基于联邦学习和深度学习的稀疏数据聚类方法及装置与流程
本申请涉及数据处理,具体涉及一种基于联邦学习和深度学习的稀疏数据聚类方法及装置。
背景技术:
1、在现代社会中,随着信息的爆炸式增长,数据量也呈现出爆炸式增长,数据形式也越来越多样化。在数据挖掘领域,常常要面对海量的复杂型数据,其中,海量无标签且稀疏的数据正在越来越被人们所注意。
2、无标签稀疏数据可能来自于不同的平台和机构,随着数据隐私及安全保护的重要性日益提升,不同的平台和机构之间无法分享全量明文数据,而整合分析不同来源的数据能为各个专业领域的研究提供理论基础。因此,基于隐私保护技术实现无标签稀疏数据的整合,并基于深度学习方法对其进行聚类分析有重要意义。
3、目前,已有的无标签稀疏数据分析方法的主要目标是解决数据稀疏性高、技术局限导致的假0现象和不同来源数据之间的高度异质性问题;具体的方法包括:谱聚类方法、深度学习方法等。
4、谱聚类方法是从图论中演化出来的算法,主要思想是把数据看作空间中的点,点之间可用边连接起来,距离较远代表点之间边权重低,反之则高;随后通过对所有数据点组成的图进行切分,让切分后的子图间边权重尽可能低,子图内的边权重尽可能高,从而完成聚类。但是,谱聚类方法依赖全图的拉普拉斯矩阵,此矩阵的计算和存储过于复杂,成本很高;对于特定的样本数量而言,拉普拉斯矩阵的计算和存储具有平方或超平方的复杂度,矩阵的分解甚至需要立方阶复杂度;另外,谱聚类方法并不完全适配无标签稀疏数据的特点:过度离散和零膨胀,导致聚类结果准确度不足。
5、面向无标签稀疏数据的深度学习方法多基于自动编码器,通过无监督学习的方式进行特征降维;其本质上会重复运行若干次自动编码器,将前一次的最终输出作为下一次运行的初始输入,然后再利用隐藏层特征进行聚类。但是,深度学习方法并未针对无标签稀疏数据分析中的聚类过程进行设计和优化,在高维度数据上的聚类性能劣于低维度数据。
6、综上可知,目前的无标签稀疏数据分析方法并不能解决因数据分布于不同机构和平台而无法安全整合的问题。
技术实现思路
1、为此,本申请提供一种基于联邦学习和深度学习的稀疏数据聚类方法及装置,以解决现有技术存在的因无标签稀疏数据分布于不同机构和平台而无法安全整合的问题。
2、为了实现上述目的,本申请提供如下技术方案:
3、第一方面,一种基于联邦学习和深度学习的稀疏数据聚类方法,包括多个参与方和横向联邦学习框架中的仲裁方,多个参与方和横向联邦学习框架中的仲裁方均各自持有一份无标签稀疏数据,无标签稀疏数据的数据特征相同,样本不同;
4、所述方法应用于参与方,包括:
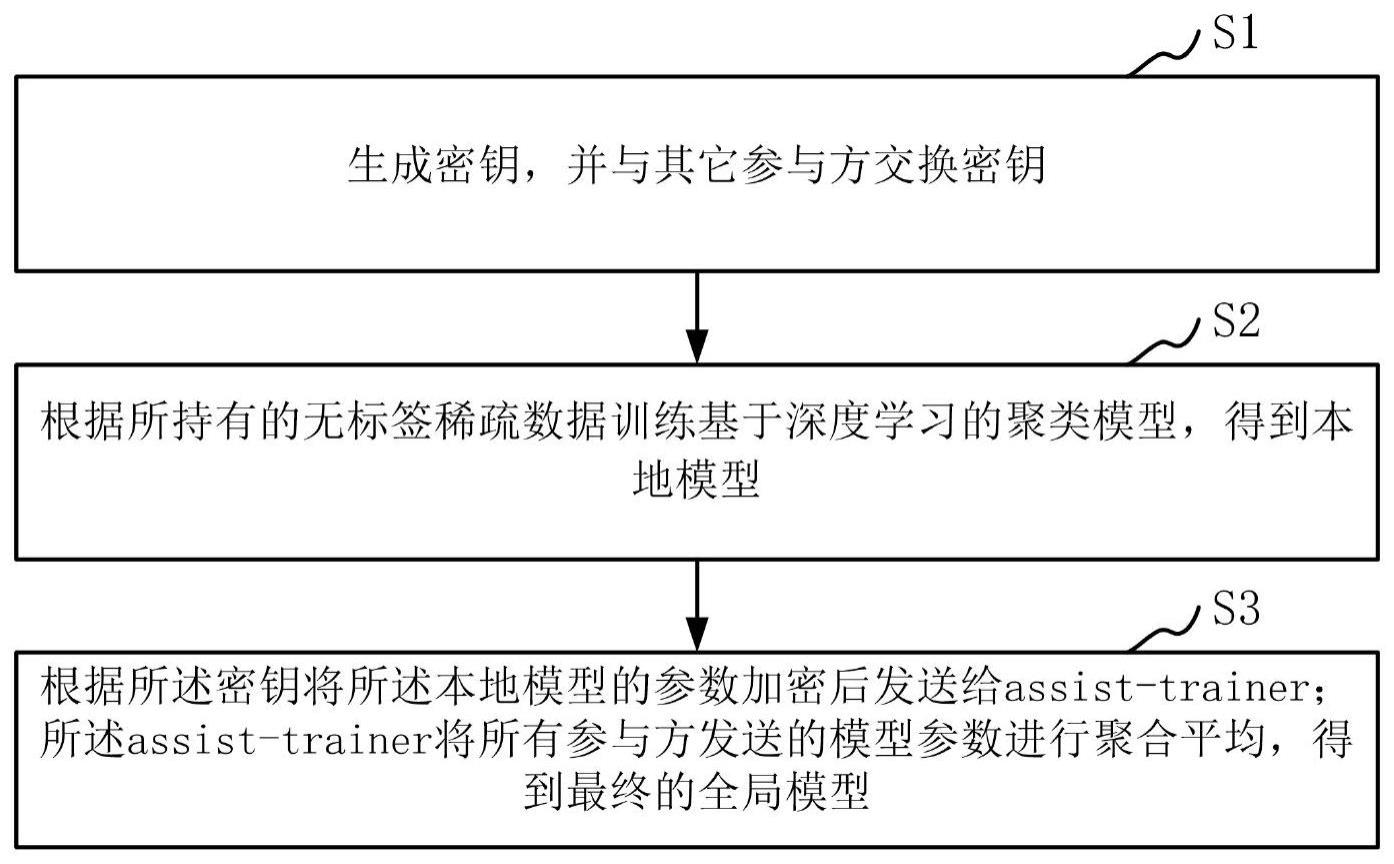
5、生成密钥,并与其它参与方交换密钥;
