模型训练方法、航线规划方法及相关装置
本申请涉及机器学习领域,具体而言,涉及一种模型训练方法、航线规划方法及相关装置。
背景技术:
1、北极地区呈现出的航路开发潜力引起了全球关注,在此背景下,开展北极航路规划前瞻性研究,尽早建立实时的北极冰区航路智能规划系统,具有非常重要的应用价值。但遥远而恶劣的北极环境仍然给冰区航线规划带来巨大的挑战,如冰山,浮冰和暴风雪,其中,海冰是影响航线的关键因素,但是海冰分布年际变化大,没有规律可循,导致航运路线的选择具有不确定性。
2、由于强化学习是智能体以“试错”的方式进行自主学习,通过与环境不断交互获得奖赏指导行为,目标是通过不断学习最优策略做出决策,以期获得最大回报。因此,相关技术中提出了通过强化学习的方式生成用于制定航线的航线规划模型。但研究发现,随着航线规划复杂性的增加,环境的状态空间和动作空间的规模也随之大大增加,导致使用传统强化学习方法在于环境交互过程中存在探索效率欠佳的问题。
技术实现思路
1、为了克服现有技术中的至少一个不足,本申请提供一种模型训练方法、航线规划方法及相关装置,用于在训练强化学习模型制定航行路线的过程中,提高对环境的探索效率。具体包括:
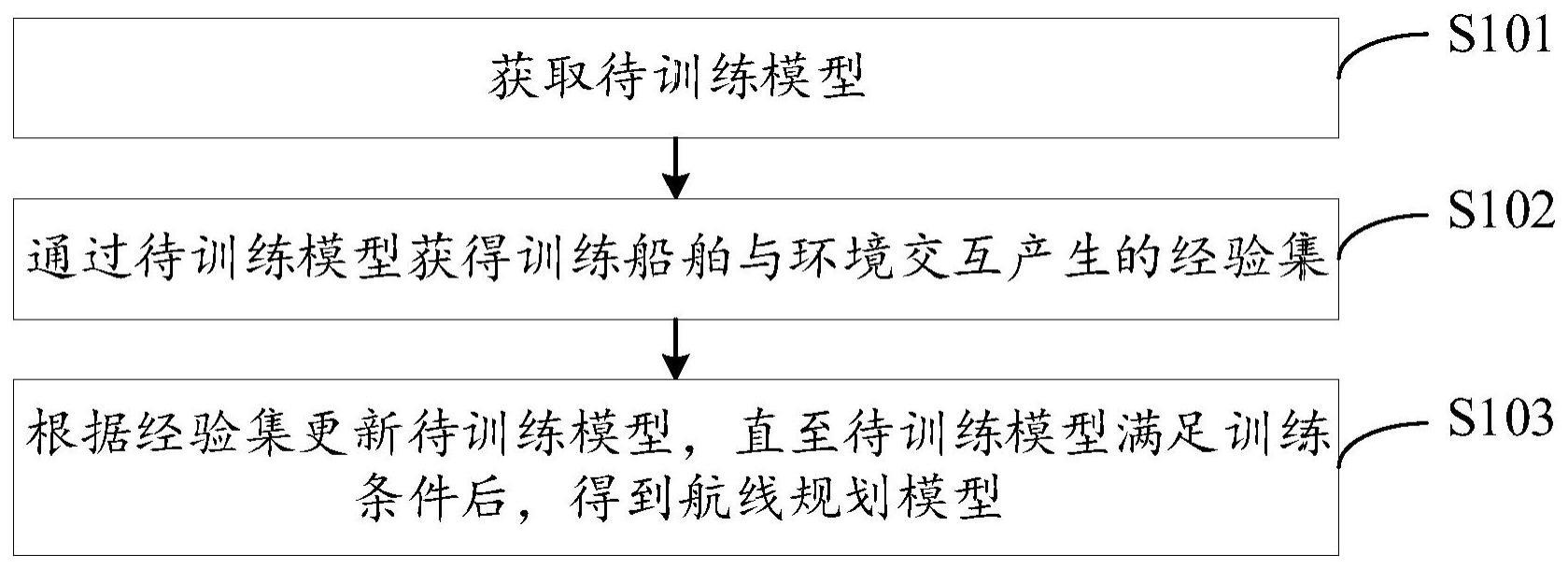
2、第一方面,本申请提供一种模型训练方法,所述方法包括:
3、获取待训练模型,其中,所述待训练模型为强化学习模型;
4、通过所述待训练模型获得训练船舶与环境交互产生的经验集,其中,所述经验集中的每条历史经验,包括所述训练船舶执行所述待训练模型生成的航行动作所获得的即时奖励以及新的航行状态;所述即时奖励包括内部即时奖励,所述内部即时奖励与所述新的航行状态的新颖性成正相关,所述新颖性表征所述新的航行状态与常规航行状态之间的差异;
5、根据所述经验集更新所述待训练模型,直至所述待训练模型满足训练条件后,得到航线规划模型。
6、第二方面,本申请提供一种航线规划方法,所述方法包括:
7、确定目标船舶、该目标船舶的起点以及终点;
8、通过所述的模型训练方法所训练的航线规划模型为所述目标船舶规划从所述起点到终点的航行路线。
9、第三方面,本申请提供一种模型训练装置,所述装置包括:
10、经验生成模块,用于获取待训练模型,其中,所述待训练模型为强化学习模型;
11、所述经验生成模块,还用于通过所述待训练模型获得训练船舶与环境交互产生的经验集,其中,所述经验集中的每条历史经验,包括所述训练船舶执行所述待训练模型生成的航行动作所获得的即时奖励以及新的航行状态;所述即时奖励包括内部即时奖励,所述内部即时奖励与所述新的航行状态的新颖性成正相关,所述新颖性表征所述新的航行状态与常规航行状态之间的差异;
12、模型更新模块,用于根据所述经验集更新所述待训练模型,直至所述待训练模型满足训练条件后,得到航线规划模型。
13、第四方面,本申请提供一种存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时,实现所述的模型训练方法或者所述的航线规划方法。
14、第五方面,本申请提供一种电子设备,所述电子设备包括处理器以及存储器,所述存储器存储有计算机程序,所述计算机程序被处理器执行时,实现所述的模型训练方法或者所述的航线规划方法。
