基于级联Transformer的端到端车辆姿态估计方法与流程
本发明属于车辆姿态估计,尤其涉及一种基于级联transformer的端到端车辆姿态估计方法。
背景技术:
1、随着深度学习、智能物联、5g通信等技术的飞跃式发展,无人驾驶(或称为自动驾驶)和智能交通吸引了很多研究者的兴趣,成为许许多多研究者的研究焦点。从社会的长远发展来看,无人驾驶/智能交通也必然成为今后城市社会发展的必由趋势,车辆的智能化识别也自然成为智能化城市发展的不可或缺的一部分。车辆姿态估计任务的目标就是从rgb图片中定位出车辆的关键点,这些关键点是我们人为设定的具有特殊含义的特点。车辆姿态估计可以很好的帮助我们确定车辆的姿态信息,有利于车辆的智能化管理,成为智能化城市的一部分。近年来,随着深度学习的迅速发展,使用卷积神经网络的车辆姿态估计方法不断刷新精度上限,但是由于卷积核的感受野有限,使得卷积神经网络仅能在图像的局部提取特征信息。transformer的诞生便是来解决卷积神经网络的这一局限性,transformer将图片划分成许多大小相等的图像块,然后对这些图像块执行矩阵计算从而构建不同图像块之间的依赖关系,这种机制可以提取到原始图像的全局特征信息。最近许多基于transformer的深度学习模型在计算机视觉领域中大放光彩,取得了比卷积神经网络更加优秀的识别精度,这也证明了transformer的独特魅力。
2、现有的车辆姿态估计方法大体划分为两类,即自上而下的方法和自下而上的方法,其中自上而下的车辆姿态估计方法是先从rgb图片中检测出车辆位置,然后根据车辆检测框从原始图片中截取带有车辆区域的小图,最后对小图进行车辆关键检测;自下而上的车辆姿态估计方法是直接在原始rgb图片中预测出所有可能的车辆关键点,然后使用分组后处理操作将预测出的关键点划分到不同的车辆类别中,这两类车辆姿态估计方法各有利弊,自上而下的方法可以做成端到端的,从而便于集成到下游任务的智能化系统中,但是此类方法往往识别精度比较低,对模型设计要求更高;自下而上的方法识别精度更高,但是由于复杂的分组后处理操作,往往无法做成端到端的。
3、由此可见,针对现实世界的复杂环境,车辆姿态估计任务急需一种精度更高的可以做成端到端的姿态估计方法。
技术实现思路
1、为了克服上述现有技术的不足,本发明提供一种基于级联transformer的端到端车辆姿态估计方法,用来解决自上而下的车辆姿态估计方法精度普遍不高的问题,可用于现实复杂场景的车辆姿态估计任务,实现高效的车辆姿态估计。
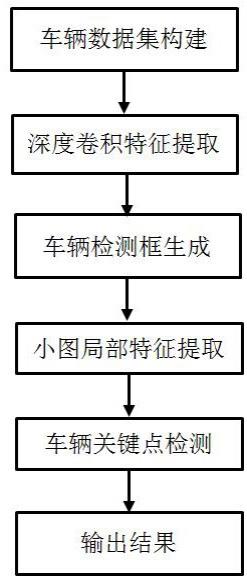
2、为实现上述目的,本发明先使用resnet网络提取图片的浅层特征,再使用transformer模块定位车辆位置,获取车辆检测框,根据车辆检测框剪切出车辆小图,然后再次使用resnet网络对小图提取更深层次的特征,最后使用transformer模块预测车辆的关键点,具体包括如下步骤:
3、(1)收集道路交通监控、公共停车场中包含各种复杂情况的车辆图片,同时收集公开数据集中包含车辆的图片,构建车辆姿态估计数据集,并对数据集中车辆标注外接矩形框和人工定义的78个关键点,将构建的数据集划分为训练集、测试集和验证集;
4、(2)对图片的尺寸和数值范围行初始化处理后输入到主干网络中提取深度卷积特征;
5、(3)使用transformer模块对步骤(2)提取的深度卷积特征进行处理,生成车辆检测框;
6、(4)根据(3)得到的车辆检测框坐标信息,从输入图片中截取只包含车辆的小图,对小图使用resnet101网络进一步提取局部特征;
7、(5)根据步骤(4)提取的局部特征,使用transformer检测关键点;
8、(6)训练网络结构,得到训练好的车辆姿态估计网络,并将车辆图片输入训练好的车辆姿态估计网络中,输出车辆姿态估计结果。
9、作为本发明的进一步技术方案,步骤(2)所述主干网络为restnet101。
10、作为本发明的进一步技术方案,步骤(3)所述transformer模块包含编码器(encoder)和解码器(decoder)两部分,其中编码器进行注意力机制的计算,对特征图进行全局分析;解码器除执行注意力机制的计算,还有分类分支和坐标点预测分支两个回归分支,用于实现类别预测和检测框坐标点的预测,其中分类分支判断目标是否为车辆,坐标点预测分支预测检测框左上角的xy坐标以及检测框的长和宽(共4个值)。
