基于SwinTransformer的RGB-D手势识别方法及手势识别系统
本发明涉及人工智能领域,具体涉及一种基于swin transformer的rgb-d手势识别方法及手势识别系统。
背景技术:
1、随着人工智能的发展,人与机器之间的交互方式变得越来越多样性,手势作为各种交互方式中最自然的一种方式,得到了越来越广泛的应用,基于视觉的手势识别方法具有成本低、识别方便等优点,成为手势识别的热门研究方向。基于视觉的方法一般采用普通的rgb相机和深度相机。相比于rgb相机,深度相机虽然成本较高,体积较大,但是它包含的深度图像能够反映出图像中各个点离相机的位置,包含着空间信息,将这两种信息融合起来能够提高手势识别的准确率。
2、最近随着transformer越来越多的应用到计算机视觉领域,并且表现出强大的能力。然而在一些比较相似的手势上,仅从rgb图像进行分类,可能会出错,提取深度信息的特征会有效的补充特征,更准确的识别手势。
技术实现思路
1、本发明的目的在于根据在交互过程中手势识别准确性的问题,提出了一种基于swin transformer的rgb-d手势识别方法及手势识别系统。其中,使用swin transformer网络进行静态手势识别,手势信息采用深度摄像机拍摄的rgb-d图像,实际的识别手势过程中,将采用深度信息预测的结果与rgb信息预测的结果融合作为最终识别结果,提高手势识别准确率。其中,swin transformer(shifted window transformer)是一个基于transformer的深度学习模型,在视觉任务中取得了最先进的性能。
2、本发明的技术方案为:
3、本发明提供一种基于swin transformer的rgb-d手势识别方法,包括:
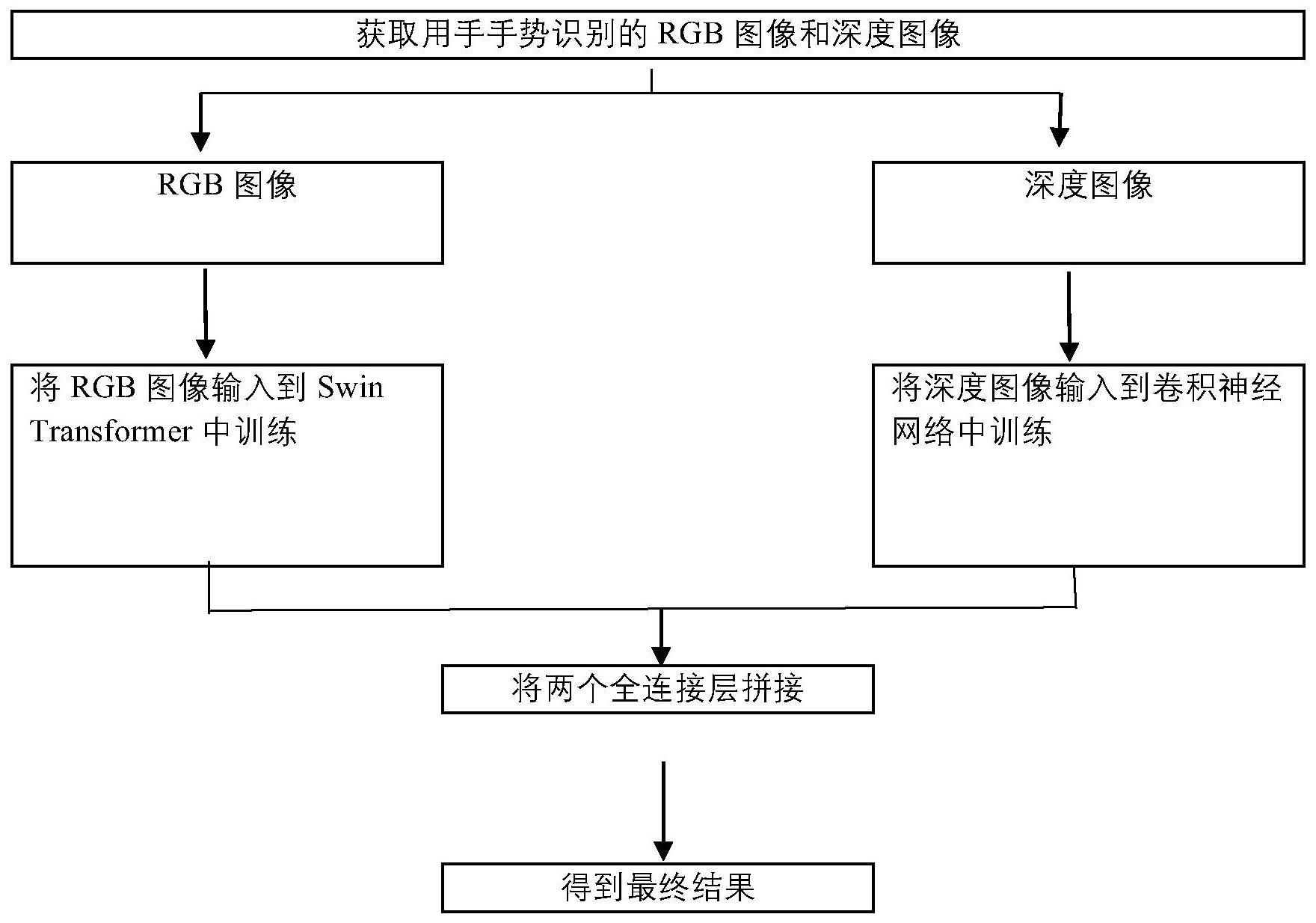
4、步骤s1,获取用于手势识别的rgb图像和深度图像;
5、步骤s2,将rgb图像送入训练好的swin transformer的网络中,将深度图像送入到一个训练好的卷积神经网络中;
6、步骤s3,将两个网络的结果进行融合,得到最终结果;
7、进一步的,步骤s2中训练好的swin transformer的网络的张量维度最终为7*7*1024;
8、进一步的,步骤s2中的卷积神经网络结构,第1、2、4、5、7、8、10、11、13、14层为3*3的卷积层加上一个relu层,第3、6、9、12层为2*2的最大池化层,经过前14层得到的张量的维度也是7*7*1024。
9、进一步的,所述步骤s3,是将经过卷积神经网络和swin transformer得到的两个张量加在一起,经过两个3*3的卷积层和一个relu层,然后经过一个全局平均池化层,最后使用softmax分类器得到手势的最终结果。
