Kafka数据落盘方法、装置、设备、存储介质和程序产品与流程
本公开涉及分布式,具体涉及数据存储,更具体地涉及一种kafka数据落盘方法、装置、设备、存储介质和程序产品。
背景技术:
1、目前消息进入到kafka后,kafka会按照所指定的分区策略将消息分配到某一个分区。在kafka中,broker进程负责移动并存储数据。broker进程接收到数据时,会将数据存储在单独的本地目录中,由于是本地目录,所以如果kafka集群的topic分布不均或topic的流量差异较大,那么就会导致存储数据倾斜。
2、相关技术中,在发现数据倾斜时,无法通过紧急扩容来快速避免数据倾斜问题,必须人为介入通过调整代码的分区策略或者调整topic的分布才能解决问题。因此亟需一种能够自平衡的消息平衡落盘机制和方法。
3、需要说明的是,在上述背景技术部分公开的信息仅用于加强对本公开的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现思路
1、鉴于上述问题,本公开提供了一种实现数据自平衡落盘的kafka数据落盘方法、装置、设备、存储介质和程序产品。
2、根据本公开的第一个方面,提供了一种kafka数据落盘方法,所述方法包括:
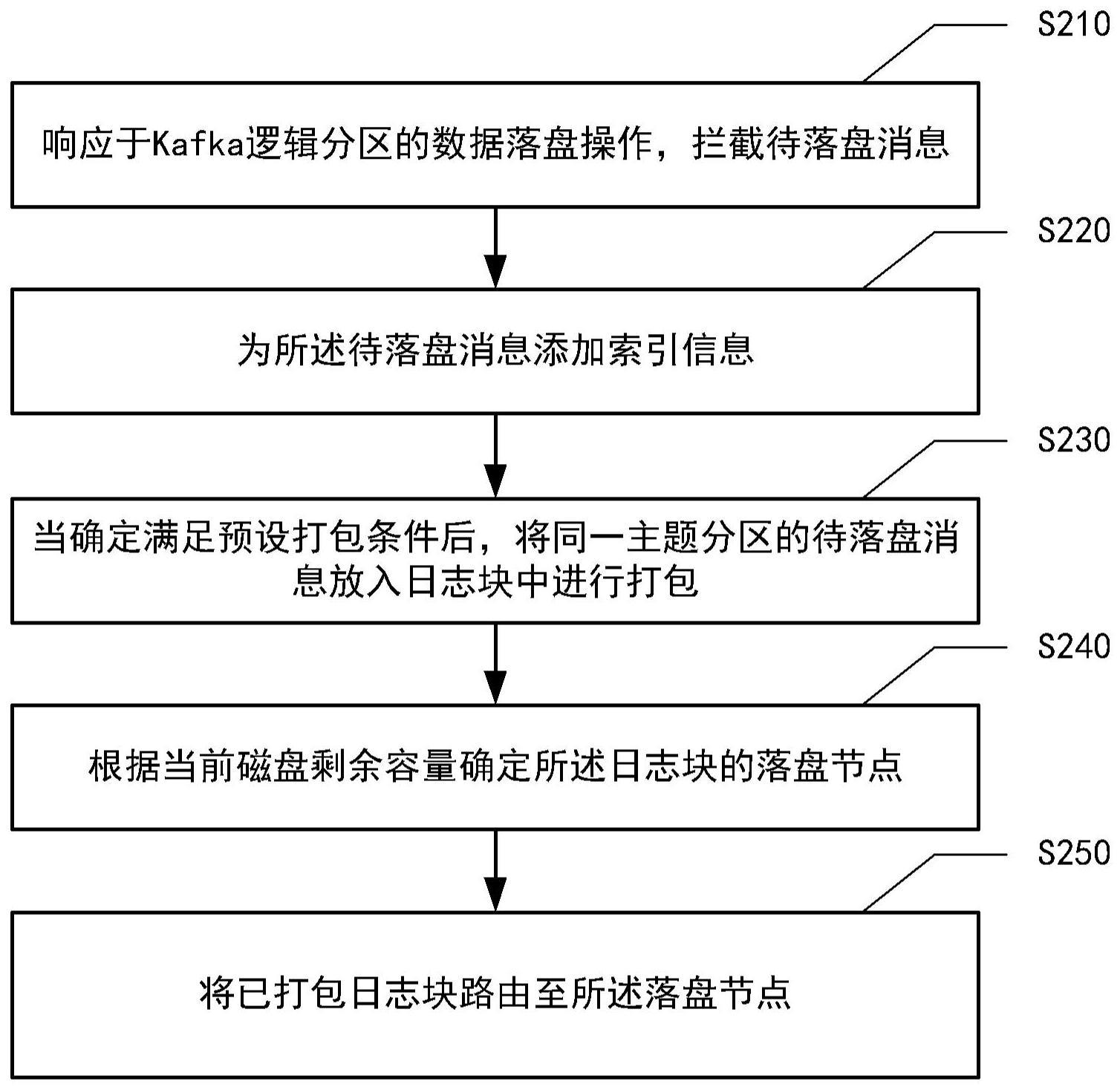
3、响应于kafka逻辑分区的数据落盘操作,拦截待落盘消息;
4、为所述待落盘消息添加索引信息,所述索引信息用于定位所述待落盘消息;
5、当确定满足预设打包条件后,将同一主题分区的待落盘消息放入日志块中进行打包;
6、根据当前磁盘剩余容量确定所述日志块的落盘节点;以及
7、将已打包日志块路由至所述落盘节点。
8、根据本公开的实施例,所述预设打包条件包括所述待落盘消息所在日志块的数据量大于第一预设阈值或所述待落盘消息等待时间大于第二预设阈值。
9、根据本公开的实施例,所述为所述待落盘消息添加索引信息包括:
10、对所述待落盘消息进行解析以获取所述待落盘消息的目标主题和目标分区;
11、根据所述目标主题和所述目标分区计算哈希值;以及
12、将所述哈希值作为索引信息插入所述待落盘消息的消息体头部。
13、根据本公开的实施例,所述根据当前磁盘剩余容量确定所述日志块的落盘节点包括:
14、获取当前节点的磁盘剩余容量;
15、根据所述当前节点的磁盘剩余容量确定副本数个第一目标节点,其中,所述副本数为kafka数据需要同步的份数;以及
16、将所述第一目标节点中磁盘剩余容量最大的节点作为所述日志块的落盘节点。
17、根据本公开的实施例,在将已打包日志块路由至所述落盘节点之前,还包括:
18、根据所述副本数个第一目标节点在所述已打包的日志块中添加推送标签。
19、根据本公开的实施例,还包括:
20、根据所述推送标签同步所述日志块。
21、本公开的第二方面提供了一种kafka数据落盘装置,所述装置包括:
22、消息拦截模块,用于响应于kafka逻辑分区的数据落盘操作,拦截待落盘消息;
23、消息处理模块,用于为所述待落盘消息添加索引信息,所述索引信息用于定位所述待落盘消息;
24、消息打包模块,用于当确定满足预设打包条件后,将同一主题分区的待落盘消息放入日志块中进行打包;
25、落盘节点确定模块,用于根据当前磁盘剩余容量确定所述日志块的落盘节点;以及
26、消息路由模块,用于将已打包日志块路由至所述落盘节点。
27、根据本公开的实施例,所述预设打包条件包括所述待落盘消息所在日志块的数据量大于第一预设阈值或所述待落盘消息等待时间大于第二预设阈值。
28、根据本公开的实施例,所述消息处理模块包括:解析子模块、计算子模块和索引插入子模块。
29、解析子模块,用于对所述待落盘消息进行解析以获取所述待落盘消息的目标主题和目标分区;
30、计算子模块,用于根据所述目标主题和所述目标分区计算哈希值;以及
31、索引插入子模块,用于将所述哈希值作为索引信息插入所述待落盘消息的消息体头部。
