基于BERT预训练模型的可访问性问题报告的自动识别方法
本发明属于智能化软件开发领域,具体涉及一种基于bert预训练模型的可访问性问题报告的自动识别方法。
背景技术:
1、可访问设计的重点是让尽可能多的人能够访问软件产品和服务,这已经引起了软件工程研究人员和开发人员的广泛关注。但是,目前许多应用程序的可访问性较差,这使得残疾人难以使用此类应用程序。鉴于此,研究人员作出了大量的努力,陆续提出了一些工具、框架以及指南,以支持开发人员创建可访问性的应用程序。然而,由于缺乏意识和资源,许多开发人员和设计师仍然没有将可访问性纳入开发过程。因此,研究现实世界的项目中关于可访问性所引发的问题对可访问性的研究及发展有着非常重要的意义。
2、github是一个大型且受欢迎的开源平台,托管各种项目。开发人员使用“issue”报告项目中的问题和错误,因此使用github项目中的问题讨论作为数据源能够使得研究结论更加具有代表性,从而能够更好地促进可访问性研究的发展。
3、目前研究人员在进行可访问性相关问题的研究过程中收集数据主要使用两种方法:人工标记和自动检测。人工标记的方式非常耗时,尤其在面对大型开源平台github中数百万计的数据时,人工标记变得不切实际。自动检测方法采用字符串匹配技术,自动检测方法所使用的关键词来源于英国广播公司(bbc)关于可访问性的建议。然而,仅仅使用指南中派生出的关键字并不能够排除部分假阳性问题,比如,涉及到访问控制符的问题讨论同样使用“accessibility”。因此,依赖于上下文的可访问性问题报告的识别仅仅简单使用字符串匹配技术是低效的。
技术实现思路
1、针对于上述现有技术的不足,本发明的目的在于提供一种基于bert预训练模型的可访问性问题报告的自动识别方法。
2、本发明为了实现上述目的,采用如下技术方案:
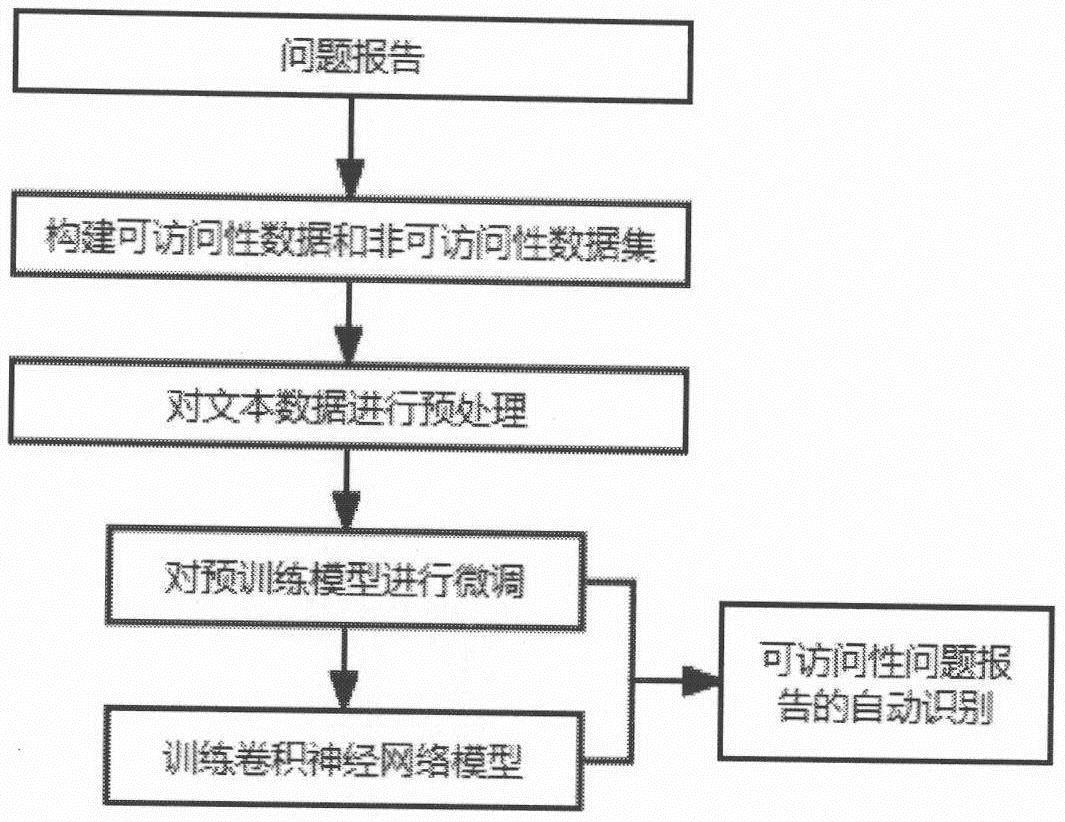
3、基于bert预训练模型的可访问性问题报告的自动识别方法,包括如下步骤:
4、步骤1.收集大型流行项目中的问题报告,其中包括标题、描述以及commit信息,构建可访问性相关数据集和非可访问性数据集;
5、对于可访问性数据集的构建,我们首先根据关键词初步筛选出预备可访问性数据集,经过手动验证确定所选数据为非假阳性数据;
6、对于非可访问性数据集的构建,我们首先加入在构建可访问性数据集过程中所获得的假阳性数据,随即抽取相同项目中不含关键词的问题报告,并人工确定;
7、对于可访问性与非可访问性数据集分别添加标签1和0,再统一进行相同规则的数据预处理,从而生成目标数据集。
8、步骤2.将目标数据集输入到预训练模型中对预训练模型进行微调;
