视频识别模型训练方法、视频识别方法、设备和存储介质与流程
本发明涉及计算机视觉,尤其涉及一种视频识别模型训练方法、视频识别方法、设备和存储介质。
背景技术:
1、随着计算机视觉技术的快速发展,计算机视觉技术的应用范围越来越广泛。对于视频识别任务而言,需要对待识别视频进行视频识别,以得到视频识别结果。
2、例如,重复动作计数是计算机视觉中一个传统领域,重复动作计数有较广泛的运用场景,如对运动视频的分析,对健身动作的计数,是视频理解领域的重要分支。传统技术中有使用傅立叶分析、小波变换、卷积神经网络等方法进行重复动作的计数,但是最终的视频计数识别结果总是存在准确率不高的技术问题。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种视频识别模型训练方法,将第一声音特征与第一视频特征进行特征匹配,进而基于特征匹配后的特征进行模型训练,进而提高模型训练效果,提高视频识别模型的鲁棒性,最终提高视频识别的准确性。
2、本发明还提供一种视频识别装置、视频识别方法、电子设备和存储介质。
3、根据本发明第一方面实施例的视频识别模型训练方法,包括:
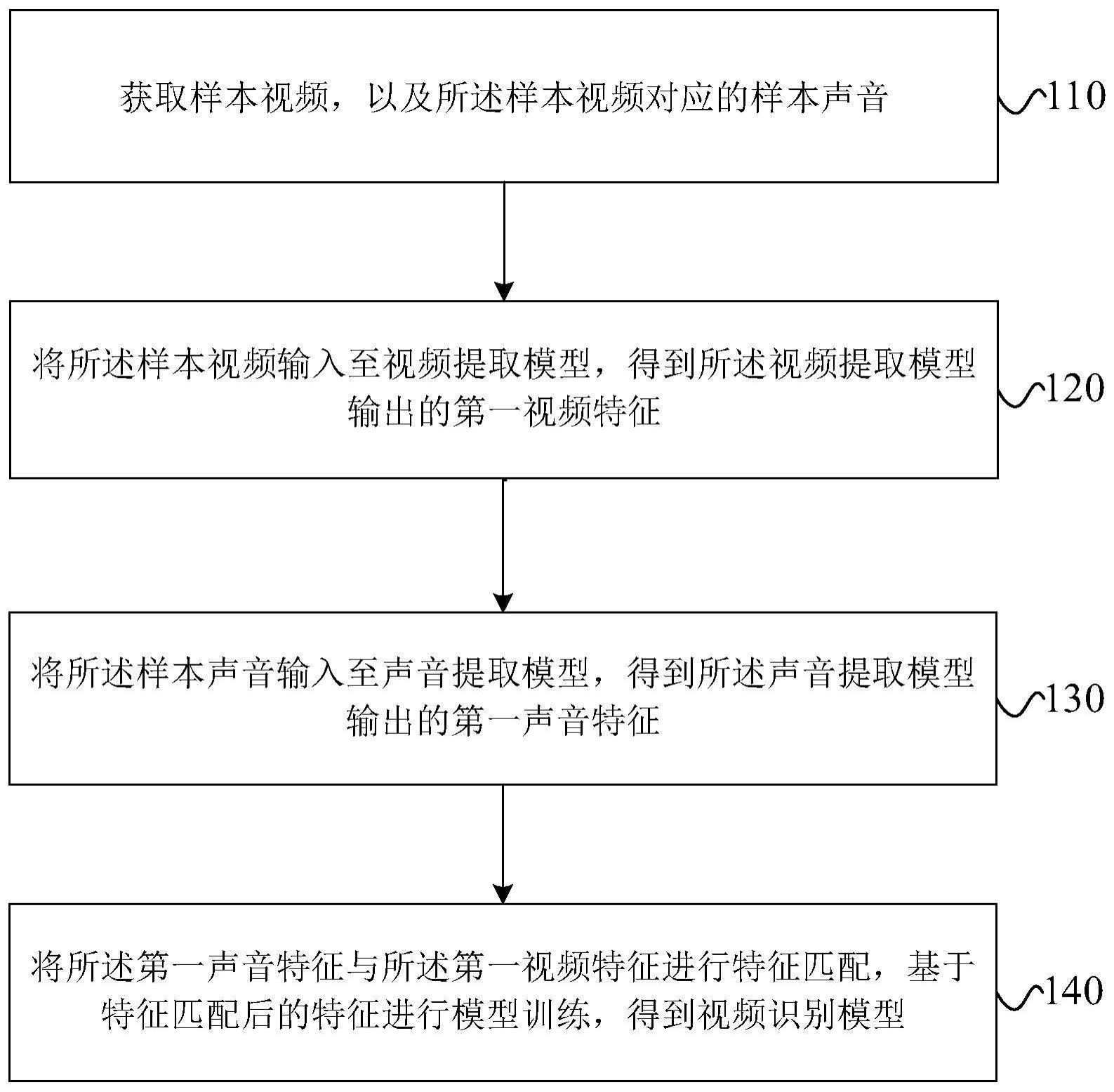
4、获取样本视频,以及所述样本视频对应的样本声音;
5、将所述样本视频输入至视频提取模型,得到所述视频提取模型输出的第一视频特征;
6、将所述样本声音输入至声音提取模型,得到所述声音提取模型输出的第一声音特征;
7、将所述第一声音特征与所述第一视频特征进行特征匹配,基于特征匹配后的特征进行模型训练,得到视频识别模型。
8、根据本发明实施例的视频识别模型训练方法,将样本视频输入至视频提取模型,得到视频提取模型输出的第一视频特征,并将样本声音输入至声音提取模型,得到声音提取模型输出的第一声音特征,从而将第一声音特征与第一视频特征进行特征匹配,进而基于特征匹配后的特征进行模型训练,进而提高模型训练效果,提高视频识别模型的鲁棒性,最终提高视频识别的准确性。
9、根据本发明的一个实施例,所述将所述第一声音特征与所述第一视频特征进行特征匹配,包括:
10、基于全局平均池化方式,将所述第一声音特征与所述第一视频特征进行维度对齐,得到第二声音特征及第二视频特征。
11、根据本发明的一个实施例,所述基于全局平均池化方式,将所述第一声音特征与所述第一视频特征进行维度对齐,得到第二声音特征及第二视频特征,之后还包括:
12、对所述第二声音特征进行频谱变换分析,得到声音信号通道;
13、对所述第二视频特征进行频谱变换分析,得到视频信号通道;
14、基于知识蒸馏方式,将时间维度上的所述声音信号通道与所述视频信号通道进行对齐,以使得将所述第二声音特征增强至所述第二视频特征。
