口红色号识别方法、装置、电子设备及存储介质与流程
本发明涉及图像处理,特别是涉及一种口红色号识别方法、装置、电子设备及存储介质。
背景技术:
1、在用户通过视频应用观看播放的视频时,往往会被某一个镜头中演员的口红颜色所吸引并希望获取到同样色号的口红。但是仅仅依靠人的肉眼是很难准确分辨出最接近的口红色号,因此需要通过口红识别算法来对视频中演员的口红色号进行识别。
2、现有的口红识别算法为:通过人脸检测和人脸跟踪的方法获取到镜头中演员人脸的位置,然后对每个人脸进行嘴唇分割,提取嘴唇色号,最后对同一镜头下,同一演员的嘴唇色号结果进行投票,选择嘴唇色号识别结果的top3作为最终输出的结果。
3、然而,现有的口红识别算法是针对同一镜头下的同一演员口红色号进行识别,但是针对不同镜头同一个场景下的同一演员,因为光线、色彩对比度等问题会出现不同的口红色号识别结果,导致用户获取的信息混乱,影响用户体验。
技术实现思路
1、本发明实施例的目的在于提供一种口红色号识别方法、装置、电子设备、系统及存储介质,以解决现有算法针对不同镜头同一个场景下的同一演员,因为光线、色彩对比度等问题会出现不同的口红色号识别结果,导致用户获取的信息混乱,影响用户体验的问题。具体技术方案如下:
2、在本发明实施的第一方面,首先提供了一种口红色号识别方法,该方法可以包括:
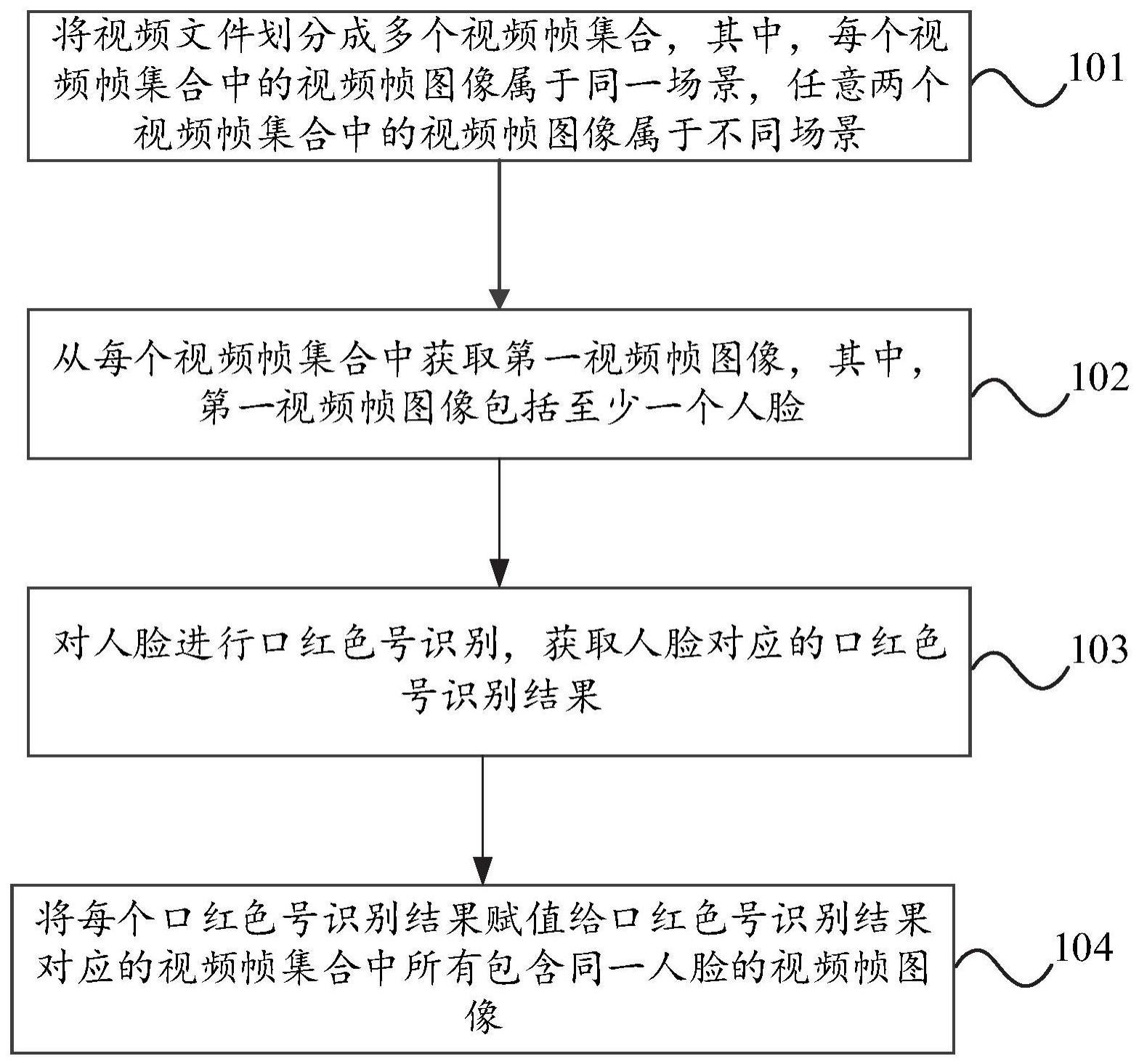
3、将视频文件划分成多个视频帧集合,其中,每个所述视频帧集合中的视频帧图像属于同一场景,任意两个所述视频帧集合中的视频帧图像属于不同场景;
4、从每个所述视频帧集合中获取第一视频帧图像,其中,所述第一视频帧图像包括至少一个人脸;
5、对所述人脸进行口红色号识别,获取所述人脸对应的口红色号识别结果;
6、将每个所述口红色号识别结果赋值给所述所述口红色号识别结果对应的所述视频帧集合中所有包含同一所述人脸的视频帧图像。
7、可选地,所述从每个所述视频帧集合中获取第一视频帧图像包括:
8、在每个所述视频帧集合中存在多个包含所述人脸的目标视频帧图像的情况下,获取所述人脸在所述目标视频帧图像中的占比数值,和/或获取所述人脸在所述目标视频帧图像中的人脸关键点数量;
9、根据所述人脸在所述目标视频帧图像中的占比数值,和/或所述人脸在所述目标视频帧图像中的人脸关键点数量,从所述目标视频帧图像中获取第一视频帧图像。
10、可选地,所述人脸在所述第一视频帧图像中的占比数值大于预先设置的第一阈值,和/或,所述人脸在所述第一视频帧图像中的人脸关键点数量大于预先设置的第二阈值。
11、可选地,所述对所述人脸进行口红色号识别,获取所述人脸对应的口红色号识别结果包括:
12、在所述第一视频帧图像数量为多个的情况下,分别对每个所述第一视频帧图像中的所述人脸进行口红色号识别,获取多个所述人脸对应的口红色号识别结果;
13、根据预先设置的选取规则,从多个所述人脸对应的口红色号识别结果中获取一个目标口红色号识别结果;
