一种缺陷文本分类方法、装置、电子设备及存储介质与流程
本发明实施例涉及计算机领域,尤其涉及一种缺陷文本分类方法、装置、电子设备及存储介质。
背景技术:
1、领域驱动设计(domain-drivendesign,ddd),是一个针对大型复杂业务系统的领域建模方法体系。在基于ddd完成领域建模之后,业务系统可被划分为一个或是多个领域,各个领域之间通常需要进行交互。
2、为了保障业务系统的稳定性与健壮性,测试工程师会对交互逻辑设计相应的测试用例并进行回归。针对在测试期间提出的缺陷(bug)文本(即bug单),可以对这些缺陷文本所属的领域进行分类,以便由此确定出业务系统中需进行改进的交互逻辑。目前,主要是通过人工实现缺陷文本的分类过程。
3、在实现本发明的过程中,发明人发现现有技术中存在以下技术问题:缺陷文本分类的准确度难以保证并且人工成本较高。
技术实现思路
1、本发明实施例提供一种缺陷文本分类方法、装置、电子设备及存储介质,以较低的人工成本实现缺陷文本的准确分类。
2、根据本发明的一方面,提供了一种缺陷文本分类方法,可以包括:
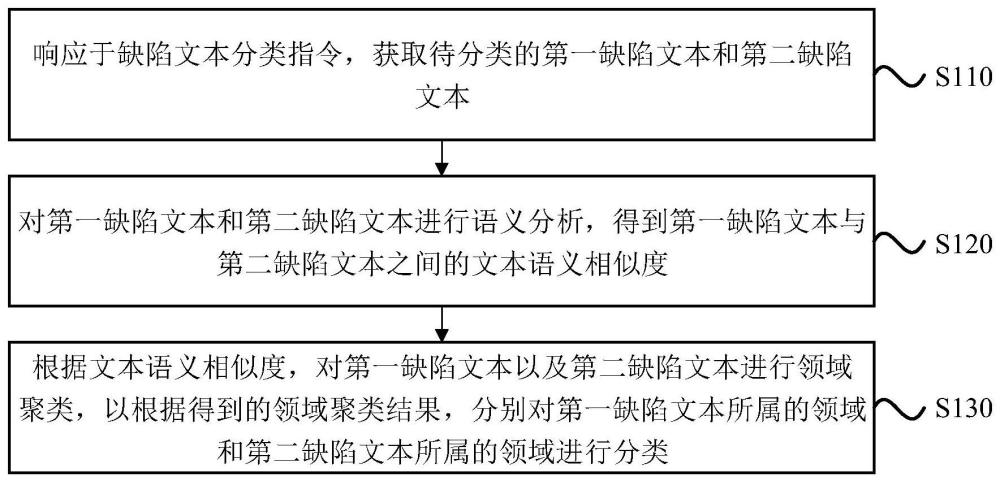
3、响应于缺陷文本分类指令,获取待分类的第一缺陷文本和第二缺陷文本;
4、对第一缺陷文本和第二缺陷文本进行语义分析,得到第一缺陷文本与第二缺陷文本之间的文本语义相似度;
5、根据文本语义相似度,对第一缺陷文本和第二缺陷文本进行领域聚类,以根据得到的领域聚类结果,分别对第一缺陷文本所属的领域和第二缺陷文本所属的领域进行分类。
6、根据本发明的另一方面,提供了一种缺陷文本分类装置,可以包括:
7、缺陷文本获取模块,用于响应于缺陷文本分类指令,获取待分类的第一缺陷文本和第二缺陷文本;
8、文本语义相似度得到模块,用于对第一缺陷文本和第二缺陷文本进行语义分析,得到第一缺陷文本与第二缺陷文本之间的文本语义相似度;
9、缺陷文本分类模块,用于根据文本语义相似度,对第一缺陷文本和第二缺陷文本进行领域聚类,以根据得到的领域聚类结果,分别对第一缺陷文本所属的领域和第二缺陷文本所属的领域进行分类。
10、根据本发明的另一方面,提供了一种电子设备,可以包括:
11、至少一个处理器;以及
12、与至少一个处理器通信连接的存储器;其中,
13、存储器存储有可被至少一个处理器执行的计算机程序,计算机程序被至少一个处理器执行,以使至少一个处理器执行时实现本发明任意实施例所提供的缺陷文本分类方法。
14、根据本发明的另一方面,提供了一种计算机可读存储介质,其上存储有计算机指令,该计算机指令用于使处理器执行时实现本发明任意实施例所提供的缺陷文本分类方法。
15、本发明实施例的技术方案,通过响应于缺陷文本分类指令,获取待分类的第一缺陷文本和第二缺陷文本;对第一缺陷文本和第二缺陷文本进行语义分析,得到第一缺陷文本与第二缺陷文本之间的文本语义相似度;进一步,根据文本语义相似度,对第一缺陷文本和第二缺陷文本进行领域聚类,以便根据得到的领域聚类结果,分别对第一缺陷文本所属的领域以及第二缺陷文本所属的领域进行分类。上述技术方案,通过自动对缺陷文本进行语义分析来将语义相似的缺陷文本聚类到同一领域,从而根据领域聚类结果进行缺陷文本所属的领域的分类,由此达到了以较低的人工成本实现缺陷文本的准确分类的效果。