32、根据本公开的实施例,所述落盘节点确定模块包括:获取子模块、第一确定子模块和第二确定子模块。
33、获取子模块,用于获取当前节点的磁盘剩余容量;
34、第一确定子模块,用于根据所述当前节点的磁盘剩余容量确定副本数个第一目标节点,其中,所述副本数为kafka数据需要同步的份数;以及
35、第二确定子模块,用于将所述第一目标节点中磁盘剩余容量最大的节点作为所述日志块的落盘节点。
36、根据本公开的实施例,所述装置还包括:推送标签添加模块。
37、推送标签添加模块,用于根据所述副本数个第一目标节点在所述已打包的日志块中添加推送标签;
38、根据本公开的实施例,所述装置还包括:数据同步模块。
39、数据同步模块,用于根据所述推送标签同步所述日志块。
40、本公开的第三方面提供了一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得一个或多个处理器执行上述kafka数据落盘方法。
41、本公开的第四方面还提供了一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行上述kafka数据落盘方法。
42、本公开的第五方面还提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述kafka数据落盘方法。
43、通过本公开的实施例提供的一种kafka数据落盘方法,在数据落盘前拦截待落盘数据,根据当前磁盘剩余容量确定空闲节点作为落盘节点,在满足预设打包条件后,将同一主题分区的待落盘消息放入日志块中进行打包,并将已打包日志块路由至所述落盘节点,同时在路由前还为所述待落盘消息添加索引信息,便于消费者正常消费消息。相较于相关技术,本公开实施例提供的数据落盘方法无需人为介入即可实现kafka数据存储的自平衡,解决了因topic主题分布不均或topic消息流量不同导致的数据存储倾斜问题。
技术特征:
1.一种kafka数据落盘方法,其特征在于,所述方法包括:
2.根据权利要求1所述的kafka数据落盘方法,其特征在于,所述预设打包条件包括所述待落盘消息所在日志块的数据量大于第一预设阈值或所述待落盘消息等待时间大于第二预设阈值。
3.根据权利要求2所述的kafka数据落盘方法,其特征在于,所述为所述待落盘消息添加索引信息包括:
4.根据权利要求1所述的kafka数据落盘方法,其特征在于,所述根据当前磁盘剩余容量确定所述日志块的落盘节点包括:
5.根据权利要求4所述的kafka数据落盘方法,其特征在于,在将已打包日志块路由至所述落盘节点之前,还包括:
6.根据权利要求5所述的kafka数据落盘方法,其特征在于,还包括:
7.一种kafka数据落盘装置,其特征在于,所述装置包括:
8.一种电子设备,包括:
9.一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行根据权利要求1~6中任一项所述的kafka数据落盘方法。
10.一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现根据权利要求1~6中任一项所述的kafka数据落盘方法。
技术总结
本公开提供了一种Kafka数据落盘方法,涉及分布式技术领域,可以应用于金融技术领域。该方法包括:响应于Kafka逻辑分区的数据落盘操作,拦截待落盘消息;为所述待落盘消息添加索引信息,所述索引信息用于定位所述待落盘消息;当确定满足预设打包条件后,将同一主题分区的待落盘消息放入日志块中进行打包;根据当前磁盘剩余容量确定所述日志块的落盘节点;以及将已打包日志块路由至所述落盘节点。本公开还提供了一种Kafka数据落盘装置、设备、存储介质和程序产品。
技术研发人员:杨旭杰,冯子杰,孟江,蔡佳纯
受保护的技术使用者:中国工商银行股份有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!