一种基于深度学习的OCR技术神经网络模型平台的制作方法
本发明涉及图像识别,特别涉及一种基于深度学习的ocr技术神经网络模型平台。
背景技术:
1、基于光学字符识别(以下简称ocr)的针对文字区域检测定位识别技术是指通过计算机等设备,利用ocr技术将纸质材料中的有效信息自动提取和识别出来,并进行相应处理,它是实现无纸化的计算机自动处理的关键技术之一。
2、在中国专利cn109376658b中公开的一种基于深度学习的ocr方法,该基于深度学习的ocr方法,应用了卷积神经网络(cnn)和递归神经网络(rnn)的技术,可以实现影像的文字内容的智能提取,为各行业人员提供了快速检索以及快速获取信息的服务,提升了工作效率。
3、但是,该基于深度学习的ocr方法,通过深度学习的ocr技术神经网络识别出图像上的多个候选文本,使得文字识别为一体的,如果出现不一致,需要对文字重新识别,影响处理速度。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了一种基于深度学习的ocr技术神经网络模型平台,以解决背景技术中所提到的问题,克服现有技术中存在的不足。
3、(二)解决的技术问题
4、为了实现上述目的,本发明提供如下技术方案:
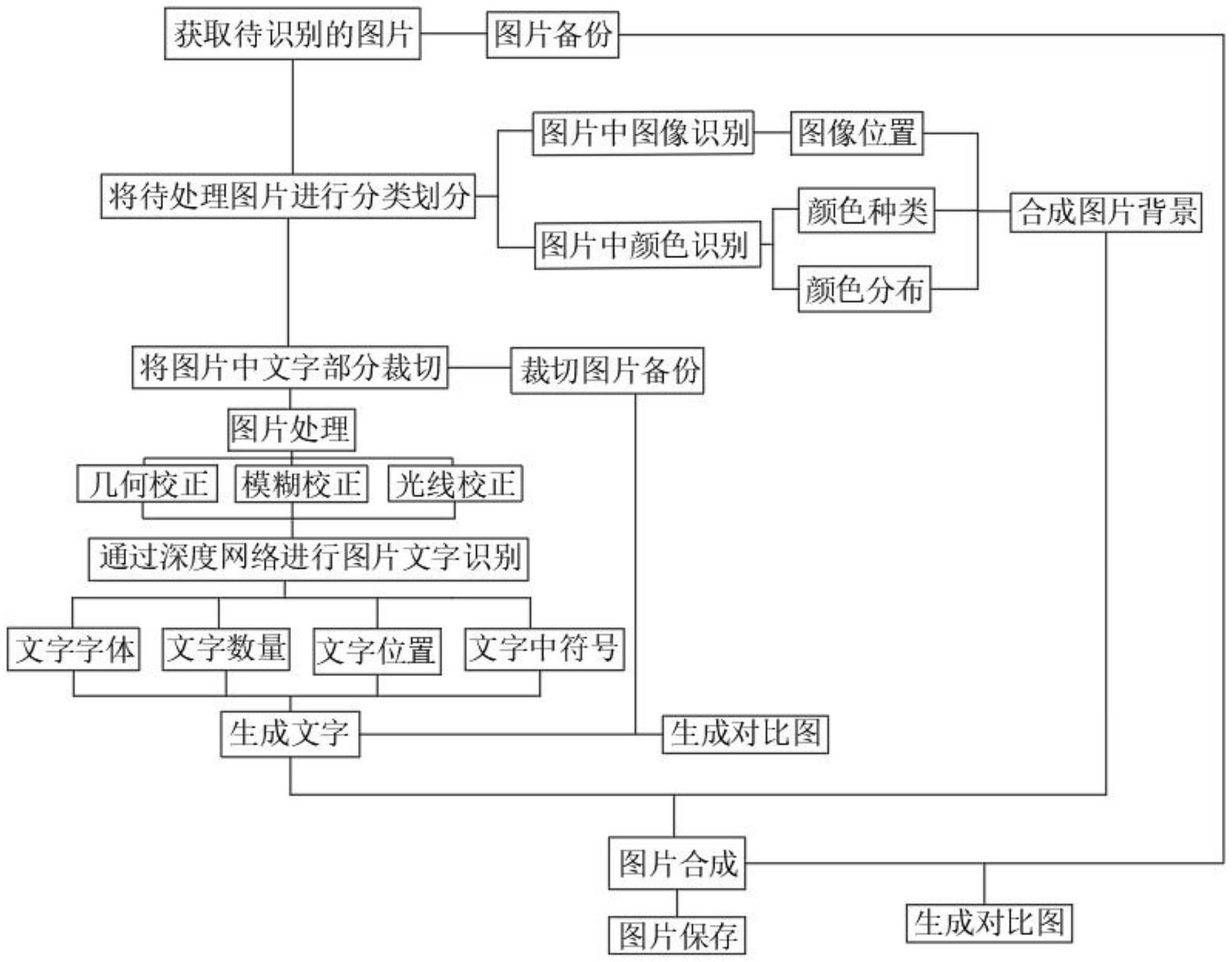
5、本发明要解决的另一技术问题是提供一种基于深度学习的ocr技术神经网络模型平台,包括图片获取模块、图片处理模块、图片转换模块、图片检验模块和图片保存模块,所述图片获取模块与图片处理模块电性连接,所述图片处理模块与图片转换模块电性连接,所述图片检验模块与图片转换模块电性连接,所述图片保存模块与图片获取模块、图片处理模块、图片转换模块和图片检验模块电性连接。
6、由上述任一方案优选的是,包括以下步骤:
7、s1.图片获取模块,获取待识别的图片,具体为:
8、s1.1.通过摄像机对待识别的图片进行拍照;
9、s1.2.在拍的照片中选择较为清晰和完整的图片,并进行备份。
10、由上述任一方案优选的是,包括以下步骤:
11、s2.图片处理模块,对获取的待处理的图片进行分类划分,便于后续进行图片合成,具体为:
12、s2.1.对图片中的图像特征进行识别,并记录图像在图片上的位置信息;
13、s2.1.对图片中的颜色进行识别,并记录图片上颜色的种类,和不同种类颜色的分布;
14、s2.2.对图片中的文字部分进行裁切,使裁切后的图片仅保留有文字,并对裁切后的图片进行备份;
15、s2.3.对裁切后的图片进行几何校正、模糊校正和光线校正处理,便于后续识别。