15、根据本发明的一个实施例,所述声音信号通道包括高频信号通道及低频信号通道,所述视频信号通道包括高频信号通道及低频信号通道;
16、所述基于知识蒸馏方式,将时间维度上的所述声音信号通道与所述视频信号通道进行对齐,包括:
17、基于知识蒸馏方式,将所述声音信号通道的高频信号及低频信号分别与所述视频信号通道的高频信号及低频信号进行对齐。
18、根据本发明的一个实施例,所述知识蒸馏方式是基于平均绝对值误差损失函数进行知识蒸馏优化的方式。
19、根据本发明的一个实施例,所述视频识别模型用于对待识别视频进行视频识别得到视频识别结果,所述视频识别结果是基于所述视频识别模型的分类层进行视频识别得到的,或所述视频识别结果是基于所述视频识别模型的回归层进行视频识别得到的。
20、根据本发明的一个实施例,所述视频识别模型用于重复动作计数识别、动作识别、视频分割中的至少一种。
21、根据本发明第二方面实施例的视频识别方法,包括:
22、获取待识别视频;
23、将所述待识别视频输入至视频识别模型,得到所述视频识别模型输出的视频识别结果;
24、其中,所述视频识别模型是由如上任一种所述的视频识别模型训练方法训练得到的。
25、根据本发明实施例的视频识别方法,在推理过程中,仅需要将待识别视频输入至视频识别模型,即可进行视频识别,从而仅在训练过程中引入声音数据,以在推理过程中,只需将待识别视频输入至视频识别模型,即可准确得到视频识别结果,从而确保视频识别准确性的同时,提高视频识别的效率,并提高视频识别的适用性。
26、根据本发明第三方面实施例的电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述视频识别模型训练方法,或实现如上述任一种所述视频识别方法。
27、根据本发明第四方面实施例的非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述视频识别模型训练方法,或实现如上述任一种所述视频识别方法。
28、本发明实施例中的上述一个或多个技术方案,至少具有如下技术效果之一:
29、在训练过程中,将样本视频输入至视频提取模型,得到视频提取模型输出的第一视频特征,并将样本声音输入至声音提取模型,得到声音提取模型输出的第一声音特征,从而将第一声音特征与第一视频特征进行特征匹配,进而基于特征匹配后的特征进行模型训练,进而提高模型训练效果,提高视频识别模型的鲁棒性,最终提高视频识别的准确性。
30、在推理过程中,仅需要将待识别视频输入至视频识别模型,即可进行视频识别,从而仅在训练过程中引入声音数据,以在推理过程中,只需将待识别视频输入至视频识别模型,即可准确得到视频识别结果,从而确保视频识别准确性的同时,提高视频识别的效率,并提高视频识别的适用性。