9、每个数据样本输入到微调后的预训练模型中均会得到cls向量;
10、步骤3.将向量输入到卷积神经网络中进行卷积和池化操作以提取特征,再输入到全连接层训练,得到卷积神经网络分类模型;
11、步骤4.将未经过标记的问题报告输入到由微调后的预训练模型以及训练好的卷积神经网络分类模型组成的整体模型中,继而实现自动识别可访问性相关的数据以构成研究所需的数据集。
12、本发明具有如下优点:
13、如上所述,本发明述及了一种基于bert预训练模型的可访问性问题报告的自动识别方法,对于github中可访问性问题报告的自动识别通过bert预训练模型,以更好的提取问题报告中的文本语义信息,从而提高了对问题报告的语义理解能力,从而提高识别可访问性问题报告的准确率;此外,本发明方法通过所采用的预训练模型能够保证在训练数据较少的情况下,也能够达到很好地效果,同时能够提高运行效率,进而保证软件质量以及软件的可追溯性,降低了软件的维护成本。本发明很好地解决了在可访问性问题研究领域数据不足和数据收集困难等问题,能够大大节省研究人员的时间,提升研究效率,从而进一步促进该研究领域的发展。
技术特征:
1.一种基于bert预训练模型的可访问性问题报告的自动识别方法,其特征在于,包括步骤如下:
2.根据权利要求1所述的基于bert预训练模型的可访问性问题报告的自动识别方法,其特征在于,
3.根据权利要求2所述的基于bert预训练模型的可访问性问题报告的自动识别方法,其特征在于,
4.根据权利要求3所述的基于bert预训练模型的可访问性问题报告的自动识别方法,其特征在于,
5.根据权利要求4所述的基于bert预训练模型的可访问性问题报告的自动识别方法,其特征在于,
技术总结
本发明属于软件缺陷检测技术领域,公开了一种基于BERT预训练模型的可访问性问题报告的自动识别方法。该方法利用当下表现出色的BERT模型以实现Github中可访问性问题报告的自动识别,采用一系列有效的预处理技术完成数据收集和处理工作,选取经过预训练的seBERT模型微调,更好地提取Github问题报告中关于可访问性的语义信息,使得模型在训练数据较少的情况下也能有较好的效果,提高研究者采集可访问性相关数据时的准确率;最后通过卷积神经网络完成二分类工作,从而成功从大量未知类型的问题报告中筛选出目标数据。本发明通过使用预训练模型,以解决神经网络和机器学习训练数据不足的问题,使得自动分类方法能够成功地应用于数据样本采样困难的可访问性研究领域。
技术研发人员:赵雅欣,周宇
受保护的技术使用者:南京航空航天大学
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!