6、根据所持有的无标签稀疏数据训练基于深度学习的聚类模型,得到本地模型;
7、根据所述密钥将所述本地模型的参数加密后发送给assist-trainer;所述assist-trainer将所有参与方发送的模型参数进行聚合平均,得到最终的全局模型。
8、进一步的,所述本地模型的损失函数l为:
9、l=lzinb+γlc
10、其中,lzinb为自编码器的损失函数,lc为聚类的损失函数。
11、更进一步的,所述自编码器的损失函数lzinb为:
12、lzinb=-log(zinb(xcount|π,μ,θ))
13、其中,zinb(xcount|π,μ,θ)=πδ0(xcount)+(1-π)nb(xcount|μ,θ),
14、
15、xcount代表样本数,π、μ和θ为解码器最后一个隐藏层d后连接的三个全连接层。
16、更进一步的,所述聚类的损失函数lc为:
17、
18、其中,
19、进一步的,所述仲裁方能够利用含有标签的数据进行模型性能评估,并得到需要标签参与计算的聚类性能指标。
20、第二方面,一种基于联邦学习和深度学习的稀疏数据聚类装置,包括多个参与方和横向联邦学习框架中的仲裁方,多个参与方和横向联邦学习框架中的仲裁方均各自持有一份无标签稀疏数据,无标签稀疏数据的数据特征相同,样本不同;
21、所述装置用于实现实现参与方的执行步骤,包括:
22、密钥生成模块,用于生成密钥;
23、密钥交换模块,用于与其它参与方交换密钥;
24、本地模型训练模块,用于根据所持有的无标签稀疏数据训练基于深度学习的聚类模型,得到本地模型;
25、加密模块,用于根据所述密钥将所述本地模型的参数加密后发送给assist-trainer;所述assist-trainer将所有参与方发送的模型参数进行聚合平均,得到最终的全局模型。
26、第三方面,一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现基于联邦学习和深度学习的稀疏数据聚类方法的步骤。
27、第四方面,一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现基于联邦学习和深度学习的稀疏数据聚类方法的步骤。
28、相比现有技术,本申请至少具有以下有益效果:
29、本申请提供了一种基于联邦学习和深度学习的稀疏数据聚类方法,包括多个参与方和横向联邦学习框架中的仲裁方,多个参与方和横向联邦学习框架中的仲裁方均各自持有一份无标签稀疏数据,无标签稀疏数据的数据特征相同,样本不同;方法应用于参与方,包括:生成密钥,并与其它参与方交换密钥;根据所持有的无标签稀疏数据训练基于深度学习的聚类模型,得到本地模型;根据密钥将本地模型的参数加密后发送给assist-trainer;assist-trainer将所有参与方发送的模型参数进行聚合平均,得到最终的全局模型。本申请将基于深度学习的无标签稀疏数据聚类方法集成在联邦学习框架上,在不公开明文数据的前提下,可以安全整合存储于不同机构和平台的无标签稀疏数据,极大地扩充样本量,提升了模型精度。
