文本语料的生成方法、装置、存储介质及电子设备与流程
本公开涉及数据处理,具体地,涉及一种文本语料的生成方法、装置、存储介质及电子设备。
背景技术:
1、现有技术中,问答系统中基于检索的问答是最常用的问答方式,检索问答是基于用户输入的问答语句与问答对语料库进行对话,因此,问答对语料库的语料质量直接影响着问答系统的对话效果。在开始构建问答对语料库时,因缺乏基础语料需要专业的技术或者业务人员花费大量的时间向问答对语料库中书写问答对。并且为了提高检索准确率,在进行书写时还需要对同一检索问题进行相似问的扩写,但是中文的表述方式存在多样性,通过人工的方式很难概括同一问答语句的所有表述方式,导致问答对语料库的构建效率低。
技术实现思路
1、本公开的目的是提供一种文本语料的生成方法、装置、存储介质及电子设备,以解决相关技术中问答对语料库扩写效率较低的技术问题。
2、根据本公开实施例的第一方面,提供一种文本语料的生成方法,包括:
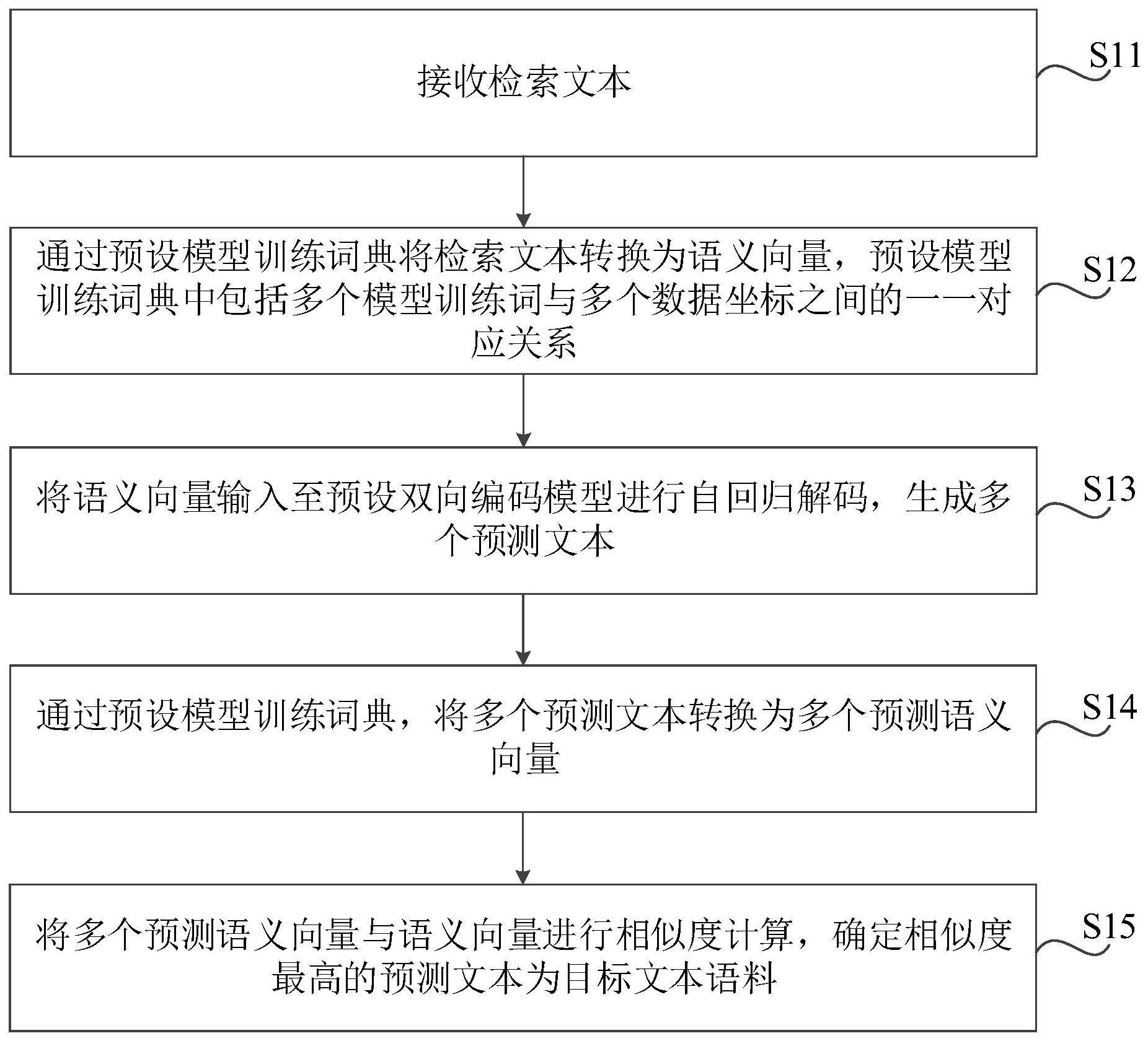
3、接收检索文本;
4、通过预设模型训练词典将所述检索文本转换为语义向量,所述预设模型训练词典中包括多个模型训练词与多个数据坐标之间的一一对应关系;
5、将所述语义向量输入至预设双向编码模型进行自回归解码,生成多个预测文本;
6、通过所述预设模型训练词典,将所述多个预测文本转换为多个预测语义向量;
7、将所述多个预测语义向量与所述语义向量进行相似度计算,确定相似度最高的预测文本为目标文本语料。
8、可选地,所述将所述多个预测语义向量与所述语义向量进行相似度计算,确定相似度最高的预测文本为目标文本语料,包括:
9、确定所述多个预测语义向量与所述语义向量之间的多个余弦相似度;
10、从所述多个余弦相似度中确定余弦相似度最大的预测语义向量为目标语义向量;
11、确定所述目标语义向量对应的预测文本为所述目标文本语料。
12、可选地,所述将所述多个预测语义向量与所述语义向量进行相似度计算,确定相似度最高的预测文本为目标文本语料,包括:
13、将所述多个预测语义向量与所述语义向量进行相似度计算,生成多个相似度;
14、根据所述多个相似度,从所述多个预测文本中获取相似度最高的预设第一数量的预测文本为所述目标文本语料。
15、可选地,所述将所述语义向量输入至预设双向编码模型进行自回归解码,生成多个预测文本,包括:
16、通过所述预设双向编码模型对所述语义向量进行解码,生成与所述检索文本中各个检索词语最相似的多个目标模型训练词;
17、获取所述检索文本的语义信息;
18、根据所述语义信息对所述多个目标模型训练词进行随机采样,生成所述多个预测文本。
19、可选地,所述通过所述预设双向编码模型对所述语义向量进行解码,生成与所述检索文本中各个检索词语最相似的多个目标模型训练词,包括:
20、通过所述预设双向编码模型从所述预设模型训练词典中选取与所述各个检索词语相似的多个初始模型训练词;
21、从所述多个初始模型训练词中选取相似度最高的预设第二数量的模型训练词为所述多个目标模型训练词。
22、可选地,所述通过预设模型训练词典将所述检索文本转换为语义向量,包括:
23、对所述检索文本进行解析,生成多个检索词语;
24、通过所述预设模型训练词典,确定所述多个检索词语一一对应的多个目标数据坐标;
25、根据所述多个检索词语在所述检索文本中的位置关系,依次连接所述多个目标数据坐标,以生成所述语义向量。
26、可选地,所述预设双向编码模型为bert模型。
27、根据本公开实施例的第二方面,提供一种文本语料的生成装置,包括:
28、接收模块,用于接收检索文本;
29、第一转换模块,用于通过预设模型训练词典将所述检索文本转换为语义向量,所述预设模型训练词典中包括多个模型训练词与多个数据坐标之间的一一对应关系;