10、一种手势识别系统,用于实现上述识别方法,包括:数据获取模块、网络模块、结果输出模块;数据获取模块用来获取rgb图像和深度图像;并将图片送到网络模块;网络模块用于将上述的两种图像分别输入各自预训练好的网络中,进行识别,结果输出模块用于显示手势识别的结果。
11、本发明的基于swin transformer的rgb-d手势识别方法及手势识别系统,使用rgb-d相机收集图像,不需要使用者佩戴额外的设备,使用起来很方便,把深度图像的信息送到网络中训练,可以在手势很相似的时候,仅通过rgb图像很难分辨出正确的手势,通过把深度信息的结果与rgb的结果融合,来提高手势识别的准确率。。本方案在训练过程中使用深度信息,并将输出的结果与经过swin transformer的rgb的结果融合,来解决一些相似手势识别不准确的问题。
技术特征:
1.一种基于swin transformer的rgb-d手势识别方法,其特征在于:该方法包括:
2.根据权利要求1所述的手势识别方法,其特征在于:步骤s2中训练好的swintransformer的网络的张量维度最终为7*7*1024。
3.根据权利要求1所述的手势识别方法,其特征在于:步骤s2中的卷积神经网络结构,第1、2、4、5、7、8、10、11、13、14层为3*3的卷积层加上一个relu层,第3、6、9、12层为2*2的最大池化层,经过前14层得到的张量的维度也是7*7*1024。
4.根据权利要求1所述的手势识别方法,其特征在于:在训练所述的的swintransformer的网络过程中,通过modelcheckpoint函数保存最优化的网络。
5.一种用于识别上述方法的手势识别系统,其特征在于:包括:数据获取模块、网络模块、结果输出模块;数据获取模块用来获取rgb图像和深度图像;并将图片送到网络模块;网络模块用于将上述的两种图像分别输入各自预训练好的网络中,进行识别,结果输出模块用于显示手势识别的结果。
技术总结
本发明公开一种基于Swin Transformer的RGB‑D手势识别方法及手势识别系统,该方法包括:S1、获取用于手势识别的RGB图像和深度图像;S2、将RGB图像送入训练好的Swin Transformer网络,深度图像送入训练好的卷积神经网络;S3、将两个网络的结果融合得到最终结果。本发明使用Swin Transformer网络进行静态手势识别,手势信息采用深度摄像机拍摄的RGB‑D图像,包含了空间内各个点相对于摄像头的距离,该深度信息方便计算各点之间的相互距离。实际的识别手势过程中,将采用深度信息预测的结果与RGB信息预测的结果融合作为最终识别结果,提高手势识别准确率。
技术研发人员:韩磊,计鑫鹏,方维,高腾,冉东升,周奥
受保护的技术使用者:北京邮电大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!