一种基于原型选择的HRRP识别数据库构建方法
本发明属于雷达,具体涉及一种基于原型选择的hrrp识别数据库构建方法。
背景技术:
1、随着雷达软件与硬件技术的长足发展,雷达高分辨距离像(high resolutionrange profile,hrrp)数据空前激增。面对如此海量的数据,以机器学习尤其是深度学习为核心的雷达hrrp目标识别技术得到了长足的发展。然而,hrrp数据在量上的膨胀未必能带来在质上的提高,海量数据虽然为基于数据驱动的机器学习方法获取有价值信息提供了充分空间,但是,繁多复杂数据的高维度、过冗余以及高噪声的特性,不但会造成存储资源以及计算资源的巨大浪费,而且还会显著提升学习算法的复杂度。更严重的是,繁多复杂的数据还会将真正有价值的信息湮没,导致机器学习性能的恶化。
技术实现思路
1、为了解决现有技术中存在的上述问题,本发明提供了一种基于原型选择的hrrp识别数据库构建方法。本发明要解决的技术问题通过以下技术方案实现:
2、本发明提供了一种基于原型选择的hrrp识别数据库构建方法,包括:
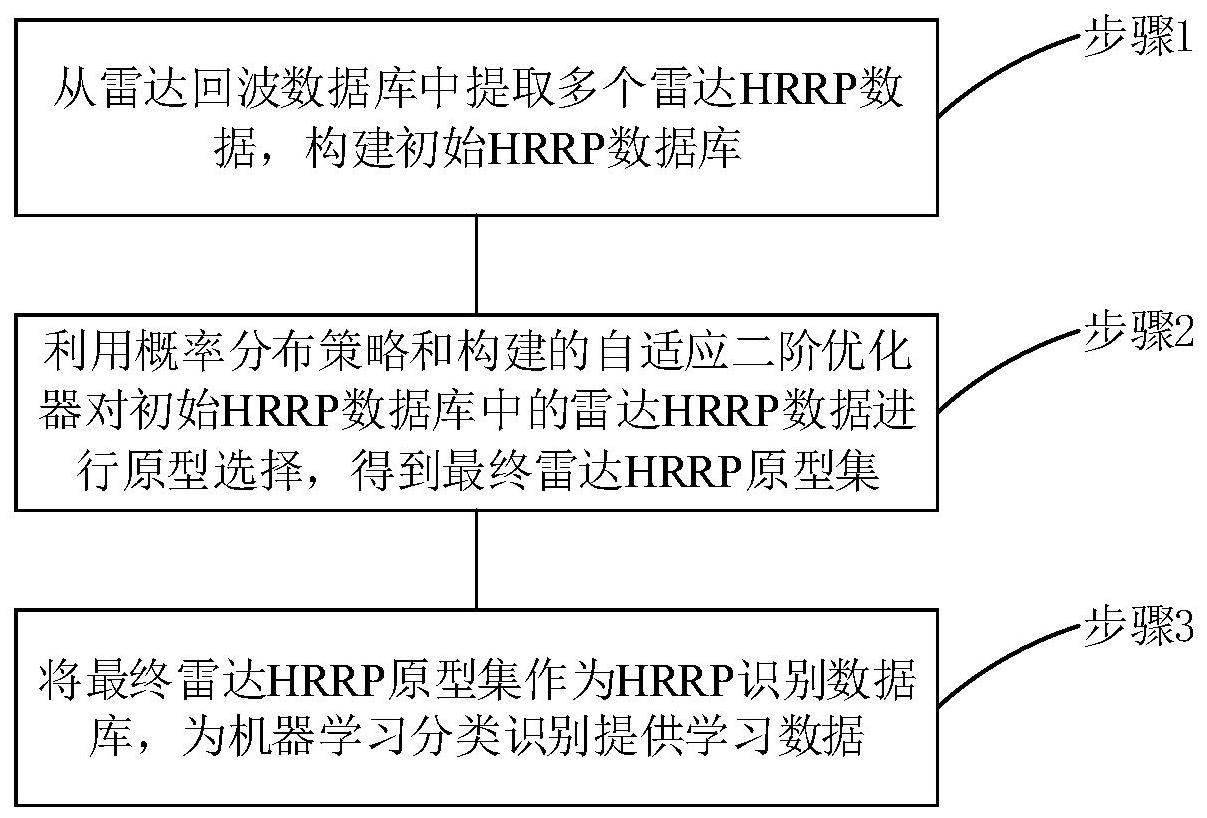
3、步骤1:从雷达回波数据库中提取多个雷达hrrp数据,构建初始hrrp数据库;
4、步骤2:利用概率分布策略和构建的自适应二阶优化器对所述初始hrrp数据库中的雷达hrrp数据进行原型选择,得到最终雷达hrrp原型集;
5、步骤3:将所述最终雷达hrrp原型集作为hrrp识别数据库,为机器学习分类识别提供学习数据。
6、在本发明的一个实施例中,所述多个雷达hrrp数据包括不同识别类别的多个雷达hrrp数据。
7、在本发明的一个实施例中,所述步骤2包括:
8、步骤2.1:初始化雷达hrrp原型集的大小为k,根据初始的采样概率对所述初始hrrp数据库中的每个雷达hrrp数据样本的权值进行赋值,得到初始的雷达hrrp原型集;
9、步骤2.2:将所述雷达hrrp原型集输入至深度神经网络,对所述深度神经网络进行训练直至网络收敛,在训练过程中利用构建的自适应二阶优化器对网络参数进行更新;
10、步骤2.3:将所述初始hrrp数据库中所有雷达hrrp数据样本,输入至收敛的深度神经网络中获取损失值,对采样概率进行反向传播更新;
11、步骤2.4:根据更新的采样概率对所述初始hrrp数据库中的每个雷达hrrp数据样本的权值进行赋值,得到新的雷达hrrp原型集;
12、步骤2.5:重复步骤2.2-步骤2.4直至达到预设的迭代次数,利用最后一次迭代得到的更新的采样概率对所述初始hrrp数据库中的每个雷达hrrp数据样本的权值进行赋值,得到所述最终雷达hrrp原型集。
13、在本发明的一个实施例中,每个雷达hrrp数据样本的权值的初始的采样概率为d表示初始hrrp数据库的大小。
14、在本发明的一个实施例中,每个雷达hrrp数据样本的权值mi∈{0,1},mi=1表示雷达hrrp数据样本i被选入原型集,mi=0表示雷达hrrp数据样本i未被选入原型集;
15、其中,每个权值mi表示为伯努利随机变量,以概率si和1-si取1和0为mi的值,所有雷达hrrp数据样本的权值m的分布函数为:
16、
17、式中,si表示雷达hrrp数据样本i的采样概率,n表示初始hrrp数据库的大小。
18、在本发明的一个实施例中,在所述步骤2.2中,在训练过程中利用构建的自适应二阶优化器对网络参数进行更新,包括以下步骤:
19、步骤a:将所述雷达hrrp原型集输入至深度神经网络,利用反向传播算法得到网络参数的一阶梯度;
20、步骤b:使用rademacher分布生成一个维度与一阶梯度相同的随机向量,利用下式计算得到网络参数的二阶梯度的对角线:
21、
