本发明涉及机器人,具体来说,涉及一种佩戴安全帽的检测方法、装置及机器人。
背景技术:
1、安全帽作为保护工地工作人员的重要措施,在工地等需要工作人员佩戴安全帽的场景,一般强制要求工作人员配置安全帽,但目前存在不带安全帽的清晰,因此需要及时发现没有戴安全帽的人,并给出报警。
2、现有的检测是否佩戴安全帽的技术方案主要有以下两种:
3、(1)、联合使用深度学习目标检测网络和深度学习分类网络判断是否佩戴安全帽:该方案首先从固定摄像头获取原始图像,然后对原始图像进行预处理操作(放缩到特定尺度后减均值除方差),然后把预处理过的图像输入目标检测网络检测人头,检测到人头后再把人头图像输入进分类网络分成戴安全帽的人头和不戴安全帽的人头。
4、(2)、联合使用深度学习关键点检测网络和深度学习目标检测网络判断是否佩戴安全帽:该方案首先从固定摄像头获取图像,然后对原始图像进行预处理操作(放缩到特定尺度后减均值除方差),然后把预处理过的图像同时输入关键点检测网络和目标检测网络。由目标检测网络输出人头位置,而关键点检测网络输出安全帽位置,如果关键点在人头上则说明戴了安全帽,否则视为未戴安全帽。
5、在工地等场景下,摄像头通常安装在较高的位置,其距离工作人员较远,这就导致拍摄的画面中的人头、安全帽通常较小。在此场景下,如果先检测人头再把人头分类成为戴安全帽的人头和不戴安全帽的人头,会带来人头漏检和人头分类错误的问题;如果是同时用关键点网络定位安全帽和用目标检测网络检测人头,会带来关键点定位错误和人头漏检的问题。
6、本文提供的背景描述用于总体上呈现本公开的上下文的目的。除非本文另外指示,在该章节中描述的资料不是该申请的权利要求的现有技术并且不要通过包括在该章节内来承认其成为现有技术。
技术实现思路
1、针对相关技术中的上述技术问题,本发明提出了一种佩戴安全帽检测方法,其包括如下步骤:
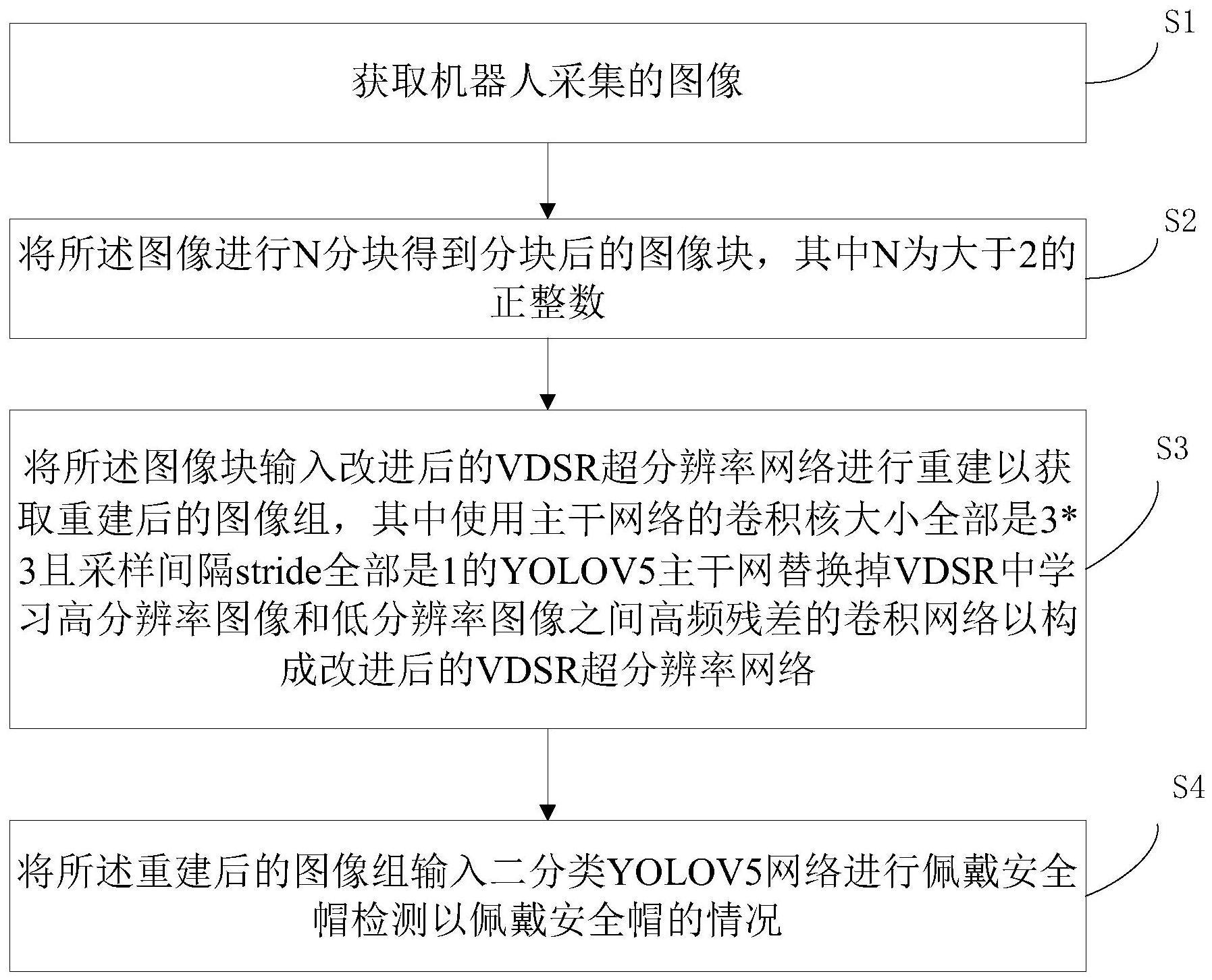
2、s1,获取机器人采集的图像;
3、s2,将所述图像进行n分块得到分块后的图像块,其中n为大于2的正整数;
4、s3,将所述图像块输入改进后的vdsr超分辨率网络进行重建以获取重建后的图像组,其中使用主干网络的卷积核大小全部是3*3且采样间隔stride全部是1的yolov5主干网替换掉vdsr中学习高分辨率图像和低分辨率图像之间高频残差的卷积网络以构成改进后的vdsr超分辨率网络;
5、s4,将所述重建后的图像组输入二分类yolov5网络进行佩戴安全帽检测以佩戴安全帽的情况。
6、具体的,所述步骤s2具体为:将所述图像进行下采样得到下采样图像,并对所述下采样图像进行n分块得到分块后的图像块。
7、具体的,所述步骤s2还包括:对所述分块后的图像块进行上采样以获取第一分块图像组。
8、具体的,还包括还步骤s5,根据所述重建后的图像组检测到的目标框进行去重。
9、具体的,所述步骤s5具体为:
