基于聚类和动态划分时间序列的电站风机状态预测方法
本发明属于电站风机状态预测,具体为基于聚类和动态划分时间序列的电站风机状态预测方法。
背景技术:
1、风机作为燃煤电站重要的辅机设备之一,在多个过程中发挥作用,包括烟气循环、设备密封、脱硝脱硫等。为保障电站的安全运行并提高经济效益,对风机精确的状态预测具有重要意义。由于风机处于频繁变工况的状态下,部分监测参数可能存在大幅波动,从而影响预测精度。因此针对风机参数这类具有时间特性的采样数据,本时刻的采样值与前段时间的采样值有关,即数据是连续变化的。在利用模型进行预测时,需要充分挖掘其输入序列中的时间信息。
2、长短期记忆网络(long short-term memory,lstm网络),是一种能够接受多个时刻输入的神经网络,它能够输入时刻t到时刻t-n的数据,在计算过程中基于时刻t-n输入数据得到的信息会被lstm网络隐含层神经元有选择地往下传递给时刻t-n+1的计算过程。利用lstm网络能够充分挖掘输入时间序列中的信息。
3、为提高模型的预测精度,需要对输入数据进行分类,因为同类型的数据其特征比较一致,有利于建模时获取规律。k-means聚类算法是一种迭代求解的聚类分析算法,它基于给定的聚类数目k,利用某个距离函数将样本数据划分到k个类别中,重复操作直到满足某个终止条件。
4、为提高对风机这类工业数据的预测精度,希望能够采用先进行分类再预测的方式进行预测,但常规的分类方法,如k-means聚类算法或cnn等,都是基于数据的幅值大小进行分类,而这样分类后得到的新数据组很可能会破坏原有数据的时间连续性,因此这样分类后是无法使用lstm网络这类要求输入时间连续的预测网络。因此亟需一种基于聚类和动态划分时间序列的电站风机状态预测方法,既可以通过分类提高子模型的预测精度,又可以利用lstm这类网络挖掘时间特性,并通过加权得到更优值,对提高对风机的预测精度具有重要意义。
技术实现思路
1、本发明的目的是提供一种基于聚类和动态划分时间序列的电站风机状态预测方法,其特征在于,包括以下步骤:
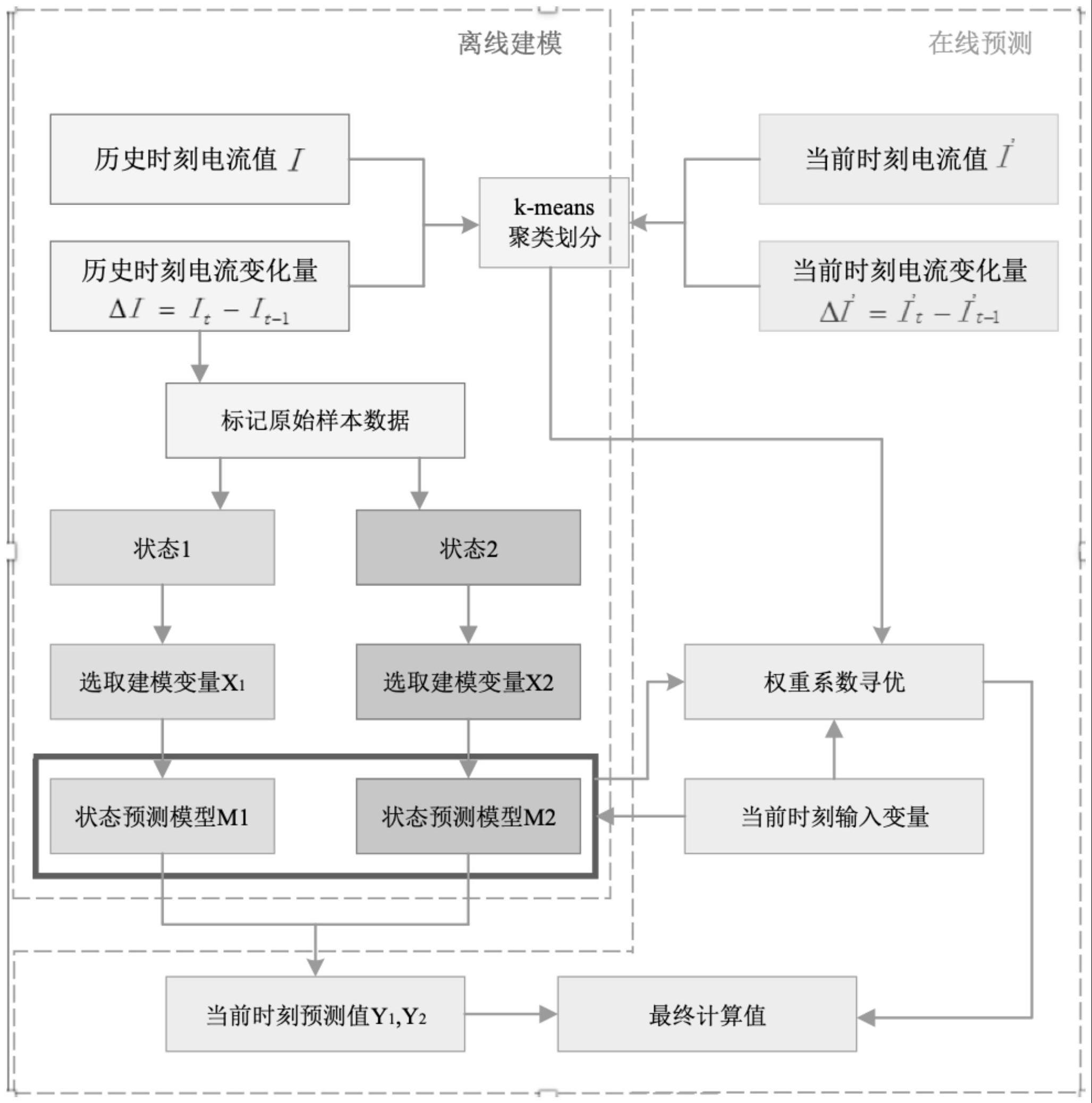
2、s1:采集电站风机跨度时间一周的运行数据,采样周期为1min,对采集的数据集进行预处理,形成由单个采样点数据构成的时间序列;
3、s2:选取电站风机电流变化量δi=it-it-1和电站风机电流i共同作为电站风机状态划分的基准参数;
4、s3:利用k-means聚类技术进行电站风机状态划分,设置状态分类数k=2;
5、s4:实现分类建模,根据s3的分类结果对原始数据进行标记,每类数据将对应一个状态预测模型,从每类样本中选取数据,通过动态划分时间序列构造各状态预测模型的训练集和测试集,将电站风机电流作为预测的目标变量,为每个状态预测模型选取输入变量,利用相关分析方法或主成分分析方法,进行相应状态预测模型的训练及测试;
6、s5,在线预测时将数据同时输入各类状态预测模型,根据输入序列中的数据分类情况设置权重系数初始值,以最终计算所得值与实际观测值的偏差为指标,基于搜索算法对权重系数寻优,实现精确的电站风机状态预测。
7、所述s4中动态划分时间序列,包括如下步骤:
8、s41:将所述s1中时间序列,动态划分为多个长度为n的时间组序列;
9、s42:计算每个时间组序列的标签,所述标签的格式为:“a/n,b/n”;
10、其中:a为时间组中包含第一分类采样点的个数;b为时间组中包含第二分类采样点的个数;
11、s43:根据s42中时间组序列的标签,选取组内占比较大的采样点分类,作为该时间组序列的分类,并将该时间组序列加入各状态预测模型的训练集和测试集。
