一种用于文本分类的注意力增强预训练方法和装置与流程
本发明一般涉及文本分类领域,并且更具体地,涉及一种用于文本分类的注意力增强预训练方法和装置。
背景技术:
1、公民投诉案件是一类极其依赖关键词表征词信息来表达整个案件语义信息的文本数据,例如两条整体结构相似的语句:a:市民反映,我在星临街道购买的台灯不亮;b:市民反映,我在星临街道看到路灯不亮;往往会由于特殊关键词购买的出现,而造成整个语义的巨变,显然a语句应派送到消费者协会来解决,b语句应派送到基层居委会来解决。现有的传统文本分类模型,如rnn、lstm及双向lstm模型,往往是以单一词向量的形式来挖掘整个句子的语义,因此它忽视了在整个语句的学习中,为不同词向量添加不同的注意力,transformer结构虽然是完全基于注意力机制来实现分类任务的,但是他缺少了对整个数据库知识的宏观利用。由于公民投诉案件事发场景较多、分类界限模糊且依赖关键词表征信息的特性,所以很难用现有的技术来获得一个不错的分类效果。
技术实现思路
1、根据本发明的实施例,提供了一种用于文本分类的注意力增强预训练方案。本方案改进词频统计的方法,利用总体语料库信息,挖掘关键词增强向量,对关键词信息进行增强,不仅大大提高了分类准确率,而且还提高了整体网络结构的可解释性。
2、在本发明的第一方面,提供了一种注意力增强方法。该方法包括:
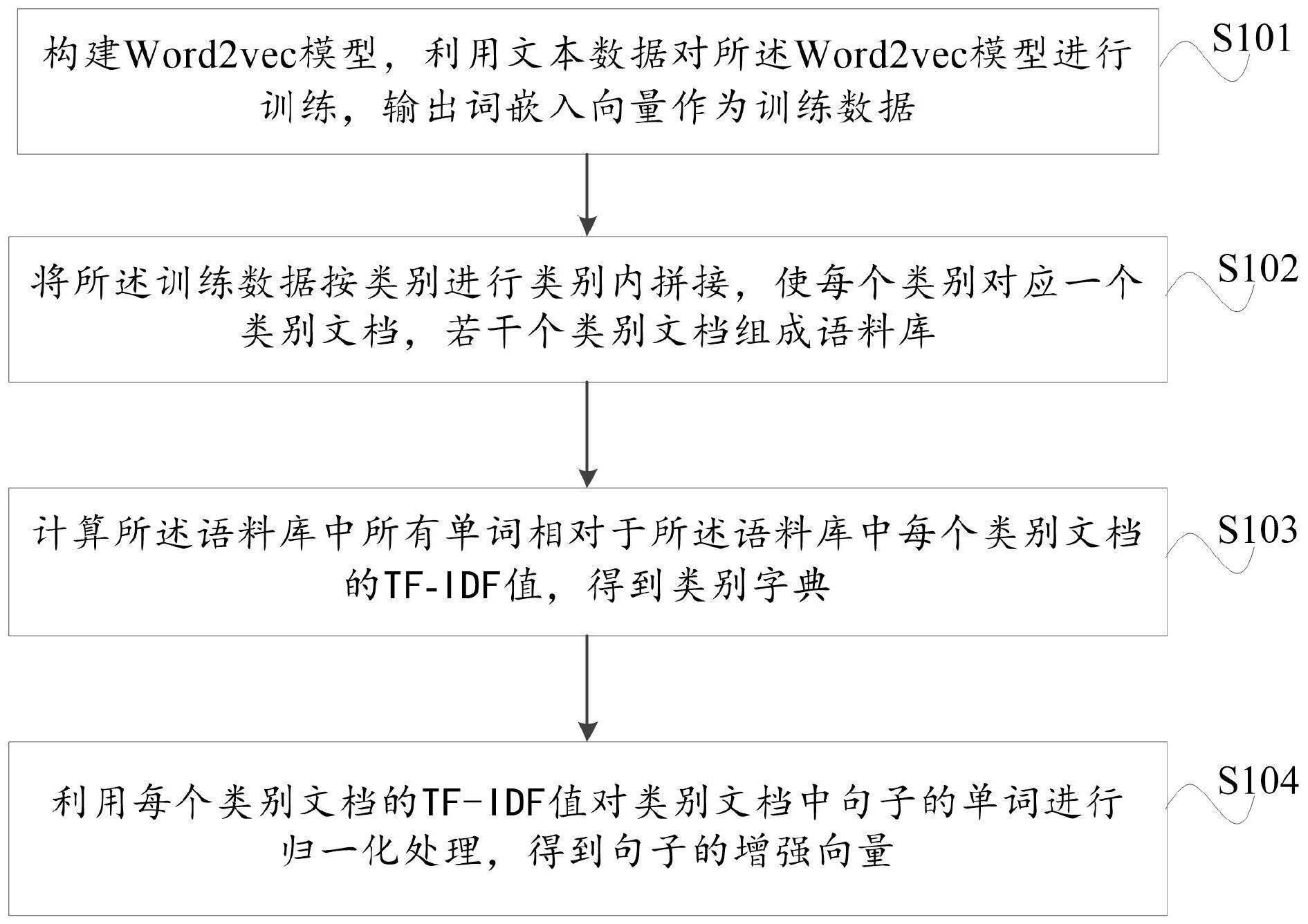
3、构建word2vec模型,利用文本数据对所述word2vec模型进行训练,输出词嵌入向量作为训练数据;
4、将所述训练数据按类别进行类别内拼接,使每个类别对应一个类别文档,若干个类别文档组成语料库;
5、计算所述语料库中所有单词相对于所述语料库中每个类别文档的tf-idf值,得到类别字典;
6、利用每个类别文档的tf-idf值对类别文档中句子的单词进行归一化处理,得到句子的增强向量。
7、进一步地,所述word2vec模型,包括skip-gram模型和cbow模型;
8、所述skip-gram模型,用于通过将单词的one-hot编码作为输入,预测上下文单词;
9、所述cbow模型,用于通过输入上下文单词,对单词进行预测,输出768维度的词嵌入向量。
10、进一步地,若所述训练数据为中文数据,则对所述训练数据进行分词处理。
11、进一步地,所述类别字典包括:
12、
13、其中,dj代表第j个类别字典,n表示类别字典的个数;wi为对应类别中出现的第i个单词;tj,i为第j个类别字典中wi所对应的tf-idf值;a表示第一个类别字典中单词的个数;b表示第二个类别字典中单词的个数;c表示第j个类别字典中单词的个数;d表示第n个类别字典中单词的个数。
14、进一步地,还包括对所述类别字典进行统一:
15、d[wi]=max(d1[wi],d2[wi],d3[wi],…,dn[wi])
16、其中,d[wi]为统一的类别字典。
17、进一步地,所述利用每个类别文档的tf-idf值对类别文档中句子的单词进行归一化处理,得到句子的增强向量,包括:
18、
19、
20、其中,k(w1)为单词w1对应的关注度系数;vh为句子的增强向量;x、y、z为单词的词嵌入向量;wi为句子中出现的单词;tf-idf(wi)为对应单词wi的tf-idf值。
21、在本发明的第二方面,提供了一种用于文本分类的注意力增强预训练方法。该方法包括:
