基于LDA主题建模的居民代表性活动模式识别方法及系统
本发明属于出行行为建模,具体涉及基于lda主题建模的居民代表性活动模式识别方法及系统。
背景技术:
1、在多模式出行环境下,人们的出行行为呈现场景化、规律化的特点,城市交通规划与管理逐渐向精细化转变。在多元信息化时代,精准定位并掌握居民的出行特征对于城市交通管控和相关设施运营商都至关重要。一方面,传统的四阶段交通分配模型以小区为研究单元、假设个体出行方式是单一的、认为交通状态是保持静态且平均的,上述不合理假设已不满足现阶段交通规划的精度及要求。另一方面,出行实际上是源于日常活动的,基于活动的预测模型(abm,activity based model)已逐渐替代传统的集计模型。开发基于活动的模型的主要难点是试图捕捉个体的复杂行为并将其视为分析单元。一种常见的方法是定义一种称为“活动模式”的基本分析单元:“在特定时间段内由出行和活动所代表的行为模式”。在活动-出行行为分析中,个体活动与社会关系及空间背景密切相关,因此识别到的活动模式的相似性可以用于个体分类及群体活动特性的刻画。其次,城市的代表性活动模式与土地利用、社会环境有关,并且在城市的正常规划期(10年)内是稳定的。挖掘个体活动规律可以基于城市建设有效指导交通规划。
2、活动模式涵盖活动类型、活动开始时间与结束时间以及各项活动的序列安排等信息。目前的研究中,大多数学者采用直接聚类的方法,如k-means聚类、k-medoids等方法简单地对活动模式进行分类。但活动属性包含的大多是名义变量,如活动类型。直接聚类的方法通常是基于欧氏距离,无法衡量名义序列之间的差异,难以捕捉活动序列之间的相似性。此外,一些学者使用主成分分析(pca)来获得低维数值特征,然后使用聚类方法获得代表性活动模式。但是通过pca获得的每个维度通常不具有实际意义,特征只能用作聚类的输入,无法获得代表性活动模式。
技术实现思路
1、本发明所解决的技术问题是:目前的代表性活动模式研究中,大多数学者采用直接聚类的方法简单地对活动模式进行分类。但活动属性包含的大多是名义变量,如活动类型。直接聚类无法衡量名义序列之间的差异,难以捕捉活动序列之间的相似性。
2、为解决上述技术问题,本发明采用以下技术方案:
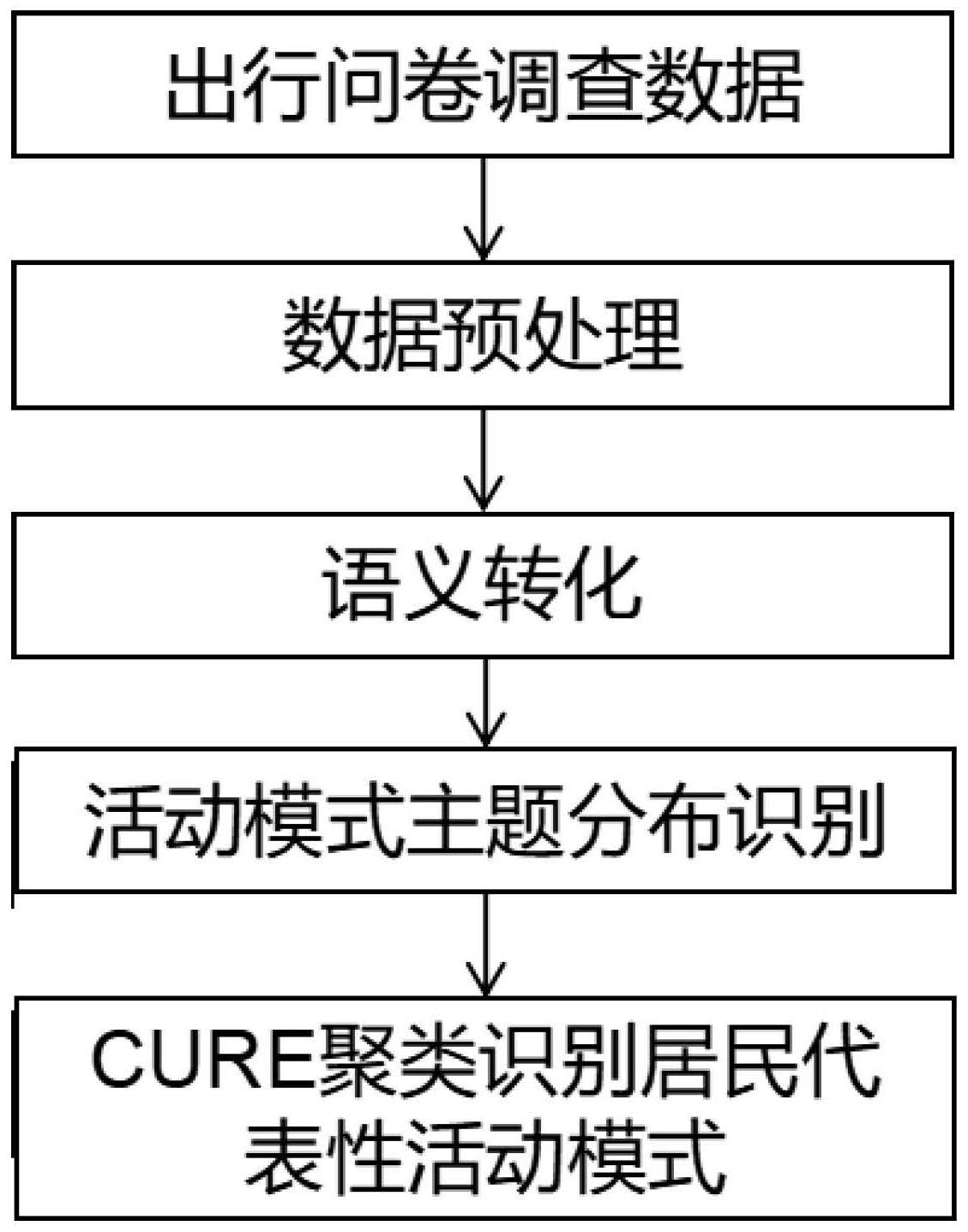
3、一种基于lda主题建模的居民代表性活动模式识别方法,基于目标人群在目标时间段内的活动数据,执行以下步骤,对目标人群活动模式的主题分布进行识别,并获得目标人群在目标时间段内的代表性活动模式表征:
4、步骤a:针对目标人群在目标时间段内的活动数据,基于目标时间段划分的预设个数时间间隔,将活动数据包含的各活动类型与各时间间隔匹配,获得目标人群中每人在目标时间段内各时间间隔分别对应的活动类型;