技术特征:
1.一种基于联邦学习和深度学习的稀疏数据聚类方法,其特征在于,包括多个参与方和横向联邦学习框架中的仲裁方,多个参与方和横向联邦学习框架中的仲裁方均各自持有一份无标签稀疏数据,无标签稀疏数据的数据特征相同,样本不同;
2.根据权利要求1所述的基于联邦学习和深度学习的稀疏数据聚类方法,其特征在于,所述本地模型的损失函数l为:
3.根据权利要求2所述的基于联邦学习和深度学习的稀疏数据聚类方法,其特征在于,所述自编码器的损失函数lzinb为:
4.根据权利要求2所述的基于联邦学习和深度学习的稀疏数据聚类方法,其特征在于,所述聚类的损失函数lc为:
5.根据权利要求1所述的基于联邦学习和深度学习的稀疏数据聚类方法,其特征在于,所述仲裁方能够利用含有标签的数据进行模型性能评估,并得到需要标签参与计算的聚类性能指标。
6.一种基于联邦学习和深度学习的稀疏数据聚类装置,其特征在于,包括多个参与方和横向联邦学习框架中的仲裁方,多个参与方和横向联邦学习框架中的仲裁方均各自持有一份无标签稀疏数据,无标签稀疏数据的数据特征相同,样本不同;
7.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1至5中任一项所述的方法的步骤。
8.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至5中任一项所述的方法的步骤。
技术总结
本申请公开了一种基于联邦学习和深度学习的稀疏数据聚类方法,包括多个参与方和横向联邦学习框架中的仲裁方,多个参与方和横向联邦学习框架中的仲裁方均各自持有一份无标签稀疏数据,无标签稀疏数据的数据特征相同,样本不同;方法应用于参与方,包括:生成密钥,并与其它参与方交换密钥;根据所持有的无标签稀疏数据训练基于深度学习的聚类模型,得到本地模型;根据密钥将本地模型的参数加密后发送给assist‑trainer;assist‑trainer将所有参与方发送的模型参数进行聚合平均,得到最终的全局模型。本申请在不公开明文数据的前提下,可以安全整合存储于不同机构和平台的无标签稀疏数据,极大地扩充样本量,提升了模型精度。
技术研发人员:李修明
受保护的技术使用者:翼健(上海)信息科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!