15、相对于现有技术而言,本申请具有以下有益效果:
16、本实施例提供的模型训练方法、航线规划方法及相关装置中,获取基于强化学习的待训练模型;通过待训练模型获得训练船舶与环境交互产生的经验集;根据经验集更新待训练模型,直至待训练模型满足训练条件后,得到航线规划模型。该经验集中的每条历史经验,包括训练船舶执行待训练模型生成的航行动作所获得的即时奖励以及新的航行状态;由于该即时奖励包括与新的航行状态的新颖性成正相关的内部即时奖励,而该新颖性表征新的航行状态与常规航行状态之间的差异,因此,在训练强化学习模型制定航行路线的过程中,能够提高对环境的探索效率。
技术特征:
1.一种模型训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的模型训练方法,其特征在于,所述即时奖励还包括所述训练船舶的外部即时奖励,所述通过所述待训练模型获得训练船舶与环境交互产生的经验集,包括:
3.根据权利要求2所述的模型训练方法,其特征在于,所述根据所述训练船舶执行所述航行动作后新的航行状态与所述常规航行状态之间的差异,获得所述内部即时奖励,包括:
4.根据权利要求3所述的模型训练方法,其特征在于,所述根据所述新的航行状态与所述常规航行状态之间的差异,得到所述内部即时奖励,包括:
5.根据权利要求3所述的模型训练方法,其特征在于,所述根据所述内部即时奖励与所述外部即时奖励,获得所述训练船舶执行所述航行动作后的即时奖励,包括:
6.根据权利要求5所述的模型训练方法,其特征在于,所述获取所述内部即时奖励在当前训练周期的权重,包括:
7.一种航线规划方法,其特征在于,所述方法包括:
8.一种模型训练装置,其特征在于,所述装置包括:
9.一种存储介质,其特征在于,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时,实现权利要求1-6任意一项所述的模型训练方法或者权利要求7所述的航线规划方法。
10.一种电子设备,其特征在于,所述电子设备包括处理器以及存储器,所述存储器存储有计算机程序,所述计算机程序被处理器执行时,实现权利要求1-6任意一项所述的模型训练方法或者权利要求7所述的航线规划方法。
技术总结
本申请提供一种模型训练方法、航线规划方法及相关装置,涉及机器学习领域。其中,获取基于强化学习的待训练模型;通过待训练模型获得训练船舶与环境交互产生的经验集;根据经验集更新待训练模型,直至待训练模型满足训练条件后,得到航线规划模型。该经验集中的每条历史经验,包括训练船舶执行待训练模型生成的航行动作所获得的即时奖励以及新的航行状态;由于该即时奖励包括与新的航行状态的新颖性成正相关的内部即时奖励,而该新颖性表征新的航行状态与常规航行状态之间的差异,因此,在训练强化学习模型制定航行路线的过程中,能够提高对环境的探索效率。
技术研发人员:吴阿丹,车涛
受保护的技术使用者:中国科学院西北生态环境资源研究院
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!