22、式中,θ表示网络参数,g表示网络参数的一阶梯度,d表示网络参数的二阶梯度的对角线,h表示网络参数的二阶梯度,diag()表示对角矩阵函数,⊙表示元素点对点相乘,z表示随机向量,t表示转置;
23、步骤c:利用动量方法对网络参数的一阶梯度和二阶梯度的对角线进行处理:
24、
25、
26、式中,mt表示第t次网络更新的一阶矩估计,vt表示第t次网络更新的二阶矩估计,β1=0.9,β2=0.999,k=1,t表示第t次网络的反向传播过程;
27、步骤d:利用下式完成网络参数的更新:
28、θt+1=θt-ηmt/vt;
29、式中,η表示学习率,其值为0.01。
30、在本发明的一个实施例中,在所述步骤2.3中,按照下式对采样概率进行反向传播更新:
31、
32、式中,sk+1表示第k+1次迭代后采样概率,sk表示第k次迭代后的采样概率,η表示学习率,其值为0.01,l表示损失值,p(m|sk)表示所有雷达hrrp数据样本的权值m的分布函数。
33、与现有技术相比,本发明的有益效果在于:
34、本发明的基于原型选择的hrrp识别数据库构建方法,在雷达hrrp数据库内样本过多时,利用概率分布与自适应二阶优化器,相比于传统的方法可以在保证较低的计算复杂度的同时保证挖掘出hrrp数据中最具价值的信息以生成最终雷达hrrp原型集,该最终雷达hrrp原型集作为hrrp识别数据库,为后续机器学习分类识别提供最具价值的学习数据,一方面可以节约存储资源与计算资源,另一方面避免了由于学习数据复杂导致的机器学习性能恶化的问题。
35、上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
技术特征:
1.一种基于原型选择的hrrp识别数据库构建方法,其特征在于,包括:
2.根据权利要求1所述的基于原型选择的hrrp识别数据库构建方法,其特征在于,所述多个雷达hrrp数据包括不同识别类别的多个雷达hrrp数据。
3.根据权利要求1所述的基于原型选择的hrrp识别数据库构建方法,其特征在于,所述步骤2包括:
4.根据权利要求3所述的基于原型选择的hrrp识别数据库构建方法,其特征在于,每个雷达hrrp数据样本的权值的初始的采样概率为d表示初始hrrp数据库的大小。
5.根据权利要求4所述的基于原型选择的hrrp识别数据库构建方法,其特征在于,每个雷达hrrp数据样本的权值mi∈{0,1},mi=1表示雷达hrrp数据样本i被选入原型集,mi=0表示雷达hrrp数据样本i未被选入原型集;
6.根据权利要求3所述的基于原型选择的hrrp识别数据库构建方法,其特征在于,在所述步骤2.2中,在训练过程中利用构建的自适应二阶优化器对网络参数进行更新,包括以下步骤:
7.根据权利要求3所述的基于原型选择的hrrp识别数据库构建方法,其特征在于,在所述步骤2.3中,按照下式对采样概率进行反向传播更新:
技术总结
本发明涉及一种基于原型选择的HRRP识别数据库构建方法,包括:步骤1:从雷达回波数据库中提取多个雷达HRRP数据,构建初始HRRP数据库;步骤2:利用概率分布策略和构建的自适应二阶优化器对初始HRRP数据库中的雷达HRRP数据进行原型选择,得到最终雷达HRRP原型集;步骤3:将最终雷达HRRP原型集作为HRRP识别数据库,为机器学习分类识别提供学习数据。本发明的基于原型选择的HRRP识别数据库构建方法,在雷达HRRP识别数据库中样本过多的情况下,从HRRP数据库选取最具价值的样本构成最终雷达HRRP原型集,该最终雷达HRRP原型集作为HRRP识别数据库,为后续机器学习分类识别提供最具价值的学习数据,以节约存储资源与计算资源。
技术研发人员:王鹏辉,刘宏伟,杨浩蔚
受保护的技术使用者:西安电子科技大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!