22、利用bert网络多头注意力模型对输入文本数据进行语义提取,输出句子表征向量;以及
23、利用如上述本发明的第一方面所述的注意力增强方法得到句子关键词增强向量;
24、将所述句子表征向量和句子增强向量进行融合,得到句子向量;
25、将所述句子向量输入全连接层,通过softmax函数进行分类,输出分类结果。
26、进一步地,所述bert网络多头注意力模型为:
27、
28、其中,q为查询向量;k为关键向量;v为权值向量;dk为缩放因子,保证梯度的平稳。
29、在本发明的第三方面,提供了一种用于文本分类的注意力增强预训练装置。该装置包括:
30、bert网络模块,用于利用bert网络多头注意力模型对输入文本数据进行语义提取,输出句子表征向量;
31、注意力增强模块,用于利用如上述本发明的第一方面所述的注意力增强方法得到句子关键词增强向量;
32、融合模块,用于将所述句子表征向量和句子增强向量进行融合,得到句子向量;
33、分类模块,用于将所述句子向量输入全连接层,通过softmax函数进行分类,输出分类结果。
34、在本发明的第四方面,提供了一种电子设备。该电子设备至少一个处理器;以及与所述至少一个处理器通信连接的存储器;所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明第二方面的方法。
35、应当理解,
技术实现要素:
部分中所描述的内容并非旨在限定本发明的实施例的关键或重要特征,亦非用于限制本发明的范围。本发明的其它特征将通过以下的描述变得容易理解。
技术特征:
1.一种注意力增强方法,应用于注意力增强网络模型,其特征在于,包括:
2.根据权利要求1所述的注意力增强方法,其特征在于,所述word2vec模型,包括skip-gram模型和cbow模型;
3.根据权利要求1所述的注意力增强方法,其特征在于,若所述训练数据为中文数据,则对所述训练数据进行分词处理。
4.根据权利要求1所述的注意力增强方法,其特征在于,所述类别字典包括:
5.根据权利要求4所述的注意力增强方法,其特征在于,还包括对所述类别字典进行统一:
6.根据权利要求1所述的注意力增强方法,其特征在于,所述利用每个类别文档的tf-idf值对类别文档中句子的单词进行归一化处理,得到句子的增强向量,包括:
7.一种用于文本分类的注意力增强预训练方法,其特征在于,包括:
8.根据权利要求7所述的用于文本分类的注意力增强预训练方法,其特征在于,所述bert网络多头注意力模型为:
9.一种用于文本分类的注意力增强预训练装置,其特征在于,包括:
10.一种电子设备,包括至少一个处理器;以及
技术总结
本发明的实施例提供了一种用于文本分类的注意力增强预训练方法和装置。所述方法包括利用BERT网络多头注意力模型对输入文本数据进行语义提取,输出句子表征向量;以及利用注意力增强方法得到句子关键词增强向量;将句子表征向量和句子增强向量进行融合,得到句子向量输入全连接层,通过Softmax函数进行分类,输出分类结果。以此方式,可以改进词频统计的方法,利用总体语料库信息,挖掘关键词增强向量,对关键词信息进行增强,不仅大大提高了分类准确率,而且还提高了整体网络结构的可解释性。
技术研发人员:王静宇,王远航,李建华,马亚中,李蹊,郭宝松,张聪聪
受保护的技术使用者:中关村科学城城市大脑股份有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!