本发明涉及人工智能,尤其涉及一种基于领域知识图谱的方面级情感分析方法及系统。
背景技术:
1、情感分析是自然语言处理(nlp)领域内的一个重要研究方向,着重于提取和分析文本数据中表达的情感。基于方面级的情感分析(absa)是情感分析的一个子任务,它提供了对特定项目或类别的情感更详细的分析。这种洞察力可以被企业利用来识别产品的优劣之处,并揭示产生积极或消极情感的意外方面。absa可以分为两个变体:方面类别情感分类(acsc)和方面目标情感分类(atsc)。acsc专注于确定对更广泛的类别或方面的总体情感,而atsc旨在确定对更具体的目标或实体的情感。通过使用absa,企业可以更全面地了解客户对其产品或服务的意见和态度,这可以为产品开发、市场营销策略和客户服务计划提供信息支持。
2、近年来,自然语言处理领域出现了一个重要的转变,即向预训练语言模型(plms)的方向转移,这些模型依赖于其卓越的性能作为许多下游任务的基础,研究人员进行了广泛的研究,以深入了解plm效果的原理,plm在预训练过程中获得了丰富的知识。因此,如何激发和利用这些知识引起了越来越多的关注。微调(fine-tuning)是一种传统的方法,用于实现这一目标,其中在plms的顶部添加额外的分类器,并根据分类目标进一步训练模型。微调通过监督学习策略取得了令人满意的结果。然而,将微调应用于少样本学习和零样本学习情境仍然是一个具有挑战性的任务,因为额外的分类器需要足够数量的标记训练数据进行调整。
3、近期的研究表明,提示学习(prompt learning)可以用来连接预训练目标和下游任务,提高预训练语言模型在少样本和零样本任务上的性能。例如,使用gpt-3和lama进行模型调整的研究表明,使用离散或连续prompt可以提高plms在这些任务上的性能。词汇表和标签空间之间的这种联系对分类性能有重大影响。
4、传统的提示学习方法的每个模板都采用手动的标签词到语言化模块的一对一映射。然而,手动的词汇化器通常受限于有限的信息,难以基于有限的信息做出准确的预测。这种一对一映射限制了标签词的覆盖范围,因此缺乏足够的信息来做出准确的预测,这可能会引入词汇化器的偏见。此外,在absa任务中,人们在评估不同方面时往往使用更具体和有针对性的形容词,例如在评估食物时使用"美味的"而不是"好的",而这类标签词的语义在预测中的重要性是现有提示学习方法无法解决的。
技术实现思路
1、为了解决上述技术问题,本发明旨在提供一种通过整合外部知识图来增强absa任务中提示性能的新思路,通过使用词网提取和小规模数据注释的组合构建了一个有效的领域知识图,由此产生的语言化模块s提供了更丰富、更具体的标签词映射,有助于提高absa任务的准确性。
2、为了实现上述技术目的,本发明提供的技术方案包括:
3、基于领域知识图谱的方面级情感分析方法,包括以下步骤:
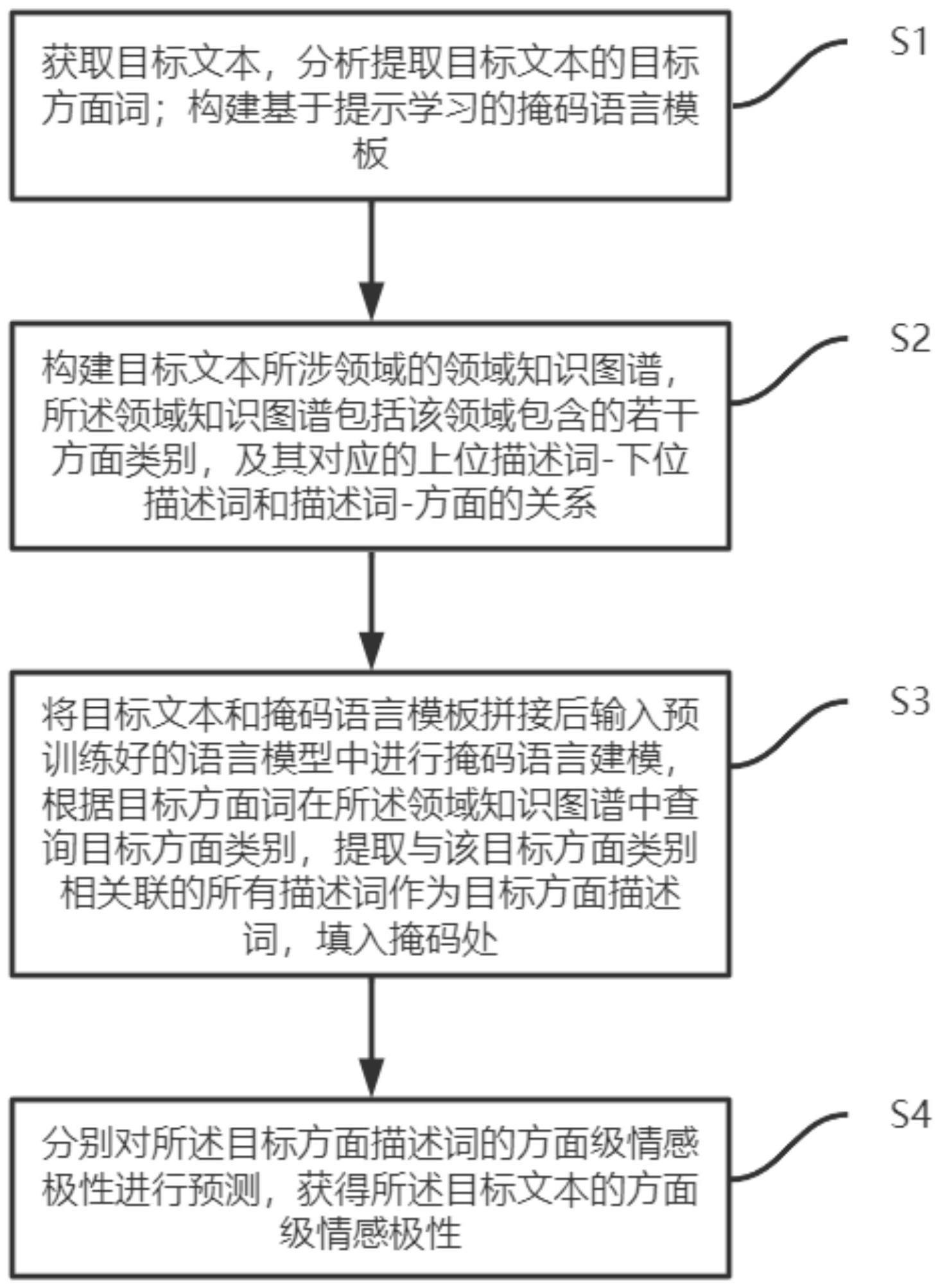