30、生成模块,用于将所述语义向量输入至预设双向编码模型进行自回归解码,生成多个预测文本;
31、第二转换模块,用于通过所述预设模型训练词典,将所述多个预测文本转换为多个预测语义向量;
32、确定模块,用于将所述多个预测语义向量与所述语义向量进行相似度计算,确定相似度最高的预测文本为目标文本语料。
33、根据本公开实施例的第三方面,提供一种非临时性计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现本公开第一方面中任一项所述方法的步骤。
34、根据本公开实施例的第四方面,提供一种电子设备,包括:
35、存储器,其上存储有计算机程序;
36、处理器,用于执行所述存储器中的所述计算机程序,以实现本公开第一方面中任一项所述方法的步骤。
37、通过上述技术方案,接收检索文本,通过预设模型训练词典将检索文本转换为语义向量,预设模型训练词典中包括多个模型训练词与多个数据坐标之间的一一对应关系,将语义向量输入至预设双向编码模型进行自回归解码,生成多个预测文本,通过预设模型训练词典,将多个预测文本转换为多个预测语义向量,将多个预测语义向量与语义向量进行相似度计算,确定相似度最高的预测文本为目标文本语料。从而通过双向编码模型对输入的检索文本进行拓展生成多个预测文本,并根据各个预测文本与检索文本之间的相似度,确定相似度最高的预测文本为增强的目标文本语料,使生成的相似文本语料具有多样性,提高了问答对语料库的扩写效率。
38、本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
技术特征:
1.一种文本语料的生成方法,其特征在于,包括:
2.根据权利要求1所述的生成方法,其特征在于,所述将所述多个预测语义向量与所述语义向量进行相似度计算,确定相似度最高的预测文本为目标文本语料,包括:
3.根据权利要求1所述的生成方法,其特征在于,所述将所述多个预测语义向量与所述语义向量进行相似度计算,确定相似度最高的预测文本为目标文本语料,包括:
4.根据权利要求1所述的生成方法,其特征在于,所述将所述语义向量输入至预设双向编码模型进行自回归解码,生成多个预测文本,包括:
5.根据权利要求4所述的生成方法,其特征在于,所述通过所述预设双向编码模型对所述语义向量进行解码,生成与所述检索文本中各个检索词语最相似的多个目标模型训练词,包括:
6.根据权利要求1所述的生成方法,其特征在于,所述通过预设模型训练词典将所述检索文本转换为语义向量,包括:
7.根据权利要求1-6中任一项所述的生成方法,其特征在于,所述预设双向编码模型为bert模型。
8.一种文本语料的生成装置,其特征在于,包括:
9.一种非临时性计算机可读存储介质,其上存储有计算机程序,其特征在于,所述程序被处理器执行时实现权利要求1-7中任一项所述方法的步骤。
10.一种电子设备,其特征在于,包括:
技术总结
本公开涉及一种文本语料的生成方法、装置、存储介质及电子设备,该方法包括:接收检索文本,通过预设模型训练词典将检索文本转换为语义向量,预设模型训练词典中包括多个模型训练词与多个数据坐标之间的一一对应关系,将语义向量输入至预设双向编码模型进行自回归解码,生成多个预测文本,通过预设模型训练词典,将多个预测文本转换为多个预测语义向量,将多个预测语义向量与语义向量进行相似度计算,确定相似度最高的预测文本为目标文本语料。从而通过双向编码模型对输入的检索文本进行拓展生成多个预测文本,确定相似度最高的预测文本为增强的目标文本语料,使生成的相似文本语料具有多样性,通过双向编码模型提高了问答对语料库的扩写效率。
技术研发人员:陈定玮
受保护的技术使用者:飞算数智科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!