文本分类方法、装置、设备及计算机可读存储介质与流程
本公开涉及自然语言处理,尤其涉及一种文本分类方法、装置、设备及计算机可读存储介质。
背景技术:
1、自然语言处理中,文本分类任务是至对给定文本进行情感倾向分类的任务,进而可以根据文本分类的结果进行功能性答复。例如,对用户发起的指令进行领域分类,需要识别出是否是问答任务,或者对用户的意图进行识别,比如天气查询、歌曲搜索、随机闲聊等。
2、对于文本分类任务,目前通常的做法是通过注意力模型学习文本中的信息,计算文本中各个单词对于目标词的情感倾向影响的权重。
3、然而标准的注意力机制过分依赖于神经网络来学习上下文结构信息,并在单个单词的隐藏上执行特征的提取,而与目标词相关联的意见表达式往往都是一个连贯的观点跨度,而不是散落在句子中的单个单词,因此现有的文本分类方式的准确性仍有待提高。
技术实现思路
1、为了解决上述技术问题,本公开提供了一种文本分类方法、装置、设备及计算机可读存储介质,以提高文本分类方法的准确性。
2、第一方面,本公开实施例提供一种文本分类方法,包括:
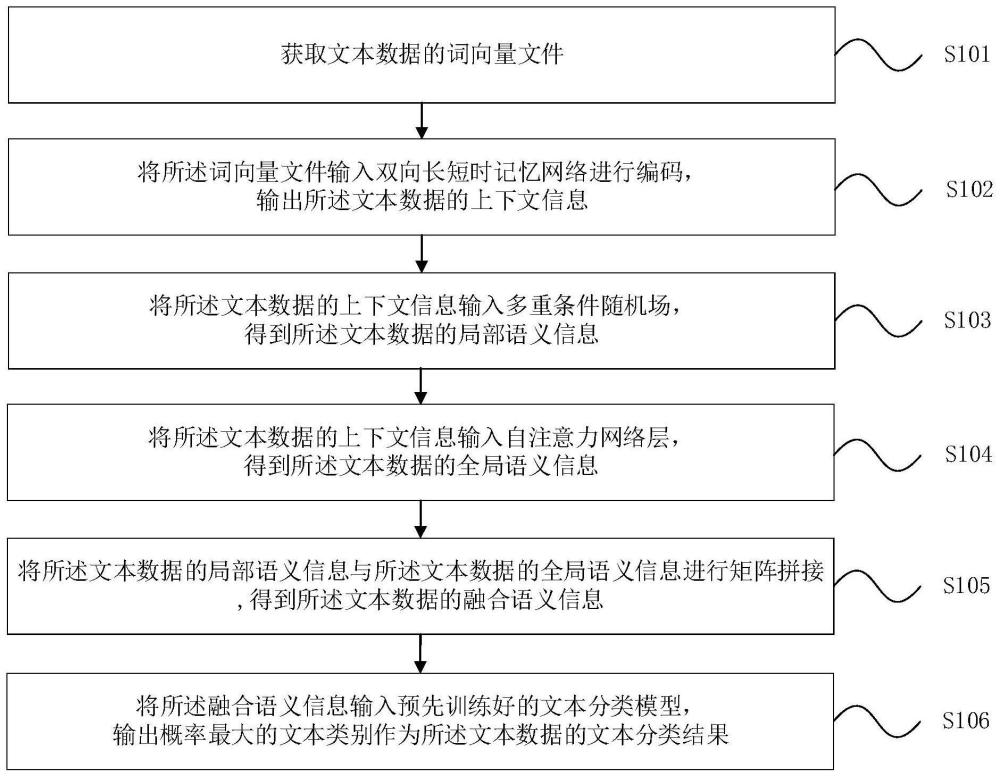
3、获取文本数据的词向量文件;
4、将所述词向量文件输入双向长短时记忆网络进行编码,输出所述文本数据的上下文信息;
5、将所述文本数据的上下文信息输入多重条件随机场,得到所述文本数据的局部语义信息,所述局部语义信息用于表征所述文本数据的结构信息;
6、将所述文本数据的上下文信息输入自注意力网络层,得到所述文本数据的全局语义信息,所述全局语义信息用于表征所述文本数据中单词的注意力权重;
7、将所述文本数据的局部语义信息与所述文本数据的全局语义信息进行矩阵拼接,得到所述文本数据的融合语义信息;
8、将所述融合语义信息输入预先训练好的文本分类模型,输出概率最大的文本类别作为所述文本数据的文本分类结果。
9、在一些实施例中,所述获取文本数据的词向量文件,包括:
10、获取待分类文本;
11、对所述待分类文本进行分词操作,并去除所述待分类文本中的停用词,得到文本数据;
12、通过开源工具对所述文本数据进行词向量训练,得到文本数据的词向量文件。
13、在一些实施例中,所述将所述词向量文件输入双向长短时记忆网络进行编码,输出所述文本数据的上下文信息,包括:
14、使用正向长短时记忆网络对所述词向量文件中的每个单词进行编码,得到从左向右的序列信息;
15、使用反向长短时记忆网络对所述词向量文件中的每个单词进行编码,得到从右向左的序列信息;
16、将基于所述从左向右的序列信息以及所述从右向左的序列信息进行拼接,得到所述文本数据的上下文信息进行输出。
17、在一些实施例中,所述将所述文本数据的上下文信息输入多重条件随机场,得到所述文本数据的局部语义信息,包括:
18、计算所述文本数据的上下文信息相对于预设标签序列的边际分布概率,所述预设标签用于表示所述文本数据是否属于该预设标签对应的文本类别的范围;
19、对每个所述预设标签所分别对应的边际分布概率进行矩阵拼接,得到所述文本数据的局部语义信息,所述边际分布概率表征所述文本数据属于该预设标签对应的文本类别的范围的可能性。
20、在一些实施例中,所述计算所述文本数据的上下文信息相对于预设标签序列的边际分布概率,包括:
21、计算所述文本数据的上下文信息相对于预设标签序列的过渡分数和发射分数之和;
22、对所述预设标签序列的过渡分数和发射分数之和进行归一化计算,得到归一化计算结果;
23、计算所述归一化计算结果相对于预设标签序列的边际分布概率。
24、在一些实施例中,所述将所述文本数据的上下文信息输入自注意力网络层,得到所述文本数据的全局语义信息,包括:
25、将所述文本数据的上下文信息输入自注意力网络层,得到所述文本数据中每个单词的权重大小;
26、基于所述每个单词的权重大小对所述文本数据的上下文信息进行加权计算,得到所述文本数据的全局语义信息。
27、在一些实施例中,所述将所述文本数据的局部语义信息与所述文本数据的全局语义信息进行矩阵拼接,得到所述文本数据的融合语义信息,包括:
28、根据用户的预设配置参数确定与所述预设配置参数对应的矩阵的拼接方向;