5、步骤b:针对目标人群中每人在目标时间段内各时间间隔分别对应的活动类型进行语义转化,获得目标人群中每人在目标时间段内对应的语义文档;语义文档为目标人群中每人在目标时间段内的活动序列,一个活动序列包含各时间间隔及其对应的活动类型;语义文档中的各词语表现形式为“活动类型-时间间隔”;
6、步骤c:针对目标人群中每人在目标时间段内对应的语义文档,结合预设主题数,获得各语义文档分别对应的主题分布;各语义文档的主题分布即为目标人群的活动模式主题分布;
7、步骤d:基于目标人群的活动模式主题分布,采用聚类算法,获得目标人群在目标时间段内的代表性活动模式表征。
8、作为本发明的一种优选技术方案,所述步骤c中,针对语义文档,结合预设主题数,进行lda模型的文本建模,并采用gibbs进行lda模型求解,获得各语义文档分别对应的主题分布。
9、作为本发明的一种优选技术方案,所述采用gibbs进行lda模型求解,具体执行以下步骤,获得各语义文档分别对应的主题分布:
10、步骤c1:基于预设主题数k,选择预设超参数向量为k维的超参数向量,为v维的超参数向量,v为所有语义文档的不重复词语的总数;
11、步骤c2:基于预设主题数k,基于狄利克雷分布为各语义文档中的每个词语分配一个主题;
12、步骤c3:针对各语义文档中的每个词语当前对应的主题,利用基于预设超参数向量获得的gibbs采样公式更新每个词语分别对应的主题;
13、步骤c4:判断gibbs采样是否收敛,若gibbs采样收敛,则执行步骤c5;若gibbs采样不收敛,返回步骤c3;
14、步骤c5:基于各个语义文档中每个词语分别对应的主题,获得各语义文档分别对应的主题分布。
15、作为本发明的一种优选技术方案,所述步骤c3中,具体执行以下步骤,更新每个词语分别对应的主题:
16、步骤c3.1:基于预设超参数向量获得所有语义文档中主题和词语的联合分布
17、其中,是所有语义文档中所有词语形成的词语向量,是所有语义文档中的主题分布形成的主题向量;
18、步骤c3.2:基于所有语义文档中主题和词语的联合分布获得每个词语对应各主题的gibbs采样的条件概率公式;
19、步骤c3.3:基于每个词语对应各主题的gibbs采样的条件概率公式,更新每个词语分别对应的主题。
20、作为本发明的一种优选技术方案,所述预设主题数,通过迭代执行以下步骤,基于预设最大主题数,在不发生过拟合的前提下,将困惑度最小对应的主题数作为预设主题数:
21、步骤1:针对所有语义文档,结合当前主题数,初始主题数为1,进行lda模型的文本建模,采用gibbs进行lda模型求解,获得各语义文档分别对应的主题分布,以及各主题分别对应的词语分布;
22、步骤2:基于各语义文档分别对应的主题分布、以及各主题分别对应的词语分布,获得当前lda主题模型的困惑度perplexity(d);
23、步骤3:主题数一,判断主题数是否大于预设最大主题数,若主题数大于预设最大主题数,则迭代结束;若主题数不大于预设最大主题数,返回步骤1。
