基于图像的文本识别方法及装置与流程
本申请涉及计算机,特别涉及基于图像的文本识别方法。本申请同时涉及基于图像的文本识别装置,一种计算设备,以及一种计算机可读存储介质。
背景技术:
1、随着场景文本图像越来越丰富,可能会包含多个语种的文本内容;为了能够准确地识别不同语种的文本内容,目前可利用卷积神经网络来解决语种分类的问题。但在多语言场景下,模型的算法会较为复杂,则会出现对场景文本图像中的各个语种的文本内容识别不准确的问题,导致图像中文本内容识别精准度不高,且效率较低。
技术实现思路
1、有鉴于此,本申请实施例提供了基于图像的文本识别方法。本申请同时涉及基于图像的文本识别装置,一种计算设备,以及一种计算机可读存储介质,以解决现有技术中存在的对图像中的文本识别精准度不高的问题。
2、根据本申请实施例的第一方面,提供了一种基于图像的文本识别方法,包括:
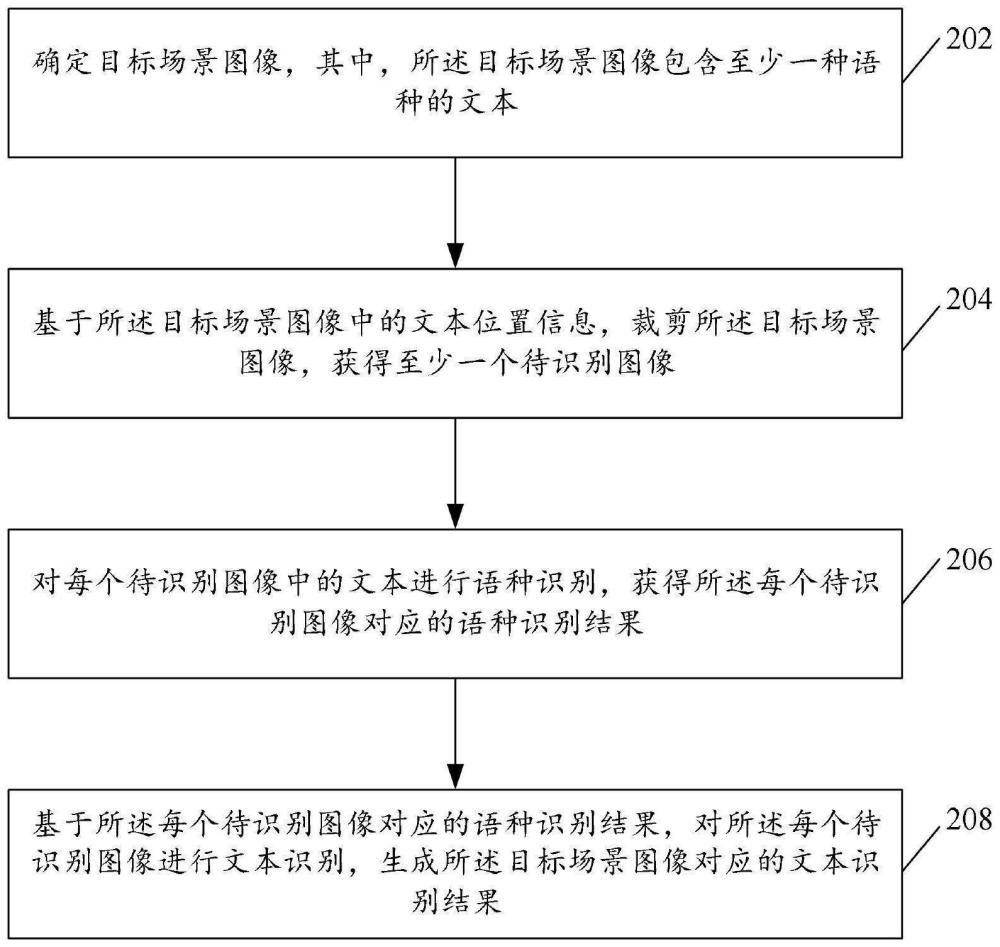
3、确定目标场景图像,其中,所述目标场景图像包含至少一种语种的文本;
4、基于所述目标场景图像中的文本位置信息,裁剪所述目标场景图像,获得至少一个待识别图像;
5、对每个待识别图像中的文本进行语种识别,获得所述每个待识别图像对应的语种识别结果;
6、基于所述每个待识别图像对应的语种识别结果,对所述每个待识别图像进行文本识别,生成所述目标场景图像对应的文本识别结果。
7、根据本申请实施例的第二方面,提供了一种基于图像的文本识别装置,包括:
8、图像确定模块,被配置为确定目标场景图像,其中,所述目标场景图像包含至少一种语种的文本;
9、图像裁剪模块,被配置为基于所述目标场景图像中的文本位置信息,裁剪所述目标场景图像,获得至少一个待识别图像;
10、语种识别模块,被配置为对每个待识别图像中的文本进行语种识别,获得所述每个待识别图像对应的语种识别结果;
11、文本识别模块,被配置为基于所述每个待识别图像对应的语种识别结果,对所述每个待识别图像进行文本识别,生成所述目标场景图像对应的文本识别结果。
12、根据本申请实施例的第三方面,提供了一种计算设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机指令,所述处理器执行所述计算机指令时实现所述基于图像的文本识别方法的步骤。
13、根据本申请实施例的第四方面,提供了一种计算机可读存储介质,其存储有计算机指令,该计算机指令被处理器执行时实现所述基于图像的文本识别方法的步骤。
14、本申请提供的基于图像的文本识别方法,确定目标场景图像,其中,所述目标场景图像包含至少一种语种的文本;基于所述目标场景图像中的文本位置信息,裁剪所述目标场景图像,获得至少一个待识别图像;对每个待识别图像中的文本进行语种识别,获得所述每个待识别图像对应的语种识别结果;基于所述每个待识别图像对应的语种识别结果,对所述每个待识别图像进行文本识别,生成所述目标场景图像对应的文本识别结果。
