本发明涉及标签识别,特别涉及一种文本分类打标框架。
背景技术:
1、文本,是指书面语言的表现形式,从文学角度说,通常是具有完整、系统含义的一个句子或多个句子的组合。一个文本可以是一个句子、一个段落或者一个篇章广义“文本”:任何由书写所固定下来的任何话语。(利科尔)狭义“文本”:由语言文字组成的文学实体,代指“作品”,相对于作者、世界构成一个独立、自足的系统。
2、传统的文本在进行分类时需要进行打标框架,并且现有的打标框架并没有将多分类、多标签分类、层级标签分类这三个细分问题统一到一个模型框架内,而且没有将层级标签信息建模与预训练技术有机结合起来。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了一种文本分类打标框架,解决了传统的文本在进行分类时需要进行打标框架,并且现有的打标框架并没有将多分类、多标签分类、层级标签分类这三个细分问题统一到一个模型框架内,而且没有将层级标签信息建模与预训练技术有机结合起来的问题。
3、(二)技术方案
4、为实现以上目的,本发明通过以下技术方案予以实现:一种文本分类打标框架,包括采用多标签的方式引入语义和标签差异进行建模,该方法包括以下步骤:
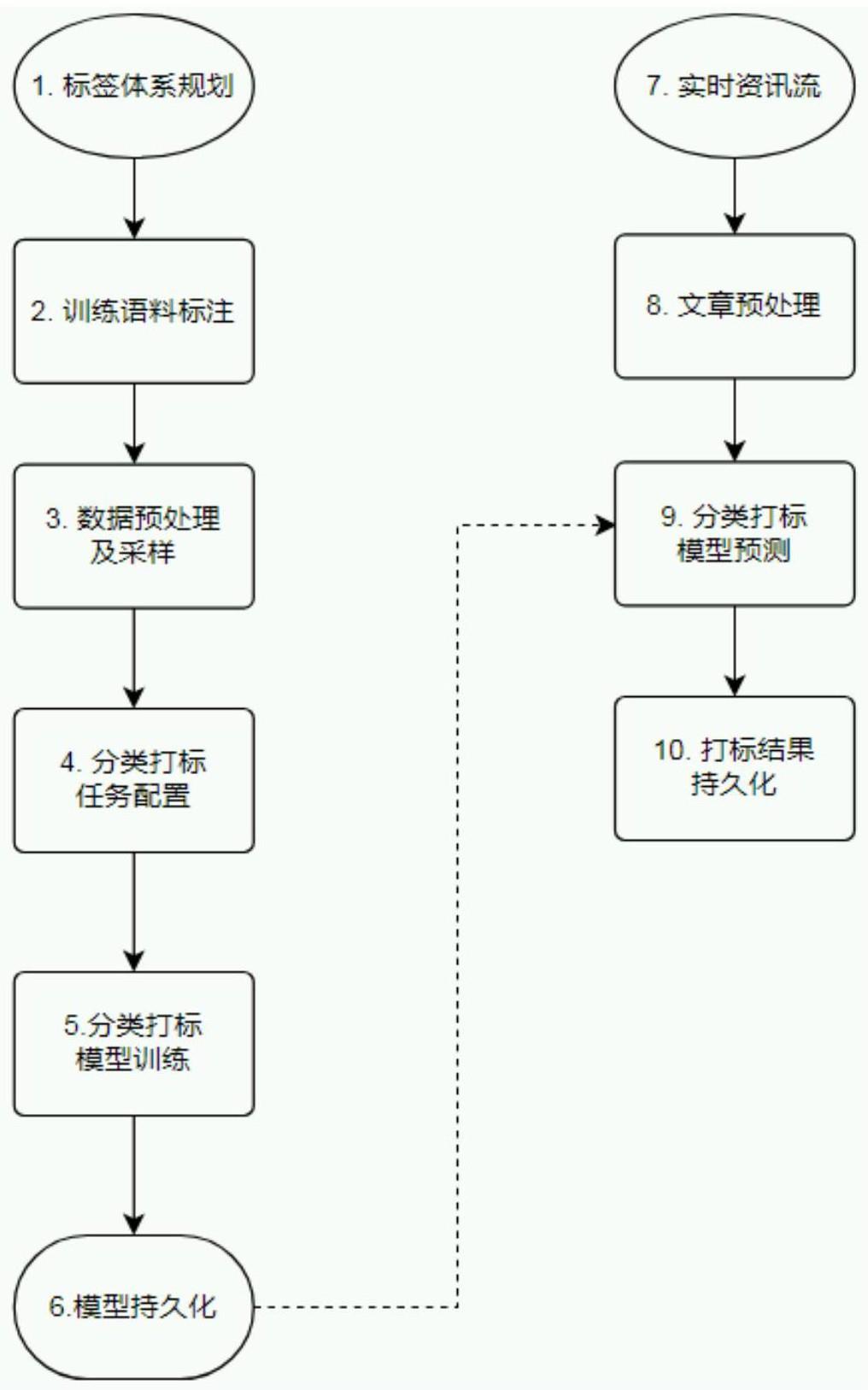
5、s1、标签体系规划。由运营专家根据业务需求规划标签体系,以树型结构呈现。
6、s2、训练语料标注。根据标签体系制定相应的标注规范,参考该规范由人工对一批资讯数据进行打标,生产训练数据。
7、s3、数据预处理及采样。对训练数据中的标题、正文等字段进行预处理,如去除空白字符、字段拼接等;针对训练数据中标签分布不平衡问题,进行欠采样、过采样等操作。
8、s4、分类打标任务配置。根据标签体系进行任务配置,包括任务类型、标签树定义等。
9、s5、分类打标模型训练。加载模型配置,将训练数据输入模型进行训练。
10、s6、模型持久化。训练完成后将模型存储到本地,用于在线预测。
11、s7、实时资讯流。对资讯队列中的实时数据依次处理。
12、s8、文章预处理。预处理方式与s3中保持一致。
13、s9、分类打标模型预测。加载持久化后的模型,进行打标推理。
14、s10、打标结果持久化。将文章及相应模型打标结果入库存储。
15、优选的,所述训练数据转tfrecord格式,用助于加速模型训练。
16、进一步,所述分类打标模型使用基于electra预训练模型的技术,以f i netun ing的方式完成训练。
17、更进一步,所述一级标签输出层根据一级标签个数使用全连接网络实现。