14、所述将每个所述口红色号识别结果赋值给所述口红色号识别结果对应的所述视频帧集合中所有包含同一所述人脸的视频帧图像为:
15、将所述目标口红色号识别结果赋值给每个所述视频帧集合中所有包含同一所述人脸的视频帧图像。
16、可选地,在根据所述选取规则获取多个所述人脸的口红色号识别结果对应的数量的情况下,所述目标口红色号识别结果为所述第一视频帧图像数量最多的口红色号识别结果。
17、可选地,所述从所述视频帧集合中获取第一视频帧图像之后,所述对所述人脸进行口红色号识别,获取所述人脸对应的口红色号识别结果之前,还包括:
18、从所述人脸中获取目标人脸,其中,所述目标人脸在所述第一视频帧图像中的占比数值大于预先设置的第一阈值,和/或,所述目标人脸在所述第一视频帧图像中的人脸关键点数量大于预先设置的第二阈值;
19、所述获取所述人脸对应的口红色号识别结果为:
20、获取所述目标人脸对应的口红色号识别结果。
21、可选地,所述将视频文件划分成多个视频帧集合之后,所述从所述视频帧集合中获取第一视频帧图像之前,还包括:
22、将每个所述视频帧集合均划分成多个视频帧子集合,其中,每个所述视频帧子集合中的视频帧图像属于同一个镜头,任意两个所述视频帧子集合中的视频帧图像属于不同镜头;
23、所述从所述视频帧集合中获取第一视频帧图像包括:
24、分别从多个所述视频帧子集合中获取第一视频帧图像。
25、在本发明实施的第二方面,提供了一种口红色号识别装置,该装置可以包括:
26、第一划分模块,用于将视频文件划分成多个视频帧集合,其中,每个所述视频帧集合中的视频帧图像属于同一场景,任意两个所述视频帧集合中的视频帧图像属于不同场景;
27、第一获取模块,用于从所述视频帧集合中获取第一视频帧图像,其中,所述第一视频帧图像包括至少一个人脸;
28、第二获取模块,用于对所述人脸进行口红色号识别,获取所述人脸对应的口红色号识别结果;
29、第一赋值模块,用于将每个所述口红色号识别结果赋值给所述口红色号识别结果对应的所述视频帧集合中所有包含同一所述人脸的视频帧图像。
30、本发明实施的第三方面,还提供了一种电子设备,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;
31、存储器,用于存放计算机程序;
32、处理器,用于进行存储器上所存放的程序时,进行上述任一所述的口红色号识别方法。
33、在本发明实施的第四方面,还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机进行上述任一所述的口红色号识别方法。
34、在本发明实施的第五方面,还提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机进行上述任一所述的口红色号识别方法。