10、s51,对检测到的所有目标框的坐标都乘以0.5,以获取第二目标框坐标;
11、s52,将所述第一图像块、第二图像块、第三图像块、第四图像块获取的目标框分别进行坐标修改;
12、s53、遍历第五图像块的所有目标框,对每一个目标框执行以下操作:依次计算该目标框和第一图像块所有目标框、第二图像块所有目标框、第三图像块所有目标框、第四图像块所有目标框的面积差绝对值和相交面积,如果面积差绝对值小于该目标面积的第一预设倍数且相交面积大于该目标面积的第二预设倍数,则留下该框,否则删除;第一图像块所有目标框、第二图像块所有目标框、第三图像块所有目标框、第四图像块所有目标框以及第五图像块剩下的目标框即为最终检测到的目标框。
13、第二方面,本发明的另一个实施例公开了一种佩戴安全帽检测装置,其包括如下单元:
14、图像获取单元,用于获取机器人采集的图像;
15、图像分块单元,用于将所述图像进行n分块得到分块后的图像块,其中n为大于2的正整数;
16、超分辨率重建单元,用于将所述图像块输入改进后的vdsr超分辨率网络进行重建以获取重建后的图像组,其中使用主干网络的卷积核大小全部是3*3且采样间隔stride全部是1的yolov5主干网替换掉vdsr中学习高分辨率图像和低分辨率图像之间高频残差的卷积网络以构成改进后的vdsr超分辨率网络;
17、佩戴安全帽检测单元,用于将所述重建后的图像组输入二分类yolov5网络进行佩戴安全帽检测以佩戴安全帽的情况。
18、具体的,所述图像分块单元具体为:将所述图像进行下采样得到下采样图像,并对所述下采样图像进行n分块得到分块后的图像块。
19、具体的,所述图像分块单元还包括:对所述分块后的图像块进行上采样以获取第一分块图像组。
20、具体的,还包括目标框去重单元,用于根据所述重建后的图像组检测到的目标框进行去重。
21、第三方面,本发明的另一个实施例公开了一种机器人,所述机器人包括:一处理模块,一底盘,一存储模块,一激光雷达,一摄像头,所述存储模块存储有指令,在所述指令被执行时,用于实现上述的佩戴安全帽检测方法。
22、第四方面,本发明的另一个实施例提供了一种非易失性存储器,所述存储器上存储有指令,所述指令被处理器执行时,用于实现上述的佩戴安全帽检测方法。
23、本发明把图像分成5小块后再把这些小块全部上采样到目标检测推理所需的图像尺寸,然后再把上采样后的5个图像一次性输入改进的vdsr进行超分辨率重建,重建完成后再把5个重建后的图像一次性输入目标检测网络。图像分块后再上采样,就会把小目标放大,而对上采样后的图像进行超分辨率重建则消除了上采样后图像产生的锯齿和模糊,所以本发明保证了小目标检测的精度。由于卷积神经网络的特性,一次推理多张图像和一次推理一张图像相比,速度非但不变慢甚至还会增加,因此,相比那些使用一个目标检测网络、一个分类网络或者使用一个关键点检测网络、一个目标检测网络来判断是否佩戴安全帽的方案,本发明其实既保证了精度又保证了速度。