29、获取所述局部语义信息在所述拼接方向上的第一元素数以及所述全局语义信息在所述拼接方向上的第二元素数;
30、将所述文本数据的局部语义信息与所述文本数据的全局语义信息进行矩阵拼接,得到所述文本数据的融合语义信息,所述融合语义信息在所述拼接方向上的元素数为所述第一元素数与所述第二元素数之和。
31、第二方面,本公开实施例提供一种文本分类装置,包括:
32、获取模块,用于获取文本数据的词向量文件;
33、第一输入模块,用于将所述词向量文件输入双向长短时记忆网络进行编码,输出所述文本数据的上下文信息;
34、第二输入模块,用于将所述文本数据的上下文信息输入多重条件随机场,得到所述文本数据的局部语义信息,所述局部语义信息用于表征所述文本数据的结构信息;
35、第三输入模块,用于将所述文本数据的上下文信息输入自注意力网络层,得到所述文本数据的全局语义信息,所述全局语义信息用于表征所述文本数据中单词的注意力权重;
36、拼接模块,用于将所述文本数据的局部语义信息与所述文本数据的全局语义信息进行矩阵拼接,得到所述文本数据的融合语义信息;
37、分类模块,用于将所述融合语义信息输入预先训练好的文本分类模型,输出概率最大的文本类别作为所述文本数据的文本分类结果。
38、第三方面,本公开实施例提供一种电子设备,包括:
39、存储器;
40、处理器;以及
41、计算机程序;
42、其中,所述计算机程序存储在所述存储器中,并被配置为由所述处理器执行以实现如第一方面所述的方法。
43、第四方面,本公开实施例提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行以实现第一方面所述的方法。
44、本公开实施例提供的文本分类方法、装置、设备及计算机可读存储介质,通过引入条件随机场来捕获文本中相邻单词间的结构依赖性,使用注意力机制提取文本的全局语义表示,进而使得二者拼接所得到的融合信息能够具备基于连贯的观点跨度所表达的语义信息,使得基于融合信息进行的分类能够更加贴近文本数据的意图,提高了文本分类的准确性。
技术特征:
1.一种文本分类方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述获取文本数据的词向量文件,包括:
3.根据权利要求1所述的方法,其特征在于,所述将所述词向量文件输入双向长短时记忆网络进行编码,输出所述文本数据的上下文信息,包括:
4.根据权利要求1所述的方法,其特征在于,所述将所述文本数据的上下文信息输入多重条件随机场,得到所述文本数据的局部语义信息,包括:
5.根据权利要求4所述的方法,其特征在于,所述计算所述文本数据的上下文信息相对于预设标签序列的边际分布概率,包括:
6.根据权利要求1所述的方法,其特征在于,所述将所述文本数据的上下文信息输入自注意力网络层,得到所述文本数据的全局语义信息,包括:
7.根据权利要求1所述的方法,其特征在于,所述将所述文本数据的局部语义信息与所述文本数据的全局语义信息进行矩阵拼接,得到所述文本数据的融合语义信息,包括:
8.一种文本分类装置,其特征在于,所述装置包括:
9.一种电子设备,其特征在于,包括:
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1-7中任一项所述的方法。
技术总结
本公开涉及一种文本分类方法、装置、设备及计算机可读存储介质,该方法包括:获取文本数据的词向量文件;将词向量文件输入双向长短时记忆网络进行编码,输出文本数据的上下文信息;将文本数据的上下文信息输入多重条件随机场,得到文本数据的局部语义信息;将文本数据的上下文信息输入自注意力网络层,得到文本数据的全局语义信息;将文本数据的局部语义信息与文本数据的全局语义信息进行矩阵拼接,得到文本数据的融合语义信息;将融合语义信息输入预先训练好的文本分类模型,输出概率最大的文本类别作为文本数据的文本分类结果。本公开通过引入条件随机场来捕获文本中相邻单词间的结构依赖性,以提高文本分类的准确性。
技术研发人员:赵聪宇
受保护的技术使用者:北京罗克维尔斯科技有限公司
技术研发日:
技术公布日:2024/9/23
- 还没有人留言评论。精彩留言会获得点赞!