35、本发明实施例提供的一种口红色号识别方法,通过将视频文件划分成多个视频帧集合,其中,每个视频帧集合中的视频帧图像属于同一场景,任意两个视频帧集合中的视频帧图像属于不同场景,从而实现将视频文件按照场景进行划分,便于后续根据场景对视频帧图像进行处理,通过从每个视频帧集合中获取第一视频帧图像,其中,第一视频帧图像包括至少一个人脸,从而实现对于视频帧集合中包括人脸的视频帧图像的筛选,避免了不包括人脸的视频帧图像的影响,最后通过对人脸进行口红色号识别,获取人脸对应的口红色号识别结果,将每个口红色号识别结果赋值给口红色号识别结果对应的视频帧集合中所有包含同一人脸的视频帧图像,可以实现将同一场景中同一人脸的口红色号的统一,避免用户获取的信息混乱,提升了用户体验。
技术特征:
1.一种口红色号识别方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述从每个所述视频帧集合中获取第一视频帧图像包括:
3.根据权利要求2所述的方法,其特征在于,所述人脸在所述第一视频帧图像中的占比数值大于预先设置的第一阈值,和/或,所述人脸在所述第一视频帧图像中的人脸关键点数量大于预先设置的第二阈值。
4.根据权利要求1所述的方法,其特征在于,所述对所述人脸进行口红色号识别,获取所述人脸对应的口红色号识别结果包括:
5.根据权利要求4所述的方法,其特征在于,在根据所述选取规则获取多个所述人脸的口红色号识别结果对应的数量的情况下,所述目标口红色号识别结果为所述第一视频帧图像数量最多的口红色号识别结果。
6.根据权利要求1所述的方法,其特征在于,所述从每个所述视频帧集合中获取第一视频帧图像之后,所述对所述人脸进行口红色号识别,获取所述人脸对应的口红色号识别结果之前,还包括:
7.根据权利要求1所述的方法,其特征在于,所述将视频文件划分成多个视频帧集合之后,所述从每个所述视频帧集合中获取第一视频帧图像之前,还包括:
8.一种口红色号识别装置,其特征在于,所述装置包括:
9.一种电子设备,其特征在于,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如权利要求1-7中任一所述的方法。
技术总结
本发明实施例提供了一种口红色号识别方法、装置、电子设备及存储介质,包括:将视频文件划分成多个视频帧集合,其中,每个视频帧集合中的视频帧图像属于同一场景,任意两个视频帧集合中的视频帧图像属于不同场景,从每个视频帧集合中获取第一视频帧图像,其中,第一视频帧图像包括至少一个人脸,对人脸进行口红色号识别,获取人脸对应的口红色号识别结果,将每个口红色号识别结果赋值给口红色号识别结果对应的视频帧集合中所有包含同一人脸的视频帧图像。本发明实施例通过将同一场景中同一演员的口红色号进行统一,避免出现用户获取信息混乱的问题,提升用户体验。
技术研发人员:雷晨曦
受保护的技术使用者:北京爱奇艺科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!