12、所述s41中动态划分为多个长度为n的时间组序列的步骤为:
13、选取时间序列中第1个到第n个采样点数据为第一个时间组;
14、选取时间序列中第2个到第n+1个采样点数据为第二个时间组;
15、以此类推,直到选取时间序列中最后一个采样点数据为止。
16、所述s4中每个状态预测模型选取的输入变量为:电站风机电流、电机功率、前轴承温度、电机前轴承温度、轴承水平振动、轴承垂直振动作。
17、所述s4中状态预测模型为lstm模型。
18、所述s5中基于搜索算法对权重系数寻优的步骤为:
19、s51:根据s42中得到的每个时间组序列的标签计算初始权重wi,即:w1=a/n,w2=b/n;
20、s52:为初始权重设置偏置bi,计算实际权重xi,即:x1=w1+b1,x2=w2+b2;
21、s53:确定需要搜索的参数为:b1,b2;
22、s54:将训练集的数据同时输入各类状态预测模型,得到预测输出值o1,o2;
23、s55:计算加权输出值为o=x1o1+x2o2;
24、s56:计算加权输出值与真实值的均方误差e;
25、s57:将e最小做为目标函数,b1,b2作为搜索变量,搜索范围设置为(0,0.1),利用遗传算法进行寻优,求解出b1,b2,完成权重系数寻优。
26、本发明的有益效果在于:
27、(1)提高风机状态的预测精度。现有研究中的风机状态划分方法只基于数据进行静态划分,没有充分利用输入时间序列中的信息。本方法基于k-means聚类算法对引风机状态进行划分后,仍沿时间序列构造状态预测模型的输入集及标签集进行训练,是一种动态划分方法。在线预测时根据此方法对输入序列进行动态划分和分类预测,适用于电站风机频繁变工况的特性,能有效提高预测精度。
28、(2)提高整体预测速度。使用搜索算法对各预测模型输出值的权重系数进行寻优,由于搜索问题可简化为简单的单目标线性寻优,能有效提高整体预测速度。
技术特征:
1.一种基于聚类和动态划分时间序列的电站风机状态预测方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的基于聚类和动态划分时间序列的电站风机状态预测方法,其特征在于,所述s4中动态划分时间序列,包括如下步骤:
3.根据权利要求2所述的基于聚类和动态划分时间序列的电站风机状态预测方法,其特征在于,所述s41中动态划分为多个长度为n的时间组序列的步骤为:
4.根据权利要求1所述的基于聚类和动态划分时间序列的电站风机状态预测方法,其特征在于,所述s4中每个状态预测模型选取的输入变量为:电站风机电流、电机功率、前轴承温度、电机前轴承温度、轴承水平振动、轴承垂直振动作。
5.根据权利要求1所述的基于聚类和动态划分时间序列的电站风机状态预测方法,其特征在于,所述s4中状态预测模型为lstm模型。
6.根据权利要求2所述的基于聚类和动态划分时间序列的电站风机状态预测方法,其特征在于,所述s5中基于搜索算法对权重系数寻优的步骤为:
技术总结
本发明公开了属于电站风机状态预测技术领域的一种基于聚类动态划分时间序列的电站风机状态预测方法。在离线状态下利用能表征风机运行状态的监测参数数据,基于k‑means聚类算法实现风机状态分类并对原始数据进行标记,根据标记好的数据训练相关状态预测模型。在线预测时将数据序列同时输入各状态预测模型,根据输入序列中的数据分类情况设置权重系数初始值,以最终计算值与实际观测值的偏差为指标,基于搜索算法对权重系数寻优,实现精确的电站风机状态预测。
技术研发人员:吕游,魏玮,陈江,曾卫东,樊启祥
受保护的技术使用者:华北电力大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!