16、由上述任一方案优选的是,包括以下步骤:
17、s3.图片转换模块,对裁切后的文字图片进行识别,将图片中的文字提取出来,具体为;
18、s3.1.通过卷积神经网络cnn、循环神经网络rnn、长短期记忆网络lstm等技术将图片中的文字识别,将识别出的文字转化为计算机可读的文本;
19、s3.2.通过数据文库识别出图片中文字的字体、文字的数量、文字的分布位置和文字中的数字符号;
20、s3.3.根据识别出的信息生成与图片信息相对应的文字信息,使得生成的文字与裁切图片中的字体、排列分布和数字符号均一致;
21、s3.4.根据图片处理模块中的图片图像识别和图像颜色识别结果,生成不带文字的背景图片,使得生成的图片中颜色与图像与获取的图片一致;
22、s3.5.将生成的文字信息与生成的不带文字的背景图片进行合成,生成与获取图片信息一致的图片。
23、由上述任一方案优选的是,包括以下步骤:
24、s4.图片保存模块,将图片获取模块、图片处理模块、图片转换模块和图片检验模块中生成的图片进行保存备份,具体为:
25、s4.1.根据保存的裁切后的文字图片与合成的文字信息生成对比图,并进行保存;
26、s4.2.根据保存后合成的与获取图片信息一致的文字信息和背景图片,与图片获取模块中获取的图片生成对比图,并进行保存,其中对比图中两张图片为左右分布。
27、由上述任一方案优选的是,包括以下步骤:
28、s5.图片检验模块,对生成的图片进行检验,提高识别字段的准确率,具体为:
29、s5.1.将图片转换模块中识别的带文字信息的图片虚拟化处理,使图片中仅有文字线条和数字符号线条较为明显;
30、s5.2.将虚拟化处理后的图片移动至裁切的文字图片上,使两张图片上的文字相重叠,根据线条的重叠度对识别的文字进行检验,如果重叠后的线条一致,则为识别正确,如果线条有交错的,则为识别错误;
31、s5.3.根据识别错误的文字位置,对比图片转换模块中识别出的文字分布位置信息,对图片中相对应的文字进行单独重新识别即可,不需要重复识别。
32、与现有技术相比,本发明提供了一种基于深度学习的ocr技术神经网络模型平台,具备以下有益效果:
33、1、该基于深度学习的ocr技术神经网络模型平台,通过设置图片转换模块,图片处理模块与图片转换模块电性连接,在进行图片识别之前,通过图片转换模块对获取的图片中的图像特征和图片颜色进行识别,生成不带文字的背景图片,对获取的图片中的文字部分进行裁切,生成与裁切图片中的字体、排列分布和数字符号均一致的文字信息图片,并对文字的字体、文字的数量、文字的分布位置和文字中的数字符号进行识别,使得在检验时,能够根据生成文字中,其中不一致的文字图片的位置信息查找出相对应的原有文字的位置信息,对图片中相对应的文字进行单独重新识别即可,不需要重复识别,提高识别处理速度。
