基于注意力机制的第一视角认知编码地图构建与定位方法
本发明属于图像重建,涉及编码地图的构建与定位,具体涉及基于基于注意力机制的第一视角认知编码地图构建与定位方法。
背景技术:
1、定位与建图是实现智能体的基本功能,智能体或无人机依靠搭载的传感器感知环境并估计系统状态。如自动驾驶车辆、送货无人机或家庭服务机器人,通过感知周围环境并自主做出决定;各种移动和可穿戴设备,例如智能手机、智能穿戴或物联网设备,为用户提供各种基于位置的服务,从公共区域行人导航到运动与活动监控,再到安保系统,都离不开定位与建图功能。其中,建图的主要目的是构建一个描述周围环境的模型,生成的图可以为使用者提供能够理解的地图参考或为机器人任务提供环境信息,如导航规划等。定位是指通过在构建的地图中比对感知数据来估计状态。
2、传统的定位与建图方法依赖时序图像的数据关联结果,结合多视图几何模型约束,构建三维地图,并利用构建的地图估计图像数据的位置与姿态。例如同时定位与建图方法(slam),首先对周围环境进行稀疏特征提取,然后进行三维重建,获得三维地图,在移动时不断从传感器中获得当前位置的各种信息,在已经构建的三维地图中进行定位。然而,定位与建图方法的地图仅在不同图像中关联显著相似的特征像素,因而缺乏对图像认知信息的利用,不能高效地利用完整的视觉图像信息,导致信息利用率低。同时,基于相似度的数据关联方法易受到环境变化的影响,例如有移动物体的动态场景、随时间改变的跨时段场景等,缺乏场景认知能力的定位与建图方法仍存在鲁棒性问题。
技术实现思路
1、针对现有技术的不足,本发明提出了基于注意力机制的第一视角认知编码地图构建与定位方法,充分挖掘第一视角的视觉信息,基于注意力融合多视角认知编码信息,构建认知地图,基于该地图对多视角视觉信息的认知理解,实现对图像位姿信息进行准确估计。
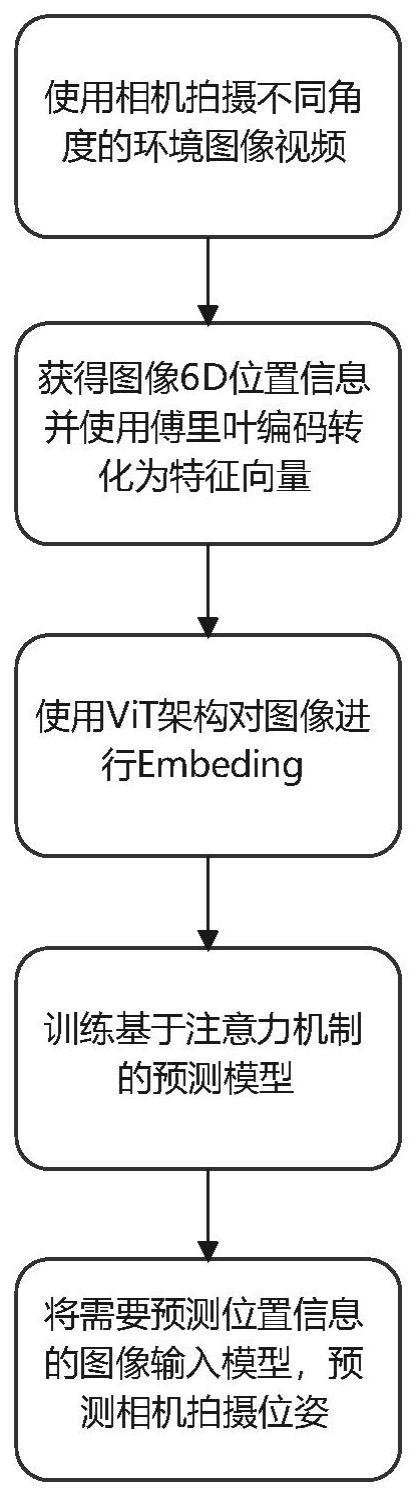
2、基于注意力机制的第一视角认知编码地图构建与定位方法,具体包括以下步骤:
3、步骤1、使用相机获取多角度的连续图像,并记录相机的内、外参数。
4、作为优选,使用相机在水平和俯仰的不同角度下进行移动拍摄,获取连续的多角度视频,分解成多角度的连续图像。
5、步骤2、分别建立现实世界的三维直角坐标系[x,y,z]与相机视角的三维直角坐标系[xc,yc,zc],根据相机的内、外参数将相机视角转化到现实世界,[xc,yc,zc,1]=cex[x,y,z,1],cex表示相机的外参矩阵,包含旋转信息与平移信息。通过傅里叶编码对转换后图像的位置信息(x,y,z)进行编码,再通过球谐函数对姿态变量(θ,φ,β)进行编码,得到位置特征。
6、步骤3、使用vit架构对步骤1获得的多角度图像进行编码,将其转化为矩阵形式,具体是将每张原图像划分为多张大小相同的子图像,排成一个输入序列输入线性投射层,得到每张子图像对应的特征向量,根据子图像在原图像中的位置加入位置编码后,再依次通过ln层、多头注意力层和ln层,完成从低维稠密特征向量到高维稀疏特征向量的转换,得到图像特征。
7、步骤4、步骤1获取的连续图像的特征按照拍摄时间顺序输入模型,依次经过注意力机制和残差计算,得到预测的图像特征,与输入图像的真实特征进行对比,计算损失函数值l,通过最小化损失函数对网络参数进行优化。