15、本申请一实施例,通过对目标场景图像进行裁剪,获得至少一个待识别图像,并分别对每个待识别图像进行语种识别,并获得每个待识别图像对应的语种识别结果,再根据每个语种识别结果,对每个待识别图像进行精准地文本识别,进而,生成目标场景图像对应的文本识别结果,实现了在多语种场景下,对带有各个语种的文本图像进行裁剪,并对裁剪后的图像再进行文本识别,以提高对图像中不同语种进行文本识别的精准度,提升图像中的文本识别效率。
技术特征:
1.一种基于图像的文本识别方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述对每个待识别图像中的文本进行语种识别,获得所述每个待识别图像对应的语种识别结果,包括:
3.根据权利要求2所述的方法,其特征在于,所述语种分类模型包括特征编码模块、全局特征解码模块;
4.根据权利要求3所述的方法,其特征在于,所述语种选择策略模块包括至少一个识别单元;
5.根据权利要求2所述的方法,其特征在于,所述语种分类模型的训练方式如下:
6.根据权利要求1所述的方法,其特征在于,所述基于所述目标场景图像中的文本位置信息,裁剪所述目标场景图像,获得至少一个待识别图像,包括:
7.根据权利要求6所述的方法,其特征在于,所述基于每个文本检测框对应的文本位置信息,裁剪所述目标场景图像,获得至少一个待识别图像,包括:
8.根据权利要求1-7任意一项所述的方法,其特征在于,所述基于所述每个待识别图像对应的语种识别结果,对所述每个待识别图像进行文本识别,生成所述目标场景图像对应的文本识别结果,包括:
9.根据权利要求8所述的方法,其特征在于,所述对所述每个待识别图像进行文本识别,生成所述目标场景图像对应的文本识别结果,包括:
10.根据权利要求1所述的方法,其特征在于,所述确定目标场景图像,包括:
11.一种基于图像的文本识别装置,其特征在于,包括:
12.一种计算设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机指令,其特征在于,所述处理器执行所述计算机指令时实现权利要求1-10任意一项所述方法的步骤。
13.一种计算机可读存储介质,其存储有计算机指令,其特征在于,该计算机指令被处理器执行时实现权利要求1-10任意一项所述方法的步骤。
技术总结
本申请提供基于图像的文本识别方法及装置,其中所述基于图像的文本识别方法包括:确定目标场景图像,其中,所述目标场景图像包含至少一种语种的文本;基于所述目标场景图像中的文本位置信息,裁剪所述目标场景图像,获得至少一个待识别图像;对每个待识别图像中的文本进行语种识别,获得所述每个待识别图像对应的语种识别结果;基于所述每个待识别图像对应的语种识别结果,对所述每个待识别图像进行文本识别,生成所述目标场景图像对应的文本识别结果;实现了在多语种场景下,对带有各个语种的文本图像进行裁剪,并对裁剪后的图像再进行文本识别,以提高对图像中不同语种进行文本识别的精准度,提升图像中的文本识别效率。
技术研发人员:冯舒扬,张婕蕾
受保护的技术使用者:上海哔哩哔哩科技有限公司
技术研发日:
技术公布日:2024/3/17
- 还没有人留言评论。精彩留言会获得点赞!