31、本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:
1.一种视频识别模型训练方法,其特征在于,包括:
2.根据权利要求1所述的视频识别模型训练方法,其特征在于,所述将所述第一声音特征与所述第一视频特征进行特征匹配,包括:
3.根据权利要求2所述的视频识别模型训练方法,其特征在于,所述基于全局平均池化方式,将所述第一声音特征与所述第一视频特征进行维度对齐,得到第二声音特征及第二视频特征,之后还包括:
4.根据权利要求3所述的视频识别模型训练方法,其特征在于,所述声音信号通道包括高频信号通道及低频信号通道,所述视频信号通道包括高频信号通道及低频信号通道;
5.根据权利要求3所述的视频识别模型训练方法,其特征在于,所述知识蒸馏方式是基于平均绝对值误差损失函数进行知识蒸馏优化的方式。
6.根据权利要求1所述的视频识别模型训练方法,其特征在于,所述视频识别模型用于对待识别视频进行视频识别得到视频识别结果,所述视频识别结果是基于所述视频识别模型的分类层进行视频识别得到的,或所述视频识别结果是基于所述视频识别模型的回归层进行视频识别得到的。
7.根据权利要求1至6中任意一项所述的视频识别模型训练方法,其特征在于,所述视频识别模型用于重复动作计数识别、动作识别、视频分割中的至少一种。
8.一种视频识别方法,其特征在于,包括:
9.一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至7任一项所述的视频识别模型训练方法或者实现如权利要求8中所述的视频识别方法。
10.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述的视频识别模型训练方法或者实现如权利要求8中所述的视频识别方法。
技术总结
本发明涉及计算机视觉技术领域,提供一种视频识别模型训练方法、视频识别方法、设备和存储介质,视频识别模型训练方法包括:获取样本视频,以及所述样本视频对应的样本声音;将所述样本视频输入至视频提取模型,得到所述视频提取模型输出的第一视频特征;将所述样本声音输入至声音提取模型,得到所述声音提取模型输出的第一声音特征;将所述第一声音特征与所述第一视频特征进行特征匹配,基于特征匹配后的特征进行模型训练,得到视频识别模型。本发明将第一声音特征与第一视频特征进行特征匹配,进而基于特征匹配后的特征进行模型训练,进而提高模型训练效果,提高视频识别模型的鲁棒性,最终提高视频识别的准确性。
技术研发人员:祝毅晨
受保护的技术使用者:美的集团(上海)有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!