一种基于逆强化学习自动调整奖励的文本摘要系统
:本发明涉及人工智能自然源处理领域,尤其涉及一种基于逆强化学习自动调整奖励的文本摘要系统。
背景技术
0、
背景技术:
1、文本摘要(text summarization)旨在将源文档压缩成一个更加简短的摘要,并且在压缩的同时保留其主要思想。根据输出的不同,传统的摘要系统可以分为抽取式摘要和生成式摘要。虽然抽取式摘要系统能够直接从原始文档中获得内容使得获得输出结果更加的便利,但由于生成式摘要系统能够从更大的词表上一个一个的生成单词从而具有更大的灵活性和研究空间,所以生成式系统受到越来越欢迎。
2、大多数生成式摘要系统使用最大似然估计(mle)进行训练,同时最小化负对数似然(nll)损失。具体而言,生成式摘要可以看作是一种带有条件的语言模型生成任务,给定一个源文档x={x1,x2,...,xn},摘要模型训练的目的是一个学习一个条件概率模型pθ(y|x)来生成摘要y=(y1,y2,...,ym),其中yi是从一个大小为v的词表上获得的单词,θ表示的是摘要模型的训练参数。pθ(y|x)可以根据前面所生成的词进一步的分解为每个词的条件概率的乘积:
3、
4、通常情况下,θ的训练是通过最大似然估计来进行训练。然而,先前的研究表明,用mle训练的模型有以下缺点:(1)训练目标不匹配,其中最小化负对数似然损失集中在词级别的匹配上,缺乏对生成的整体结果的考量,比如同义不同形式的问题。(2)暴露偏差(exposure bias),这是训练模型的一个常见问题,因为在训练的时候会假设在训练过程的每一步都可以获得目标输出,而在测试的时候目标输出是无法获得的,从而导致了训练和测试的不一致问题。
5、现有的摘要模型中结合强化学习的相关研究集中在提出相关的奖励函数,比如直接使用和语义相关的评价指标--bertscore来作为奖励函数,从而增强最终模型的生成效果。另外也有相关研究考虑原始文档和生成摘要之间的蕴含关系作为奖励函数来提升摘要模型的效果。
6、由于不同的奖励函数作为最终的奖励函数的一部分,需要给定不同的权重。这个权重作为预先设定的部分,通常需要研究人员根据经验来进行指定,因此具有很强的不确定性导致最终结果出现较大的方差。不同研究的分析局限在针对自己提出的奖励函数所针对的领域的效果,往往忽略了整体上的效果以及摘要模型所希望解决的最终的问题。
7、通常情况下,强化学习的奖励会被定义为评价指标,因为强化学习的训练目标就是最大化奖励函数。使用评价指标作为奖励会导致模型过分的强调对指标的优化,从而弱化其他方面的考量,比如流利度,信息包含比例等重要指标。目前将强化学习结合到摘要模型中的相关研究中,也包含有针对不同方向的优化,但是其主要的出发点依旧是局限在提出相关的奖励函数。
技术实现思路
0、
技术实现要素:
1、为了解决这个问题,本发明提供一种基于逆强化学习自动调整奖励的文本摘要系统,本发明通过逆强化学习训练生成式摘要模型,并且对不同的奖励组件动态的调整对应的权重从而适应不同的数据集,
2、本发明采用技术方案为:
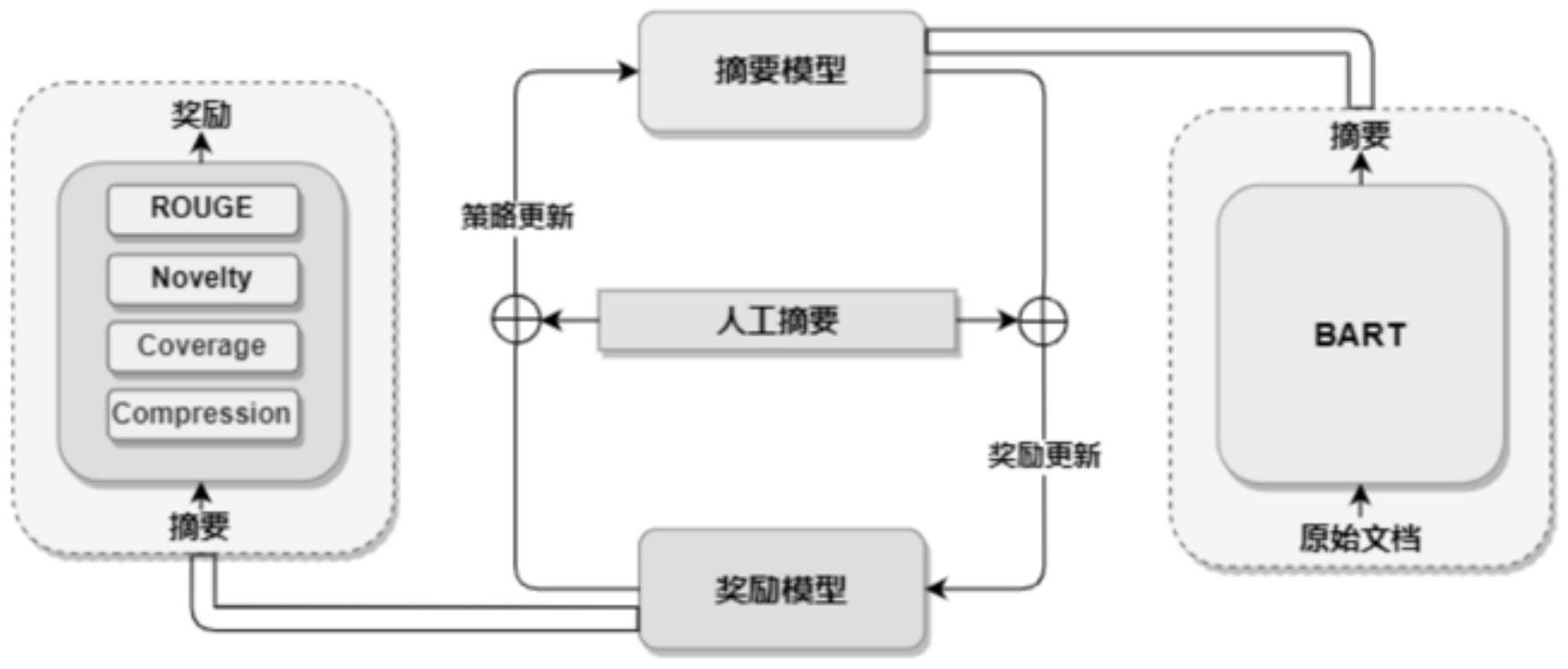
3、一种基于逆强化学习自动调整奖励的文本摘要系统,所述系统包括摘要模型、奖励模块、策略模块和人工摘要模型,