8、所述注意力机制将输入的第n张图像的位置特征x作为注意力机制的中的q矩阵,将当前输入图像之前的n-1张图像的位置特征作为k矩阵,k=k1、k2、…kn-1,将已经输入的n-1张图像的图像特征作为v矩阵,v=v1、v2、…vn-1。然后根据公式整合来自多角度的第一视角图像信息,其中s(ki,q)表示通过点积模型计算得到的q与ki的相似度。
9、所述残差计算为layernorm(x+attention(x)),其中layernorm()为rnn结构,通过将每一层神经元的输入都转成均值方差,加快收敛。
10、步骤5、假设待预测图像的位置信息为x1,通过步骤1~3提取位置特征和图像特征后,输入步骤4训练好的模型,通过对假设信息x1进行修正,输出对应的预测位置信息。
11、本发明具有以下有益效果:
12、1、本方法仿照大脑通过位置细胞群建立认知地图的过程,模拟人脑对环境图像的利用,使用注意力对图像进行编码与重建来预测图像的方位信息,减少了三维地图的重建过程,加快了计算速度,减少了计算量,并且具有很强的鲁棒性。
13、2、通过vit架构计算获得图像的特征向量,可以高效地利用完整的视觉图像信息,提高信息利用率,同时可以获得图像底层的特征信息,解决因存在移动物体的动态场景、随时间改变的跨时段场景所导致的缺乏场景认知能力的问题。
技术特征:
1.基于注意力机制的第一视角认知编码地图构建与定位方法,其特征在于:具体包括以下步骤:
2.如权利要求1所述基于注意力机制的第一视角认知编码地图构建与定位方法,其特征在于:使用相机在水平和俯仰的不同角度下进行移动拍摄,获取连续的多角度视频,分解成多角度的连续图像。
3.如权利要求1所述基于注意力机制的第一视角认知编码地图构建与定位方法,其特征在于:[xc,yc,zc,1]=cex[x,y,z,1],其中,[xc,yc,zc]表示相机视角下的图像位置信息,[x,y,z]表示现实世界中对应的坐标,cex表示相机的外参矩阵,包含旋转信息与平移信息。
4.如权利要求1所述基于注意力机制的第一视角认知编码地图构建与定位方法,其特征在于:使用vit架构对图像信息进行编码的具体过程是:将每张原图像划分为多张大小相同的子图像,排成一个输入序列输入线性投射层,得到每张子图像对应的特征向量,根据子图像在原图像中的位置加入位置编码后,再依次通过ln层、多头注意力层和ln层,完成从低维稠密特征向量到高维稀疏特征向量的转换,得到图像特征。
5.如权利要求1所述基于注意力机制的第一视角认知编码地图构建与定位方法,其特征在于:定义损失函数为:
技术总结
本发明公开了基于注意力机制的第一视角认知编码地图构建与定位方法。该方法首先对待建图的环境信息进行拍摄,根据图像的位置与姿态,对位置信息进行编码。再通过ViT架构对图像信息进行编码,获得图像特征。将连续图像的位置特征与图像特征输入注意力机制,计算每张图像的注意力得分,模拟人脑根据位置信息重建的图像信息。然后将注意力机制输出的图像信息进行残差连接,与真实图像进行差异比较计算损失,更新网络模型参数。最后将待识别图像输入训练后的网络模型,通过反向修正输入图像的假设位置信息,输出预测的图像位置,完成定位。
技术研发人员:戴玮辰,高健,孔万增
受保护的技术使用者:杭州电子科技大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!