4、获取目标文本,分析提取目标文本的目标方面词;构建基于提示学习的掩码语言模板;
5、构建目标文本所涉领域的领域知识图谱,所述领域知识图谱包括该领域包含的若干方面类别,及其对应的上位描述词-下位描述词和描述词-方面的关系;
6、将目标文本和掩码语言模板拼接后输入预训练好的语言模型中进行掩码语言建模,根据目标方面词在所述领域知识图谱中查询目标方面类别,提取与该目标方面类别相关联的所有描述词作为目标方面描述词,填入掩码处;
7、分别对所述目标方面描述词的方面级情感极性进行预测,获得所述目标文本的方面级情感极性。
8、在一些较优的实施例中,所述构建目标文本所涉领域的领域知识图谱的方法包括:
9、获取与目标文本所涉领域相同的若干评价文本,提取所述评价文本中所包含的方面词和各方面的描述词,建立方面-描述词列表;
10、基于方面-描述词列表,在词网数据库中提取方面类别及其对应的描述词-描述词和描述词-方面的关系,构建领域知识图谱。
11、在一些较优的实施例中,其特征在于,获得所述目标文本的方面级情感极性的方法包括:
12、将预测分数最高的目标方面描述词所映射的方面级情感极性,作为目标文本的方面级情感极性。
13、在一些较优的实施例中,获得所述目标文本的方面级情感极性的方法包括:
14、对所有目标方面描述词的预测分数按方面级情感极性类别进行加权平均,将加权平均值最高的方面级情感极性作为目标文本的方面级情感极性。
15、在一些较优的实施例中,所述语言模型包括bert模型或gpt模型。
16、在一些较优的实施例中,所述词网数据库包括wordnet词库和/或chinesewordnet词库。
17、本发明还提供了基于领域知识图谱的方面级情感分析系统,包括:
18、第一获取模块,设置为用于获取目标文本,分析提取目标文本的目标方面词;
19、领域知识图谱模块,设置为内置有包含目标文本所涉领域的若干方面类别,及其对应的上位描述词-下位描述词和描述词-方面的关系的领域知识图谱;
20、掩码语言模板模块,设置为内置有基于提示学习的掩码语言模板,将目标文本和掩码语言模板拼接后作为第一输出文本;
21、预训练语言模型,设置为内置有预训练好的语言模型,输入第一输出文本进行掩码语言建模,根据目标方面词在所述领域知识图谱中查询目标方面类别,提取与该目标方面类别相关联的所有描述词作为目标方面描述词,填入掩码处;
22、预测分析模块,设置为分别对所述目标方面描述词的方面级情感极性进行预测,获得所述目标文本的方面级情感极性。
23、在一些较优的实施例中,所述领域知识图谱的构建方法包括:
24、获取与目标文本所涉领域相同的若干评价文本,提取所述评价文本中所包含的方面词和各方面的描述词,建立方面-描述词列表;
25、基于方面-描述词列表,在词网数据库中提取方面类别及其对应的描述词-描述词和描述词-方面的关系,构建领域知识图谱。
26、在一些较优的实施例中,所述预测分析模块包括第一预测分析单元,设置为将预测分数最高的目标方面描述词所映射的方面级情感极性作为目标文本的方面级情感极性。