34、2、该基于深度学习的ocr技术神经网络模型平台,通过设置图片检验模块,在生成相对应的裁切后的文字图片与合成的文字信息生成对比图之后,将图片转换模块中识别的带文字信息的图片虚拟化处理,使图片中仅有文字线条和数字符号线条较为明显,将虚拟化处理后的图片移动至裁切的文字图片上,使两张图片上的文字相重叠,根据线条的重叠度对识别的文字进行检验,如果重叠后的线条一致,则为识别正确,如果线条有交错的,则为识别错误,进而便于对识别错误处进行重新识别,提高识别字段的准确率。
35、本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:
1.一种基于深度学习的ocr技术神经网络模型平台,其特征在于,包括图片获取模块、图片处理模块、图片转换模块、图片检验模块和图片保存模块,所述图片获取模块与图片处理模块电性连接,所述图片处理模块与图片转换模块电性连接,所述图片检验模块与图片转换模块电性连接,所述图片保存模块与图片获取模块、图片处理模块、图片转换模块和图片检验模块电性连接。
2.如权利要求1所述的一种基于深度学习的ocr技术神经网络模型平台,包括以下步骤:
3.如权利要求2所述的一种基于深度学习的ocr技术神经网络模型平台,包括以下步骤:
4.如权利要求3所述的一种基于深度学习的ocr技术神经网络模型平台,包括以下步骤:
5.如权利要求4所述的一种基于深度学习的ocr技术神经网络模型平台,包括以下步骤:
6.如权利要求5所述的一种基于深度学习的ocr技术神经网络模型平台,包括以下步骤:
技术总结
本发明涉及图像识别技术领域,具体为一种基于深度学习的OCR技术神经网络模型平台,包括图片获取模块、图片处理模块、图片转换模块、图片检验模块和图片保存模块。优点在于:通过图片转换模块对获取的图片中的图像特征和图片颜色进行识别,生成不带文字的背景图片,对获取的图片中的文字部分进行裁切,生成与裁切图片中的字体、排列分布和数字符号均一致的文字信息图片,并对文字的字体、文字的数量、文字的分布位置和文字中的数字符号进行识别,使得在检验时,能够根据生成文字中,其中不一致的文字图片的位置信息查找出相对应的原有文字的位置信息,对图片中相对应的文字进行单独重新识别即可,不需要重复识别,提高识别处理速度。
技术研发人员:洪创波
受保护的技术使用者:广东潮庭集团有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!