11、作为本发明的进一步技术方案,步骤(5)的具体过程为:
12、(5-1)transformer模块的编码器执行注意力机制计算,对车辆特征进行全局分析,其中注意力机制计算用以下公式解释:
13、,
14、,
15、其中,x为输入特征序列,y为输出特征,为参数矩阵;
16、(5-2)transformer模块的解码器除步骤(5-1)注意力机制计算外,还有类别分支和坐标回归分支,其中类别分支用来预测是78个关键点中的哪个点,坐标回归分支用来预测该点的xy坐标,在该过程中存在损失函数,损失函数包含类别损失和关键点坐标损失两部分,其中使用常数和来平衡这两部分损失,用以下公式表示:
17、,
18、,
19、,
20、其中为第i个关键点的真实类别,为第i个关键点的预测类别;为第i个关键点的真实坐标,为第i个关键点的预测坐标;n为图片中关键点的数量。
21、作为本发明的进一步技术方案,步骤(6)训练网络结构的具体过程为:使用数据集中训练集的图片,将图片尺寸调整为,按照每次迭代所需的图片张数,依次输入到网络中,输出车辆的分类置信度和回归坐标位置,经过200 次完整的迭代训练后,保存验证集上结果最好的模型参数,作为最终模型训练好的参数,即得到训练好的车辆姿态估计网络。
22、与现有技术相比,本发明的有益效果是:
23、本发明提供了一种基于级联transformer的端到端的车辆姿态估计方法,先后使用resnet101卷积神经网络分别提取输入图像的局部特征和车辆小图的局部特征,然后使用级联transformer架构分别检测车辆的坐标位置和车辆的关键点坐标,通过使用transformer独特的注意力机制对特征图进行全局分析,实现高精度的关键点检测,而且这种级联架构在端到端训练的基础上,实现了更高精度的姿态估计,具有较高的实际应用价值。
技术特征:
1.一种基于级联transformer的端到端车辆姿态估计方法,其特征在于,具体过程为:
2.根据权利要求1所述基于级联transformer的端到端车辆姿态估计方法,其特征在于,步骤(2)所述主干网络为restnet101。
3.根据权利要求1所述基于级联transformer的端到端车辆姿态估计方法,其特征在于,步骤(3)所述transformer模块包含编码器和解码器两部分,其中编码器进行注意力机制的计算,对特征图进行全局分析;解码器除执行注意力机制的计算,还有分类分支和坐标点预测分支两个回归分支,用于实现类别预测和检测框坐标点的预测,其中分类分支判断目标是否为车辆,坐标点预测分支预测检测框左上角的xy坐标以及检测框的长和宽。
4.根据权利要求1所述基于级联transformer的端到端车辆姿态估计方法,其特征在于,步骤(5)的具体过程为:
5.根据权利要求1所述基于级联transformer的端到端车辆姿态估计方法,其特征在于,步骤(6)训练网络结构的具体过程为:使用数据集中训练集的图片,将图片尺寸调整为,按照每次迭代所需的图片张数,依次输入到网络中,输出车辆的分类置信度和回归坐标位置,经过200 次完整的迭代训练后,保存验证集上结果最好的模型参数,作为最终模型训练好的参数,即得到训练好的车辆姿态估计网络。
技术总结
本发明属于车辆姿态估计技术领域,尤其涉及一种基于级联Transformer的端到端车辆姿态估计方法,先后使用ResNet101卷积神经网络分别提取输入图像的局部特征和车辆小图的局部特征,然后使用级联Transformer架构分别检测车辆的坐标位置和车辆的关键点坐标,通过使用Transformer独特的注意力机制对特征图进行全局分析,实现高精度的关键点检测,而且这种级联架构在端到端训练的基础上,实现了更高精度的姿态估计,具有较高的实际应用价值。
技术研发人员:刘寒松,王永,王国强,刘瑞,谭连盛,董玉超
受保护的技术使用者:松立控股集团股份有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!