27、在一些较优的实施例中,所述预测分析模块包括第二预测分析单元,设置为对所有目标方面描述词的预测分数按方面级情感极性类别进行加权平均,将加权平均值最高的方面级情感极性作为目标文本的方面级情感极性。
28、有益效果
29、利用针对性较强的所涉领域的领域知识图谱获取全面的描述词和实体关系,在零样本或少样本的情况下,针对atsc和acsc任务均能保持较高的预测准确性,避免了手动录入提示语可能存在的偏差、限制标签词的覆盖范围的问题。
技术特征:1.基于领域知识图谱的方面级情感分析方法,其特征在于,包括以下步骤:
2.如权利要求1所述的基于领域知识图谱的方面级情感分析方法,其特征在于,所述构建目标文本所涉领域的领域知识图谱的方法包括:
3.如权利要求1或2所述的基于领域知识图谱的方面级情感分析方法,其特征在于,获得所述目标文本的方面级情感极性的方法包括:
4.如权利要求1或2所述的基于领域知识图谱的方面级情感分析方法,其特征在于,获得所述目标文本的方面级情感极性的方法包括:
5.如权利要求1或2所述的基于领域知识图谱的方面级情感分析方法,其特征在于,所述语言模型包括bert模型或gpt模型。
6.如权利要求2所述的基于领域知识图谱的方面级情感分析方法,其特征在于,所述词网数据库包括wordnet词库和/或chinese wordnet词库。
7.基于领域知识图谱的方面级情感分析系统,其特征在于,包括:
8.如权利要求7所述的领域知识图谱的方面级情感分析系统,其特征在于,所述领域知识图谱的构建方法包括:
9.如权利要求7或8所述的领域知识图谱的方面级情感分析系统,其特征在于,所述预测分析模块包括第一预测分析单元,设置为将预测分数最高的目标方面描述词所映射的方面级情感极性作为目标文本的方面级情感极性。
10.如权利要求7或8所述的领域知识图谱的方面级情感分析系统,其特征在于,所述预测分析模块包括第二预测分析单元,设置为对所有目标方面描述词的预测分数按方面级情感极性类别进行加权平均,将加权平均值最高的方面级情感极性作为目标文本的方面级情感极性。
技术总结本发明提供了基于领域知识图谱的方面级情感分析方法及系统,方法包括:获取目标文本,分析提取目标方面词;构建基于提示学习的掩码语言模板;构建目标文本所涉领域的领域知识图谱;将目标文本和掩码语言模板拼接后输入预训练好的语言模型中进行掩码语言建模,根据目标方面词在领域知识图谱中查询目标方面类别,提取与该目标方面类别相关联的所有描述词作为目标方面描述词填入掩码处;分别对目标方面描述词的方面级情感极性进行预测,获得目标文本的方面级情感极性。本发明在零样本或少样本的情况下,针对ATSC和ACSC任务均能保持较高的预测准确性,避免手动录入提示语存在的偏差、限制标签词的覆盖范围的问题。
技术研发人员:熊熙,王江河
受保护的技术使用者:成都图奕科技有限公司
技术研发日:技术公布日:2024/1/16