16、应当理解,本部分所描述的内容并非旨在标识本发明的实施例的关键或是重要特征,也不用于限制本发明的范围。本发明的其它特征将通过以下的说明书而变得容易理解。
技术特征:
1.一种缺陷文本分类方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述对所述第一缺陷文本和所述第二缺陷文本进行语义分析,得到所述第一缺陷文本与所述第二缺陷文本之间的文本语义相似度,包括:
3.根据权利要求2所述的方法,其特征在于,所述对所述第一字词和所述第二字词进行语义分析,得到所述第一缺陷文本的第一加权语义和所述第二缺陷文本的第二加权语义,包括:
4.根据权利要求3所述的方法,其特征在于,所述对所述全部组合字词中的至少部分组合字词进行语义分析,以根据得到的语义分析结果构建出将所述至少部分组合字词作为节点的平衡树,包括:
5.根据权利要求3所述的方法,其特征在于,所述根据所述第一权重向量得到所述第一缺陷文本的第一加权语义,包括:
6.根据权利要求2所述的方法,其特征在于,所述根据所述第一加权语义以及所述第二加权语义,得到所述第一缺陷文本与所述第二缺陷文本之间的文本语义相似度,包括:
7.根据权利要求6所述的方法,其特征在于,所述第一字词的数量是至少两个,所述确定所述第一缺陷文本中的第一中心词,包括:
8.根据权利要求7所述的方法,其特征在于,所述根据所述每个第一字词对应的数量,从所述至少两个第一字词中确定所述第一缺陷文本中的第一中心词,包括:
9.根据权利要求1所述的方法,其特征在于,所述根据所述文本语义相似度,对所述第一缺陷文本和所述第二缺陷文本进行领域聚类,包括:
10.根据权利要求1所述的方法,其特征在于,还包括:
11.一种缺陷文本分类装置,其特征在于,包括:
12.一种电子设备,其特征在于,包括:
13.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机指令,所述计算机指令用于使处理器执行时实现如权利要求1-10中任一所述的缺陷文本分类方法。
技术总结
本发明实施例公开了一种缺陷文本分类方法、装置、电子设备及存储介质。该方法包括:响应于缺陷文本分类指令,获取待分类的第一缺陷文本和第二缺陷文本;对第一缺陷文本和第二缺陷文本进行语义分析,得到第一缺陷文本与第二缺陷文本之间的文本语义相似度;根据文本语义相似度,对第一缺陷文本和第二缺陷文本进行领域聚类,以根据得到的领域聚类结果,分别对第一缺陷文本所属的领域和第二缺陷文本所属的领域进行分类。本发明实施例中的技术方案,通过自动对缺陷文本进行语义分析来将语义相似的缺陷文本聚类到同一领域,从而根据领域聚类结果进行缺陷文本所属的领域的分类,由此达到了以较低的人工成本实现缺陷文本的准确分类的效果。
技术研发人员:胡珅健
受保护的技术使用者:北京沃东天骏信息技术有限公司
技术研发日:
技术公布日:2024/8/20
- 还没有人留言评论。精彩留言会获得点赞!