24、作为本发明的一种优选技术方案,所述步骤d中,采用的聚类算法为cure聚类算法。
25、作为本发明的一种优选技术方案,所述步骤d中,基于目标人群的活动模式主题分布,采用聚类算法,具体执行以下步骤,获得目标人群在目标时间段内的代表性活动模式表征:
26、步骤d1:针对所有目标人群的活动模式主题分布,随机抽取s个主题分布样本;
27、步骤d2:将s个主题分布样本按数量均匀原则分割为预设数量分区,分别针对每个分区进行聚类获得每个分区分别对应的各数据簇,并基于数据簇增长速度筛除离群点;
28、步骤d3:针对所有分区数据簇,选择预设个数簇的代表点,按照预设收缩因子向簇中心收缩,根据数据簇之间的距离进行合并,并基于数据簇的规模筛除离群点,直至达到预设簇数,完成聚类;
29、步骤d4:基于聚类结果,分别统计各类活动模式在时间间隔及活动类型的分布情况,获得目标人群的代表性活动模式表征。
30、一种基于lda主题建模的居民代表性活动模式识别方法的系统,包括数据匹配模块、语义转化模块、主题模块、分类模块,
31、针对目标人群在目标时间段内的活动数据,基于目标时间段划分的预设个数时间间隔,数据匹配模块用于将活动数据包含的各活动类型与各时间间隔匹配,获得目标人群中每人在目标时间段内各时间间隔分别对应的活动类型;
32、语义转化模块用于针对目标人群中每人在目标时间段内各时间间隔分别对应的活动类型进行语义转化,获得目标人群中每人在目标时间段内对应的语义文档;
33、主题模块用于针对目标人群中每人在目标时间段内对应的语义文档,结合预设主题数,获得各语义文档分别对应的主题分布;
34、分类模块基于各语义文档分别对应的主题分布,采用聚类算法,对目标人群活动模式的主题分布进行聚类,获得目标人群在目标时间段内的代表性活动模式表征。
35、一种基于lda主题建模的居民代表性活动模式识别方法的终端,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现所述一种基于lda主题建模的居民代表性活动模式识别方法。
36、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现所述一种基于lda主题建模的居民代表性活动模式识别方法。
37、本发明的有益效果是:本发明提出了基于lda主题建模的居民代表性活动模式识别方法及系统,是一种新的活动模式识别模型,为abm提供了重要支撑。运用lda主题模型将活动模式识别问题转化为文档分类问题,通过活动主题的分布来描述活动模式。使用cure聚类,基于不同主题分布之间的欧氏距离来衡量活动模式的相似性,识别居民代表性活动模式。本发明的有益效果为:①提出了一种新的活动模式识别方法,解决了名义变量无法直接聚类的问题;②将上述居民活动模式的识别结果用于个体分类,针对不同类型的个体建立具有异质性的abm模型,实现精细化建模。
- 还没有人留言评论。精彩留言会获得点赞!