18、更加进一步,所述根据一级标签与二级标签的父子映射关系,结合一级标签输出层,生成由0/1组成的mask i ng向量。
19、更加进一步,所述根据标签体系的不同,将任务分为“多分类”和“多标签分类”两种类型,前者适用softmax交叉熵损失,后者使用s igmo i d交叉熵损失。
20、(三)有益效果
21、本发明提供了一种文本分类打标框架。具备以下有益效果:解决了多分类问题,一篇文章只会打上一个标签,多标签分类问题,一篇文章会打上一个或多个标签和层级标签分类问题,标签值之间存在层级关系,对某一层来说有可能是多分类问题,也有可能是多标签问题,并且基于自适应mask i ng的层级多标签分类建模方法和基于l2正则的标签层级先验知识学习方法。
技术特征:1.一种文本分类打标框架,其特征在于:包括采用多标签的方式引入语义和标签差异进行建模,该方法包括以下步骤:
2.根据权利要求1所述的一种文本分类打标框架,其特征在于:所述训练数据转tfrecord格式,用助于加速模型训练。
3.根据权利要求1所述的一种文本分类打标框架,其特征在于:所述分类打标模型使用基于electra预训练模型的技术,以finetuning的方式完成训练。
4.根据权利要求1所述的一种文本分类打标框架,其特征在于:所述一级标签输出层根据一级标签个数使用全连接网络实现。
5.根据权利要求1所述的一种文本分类打标框架,其特征在于:所述根据一级标签与二级标签的父子映射关系,结合一级标签输出层,生成由0/1组成的masking向量。
6.根据权利要求1所述的一种文本分类打标框架,其特征在于:所述根据标签体系的不同,将任务分为“多分类”和“多标签分类”两种类型,前者适用softmax交叉熵损失,后者使用sigmoid交叉熵损失。
技术总结本发明提供一种文本分类打标框架,涉及文本分类技术领域。包括采用多标签的方式引入语义和标签差异进行建模,该方法包括以下步骤:S1、标签体系规划。由运营专家根据业务需求规划标签体系,以树型结构呈现。S2、训练语料标注。根据标签体系制定相应的标注规范,参考该规范由人工对一批资讯数据进行打标,生产训练数据。S3、数据预处理及采样。对训练数据中的标题、正文等字段进行预处理,如去除空白字符、字段拼接等;针对训练数据中标签分布不平衡问题,进行欠采样、过采样等操作。S4、分类打标任务配置。根据标签体系进行任务配置,包括任务类型、标签树定义等。
技术研发人员:蔡奇
受保护的技术使用者:杭州贝赛迪科技有限公司
技术研发日:技术公布日:2024/1/13