中某一节点指向其他任意节点的概率,一般设置为0.85,所述si、sj和sk均为句子集合中的句子,所述sim(si,sj)为si和sj间相似度,所述sim(sj,sk)为sj和sk间相似度。
22、进一步地,所述词语级过滤器进行词语级噪声过滤的步骤具体包括:
23、所述词语级过滤器以bert模型为基础,融合pagerank算法和attention矩阵执行词语删减策略,筛选并删除隐藏层的词语级噪声信息。
24、本发明另一目的在于提供一种面向长文本的文本匹配系统,所述系统包括:
25、句子级过滤器,用于接收待匹配的两个文本输入,并针对每个待匹配的文本分别提取对应的文本关键句;
26、词语级过滤器,用于接收文本关键句输入,并对所述文本关键句进行词语级噪声过滤和细粒度匹配操作,输出过滤匹配后文本;
27、向量获取模块,用于利用bert模型输出两个所述过滤匹配后文本各自对应的位置向量,将所述位置向量输入1维卷积神经网络进行文本语义特征提取,求得两个文本的综合上下文的特征表示向量;以及
28、相似性分析模块,用于将两文本的特征表示向量和bert模型中的cls标识符的特征表示向量进行拼接,输入全连接神经网络中预测相似性得分,所述相似性得分作为判断文本是否匹配的依据。
29、进一步地,所述句子级过滤器包括:
30、图模型构建模块,用于通过textrank算法构建图模型;
31、相似度捕获模块,用于所述图模型捕获文本内部的句子间相似度和文本之间的句子间相似度;以及
32、关键句提取模块,用于根据所述文本内部的句子间相似度及文本之间的句子间相似度,提取文本关键句。
33、进一步地,所述图模型构建模块具体包括:
34、句子输入模块,用于将源文本和目标文本所有句子输入;所述l1,l2分别为源文本和目标文本中句子总数,所述是源文本中每个句子,所述是目标文本中每个句子,所述ds是源文本句子集合,所述dt是目标文本句子集合;
35、句子组合模块,用于组合ds以及dt,得到所有句子集合以及
36、图模型生成模块,用于以s中句子为顶点,句子间相似度作为边的权重,构建图模型。
37、在本发明中,将待匹配文本对输入句子级过滤器过滤噪声句并提取关键句,然后将关键句输入词语级过滤器,利用融入了pagerank算法的bert模型挖掘文本间深度交互特征,对关键句进行词语级噪声过滤和细粒度匹配操作。最终通过拼接bert模型不同位置向量表示预测文本对关系。本发明提供的文本匹配方法通过对长文本中噪声句子和噪声词语进行删减,并利用精简后的信息进行匹配。与现有技术相比,本发明的积极效果是:(1)相比于将长文本所有内容不加删除地输入模型进行训练,对噪声句进行删减能够有效缩减文本长度,剔除无用信息;(2)在bert内部对噪声词进行删减操作,使模型更关注有益细粒度匹配信号,匹配精度更高;(3)结合bert输出中不同位置向量表示用于预测任务,充分利用两文本编码后的语义信息,匹配准确率更高。
技术特征:
1.一种面向长文本的文本匹配方法,其特征在于,所述文本匹配方法包括以下步骤:
2.根据权利要求1所述的面向长文本的文本匹配方法,其特征在于,所述句子级过滤器提取文本关键句的步骤具体包括:
3.根据权利要求2所述的面向长文本的文本匹配方法,其特征在于,所述通过textrank算法构建图模型的步骤具体包括:
4.根据权利要求2所述的面向长文本的文本匹配方法,其特征在于,
5.根据权利要求2所述的面向长文本的文本匹配方法,其特征在于,在所述通过textrank算法构建图模型的步骤之后还包括步骤:
6.根据权利要求1所述的面向长文本的文本匹配方法,其特征在于,所述词语级过滤器进行词语级噪声过滤的步骤具体包括:
7.一种面向长文本的文本匹配系统,其特征在于,所述系统包括:
8.根据权利要求7所述的面向长文本的文本匹配系统,其特征在于,所述句子级过滤器包括:
9.根据权利要求8所述的面向长文本的文本匹配系统,其特征在于,所述图模型构建模块具体包括:
技术总结
本发明公开了一种面向长文本的文本匹配方法及系统。在本发明中,将待匹配文本对输入句子级过滤器过滤噪声句并提取关键句,然后将关键句输入词语级过滤器,利用融入了PageRank算法的BERT模型挖掘文本间深度交互特征,对关键句进行词语级噪声过滤和细粒度匹配操作。最终通过拼接BERT模型不同位置向量表示预测文本对关系。本发明的积极效果是:(1)相比于将长文本所有内容不加删除地输入模型进行训练,对噪声句进行删减能够有效缩减文本长度,剔除无用信息;(2)在BERT内部对噪声词进行删减操作,使模型更关注有益细粒度匹配信号,匹配精度更高;(3)结合BERT输出中不同位置向量表示用于预测任务,充分利用两文本编码后的语义信息,匹配准确率更高。
技术研发人员:彭程,王佳睿,谢季,刘峰荣,余鸿,任思远,何智毅,陈科
受保护的技术使用者:中科院成都信息技术股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!