24、本发明的一种佩戴安全帽的检测方法,通过在机器人头顶部携带单个普通的、价格低廉的可360度旋转的摄像头的对工地等场景按照固定路线巡检,并对机器人获取的图像使用改进的vdsr超分辨率网络把模糊的、有锯齿的图像重建成清晰的图像后再用两分类yolov5检测图像中的佩戴安全帽情况。本实施例的把yolov5主干网中的卷积核大小全部改为3*3且stride全部改为1(改造后yolov5主干网输入图像的尺寸和输出feature map的尺寸相同),然后再把改造后的yolov5主干网替换掉vdsr中学习高分辨率图像和低分辨率图像之间高频残差的卷积网络。进一步的,本发明使用两分类yolov5判断工地等场景工作人员是否佩戴安全帽。
技术特征:1.一种佩戴安全帽检测方法,其包括如下步骤:
2.根据权利要求1所述的方法,所述步骤s2具体为:将所述图像进行下采样得到下采样图像,并对所述下采样图像进行n分块得到分块后的图像块。
3.根据权利要求2所述的方法,所述步骤s2还包括:对所述分块后的图像块进行上采样以获取第一分块图像组。
4.根据权利要求3所述的方法,还包括还步骤s5,根据所述重建后的图像组检测到的目标框进行去重。
5.根据权利要求4所述的方法,所述步骤s5具体为:
6.一种佩戴安全帽检测装置,其包括如下单元:
7.根据权利要求6所述的装置,所述图像分块单元具体为:将所述图像进行下采样得到下采样图像,并对所述下采样图像进行n分块得到分块后的图像块。
8.根据权利要求7所述的装置,所述图像分块单元还包括:对所述分块后的图像块进行上采样以获取第一分块图像组。
9.根据权利要求8所述的装置,还包括目标框去重单元,用于根据所述重建后的图像组检测到的目标框进行去重。
10.一种机器人,所述机器人包括:一处理模块,一底盘,一存储模块,一激光雷达,一摄像头,所述存储模块存储有指令,在所述指令被执行时,用于实现如权利要求1-5中任一项所述的佩戴安全帽检测方法。
技术总结本发明提供了一种佩戴安全帽检测方法、装置及机器人,所述方法包括:S1,获取机器人采集的图像;S2,将所述图像进行N分块得到分块后的图像块,其中N为大于2的正整数;S3,将所述图像块输入改进后的VDSR超分辨率网络进行重建以获取重建后的图像组,其中使用主干网络的卷积核大小全部是3*3且采样间隔stride全部是1的YOLOV5主干网替换掉VDSR中学习高分辨率图像和低分辨率图像之间高频残差的卷积网络以构成改进后的VDSR超分辨率网络;S4,将所述重建后的图像组输入二分类YOLOV5网络进行佩戴安全帽检测以佩戴安全帽的情况。本发明对图像进行分块和进行超分辨重建,既保证了精度又保证了速度。
技术研发人员:黄宁波,柏林,刘彪,舒海燕,袁添厦,沈创芸,祝涛剑,王恒华,方映峰
受保护的技术使用者:广州高新兴机器人有限公司
技术研发日:技术公布日:2024/1/13