4、所述摘要模型提取原始文档数据采用逆强化算法生成文本摘要函数y;
5、所述奖励模块对文本摘要函数更新不同奖励的权重;
6、所述策略模块采用如下公式对文本摘要函数进行混合奖励函数的训练;
7、
8、其中:r(ys)表示获得的奖励;m'表示生成摘要的长度;表示生成摘要中第t-1个单词;
9、所述人工摘要模块通过评价指标对训练后文本摘要函数进行最终奖励输出最优文本摘要模型。
10、进一步,所述奖励模块对文本摘要函数更新不同奖励的权重过程:
11、设置不同的奖励组件建立训练权重,所述奖励组件表示为c={c1,c2,c3,c4},分别对应人工摘要模型的评价指标--新颖性,覆盖率和压缩率;
12、对于不同的奖励组件,结合与不同的权重建立最终的奖励可以表示为:
13、rφ(y)=φtc
14、其中::c是上面定义的奖励组件;φ={φ1,φ2,φ3,φ4}是对应的奖励组件的权重参数;
15、通过如下公式对文本摘要函数更新不同奖励的权重从而最大化人工摘要的概率
16、
17、其中:φ是上面定义的奖励组件的权重参数;n是生成摘要的数量;yn是第n个生成摘要;pφ(yn)表示生成摘要yn的概率;
18、通过如下公式对文本摘要函数的奖励中每个组件的权重更新:
19、
20、其中:φj是第j个奖励组件对应的权重参数;y~pdata表示从数据集中采样得到人工摘要;y~pφ(y)表示从文本摘要生成函数的生成结果中进行采样得到生成摘要。
21、有益效果
22、本发明首次将逆强化学习应用到文本摘要领域,并且对不同的奖励组件动态的调整对应的权重从而适应不同的数据集。在公共的数据集上的实验结果表明,逆强化学习得到的模型相较于最大似然估计和强化学习训练得到的模型有较为明显;且由于逆强化学习训练的特性,其得到的结果具有更强的可解释性。
23、通过逆强化学习训练我们在文本摘要的rouge评价指标上获得了最优效果,在各个奖励组件的权重更新上也体现出来对应的训练数据集的特征。相较于对比的最大似然估计和强化学习训练的模型生成结果,逆强化学习训练的模型在生成摘要上和数据集中给定的人工摘要具有最高的相似度,并且生成摘要中存在的与原始文档不一致的情况最少。
技术特征:
1.一种基于逆强化学习自动调整奖励的文本摘要系统,所述系统包括摘要模型、奖励模块、策略模块和人工摘要模型,其特征在于:
2.根据权利要求1所述的一种基于逆强化学习自动调整奖励的文本摘要系统,其特征在于:所述奖励模块对文本摘要函数更新不同奖励的权重过程:
技术总结
本发明公开了一种基于逆强化学习自动调整奖励的文本摘要系统,所述系统包括摘要模型、奖励模块、策略模块和人工摘要模型,所述摘要模型提取原始文档数据采用逆强化算法生成文本摘要函数Y;所述奖励模块对文本摘要函数更新不同奖励的权重;所述策略模块采用如下公式对文本摘要函数进行混合奖励函数的训练;所述人工摘要模块通过评价指标对训练后文本摘要函数进行最终奖励输出最优文本摘要模型;本发明将逆强化学习训练文本摘要领域,克服现有技术中训练目标不匹配、暴露偏差的技术问题,提高人工智能生成文本摘要的精准性。
技术研发人员:付宇,熊德意,贺瑞芳,孟庆霖
受保护的技术使用者:天津大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!