基于视频的虚拟人模型驱动方法、装置、设备及存储介质与流程
本申请涉及深度学习,特别是涉及到一种基于视频的虚拟人模型驱动方法、装置、设备及存储介质。
背景技术:
1、3d模型的驱动一直是计算机视觉研究的重要领域之一,从动作驱动的来源来分类,有通过文本、图片、语音、视频等多模态驱动模型运动的方法。这些模态中,视频是最直接体现模型运动的模态。通过识别视频中运动人体的各个关节点与每一帧视频中的各关节坐标,便可以数据化人体的运动过程。这些运动数据可以驱动虚拟人模型运动。由视频驱动虚拟人模型的技术,提取视频中的运动过程依赖视频的清晰度,如果视频不够清晰,或者失焦,识别出的动作序列驱动模型只会使得模型剧烈抖动。而且识别主要聚焦于身体,这导致手部的运动可能无法被准确的识别,并且一般无法直接导入面部的表情。
2、此外,大部分方法都是直接识别人体几个重要的关节点比如肘部、颈部、腰部等,这样提取出的动作序列实际上比较僵硬,而且关节点少时无法流畅地适配和驱动比较复杂的虚拟人模型。驱动的虚拟人物模型可被应用于虚拟人动画生成中,可以作为金融理财产品销售动画中的人物形象。
技术实现思路
1、本申请的主要目的为提供一种基于视频的虚拟人模型驱动方法、装置、设备及存储介质,旨在解决现有技术不能根据人体运动视频,高效且清晰流畅地驱动虚拟人模型的技术问题。
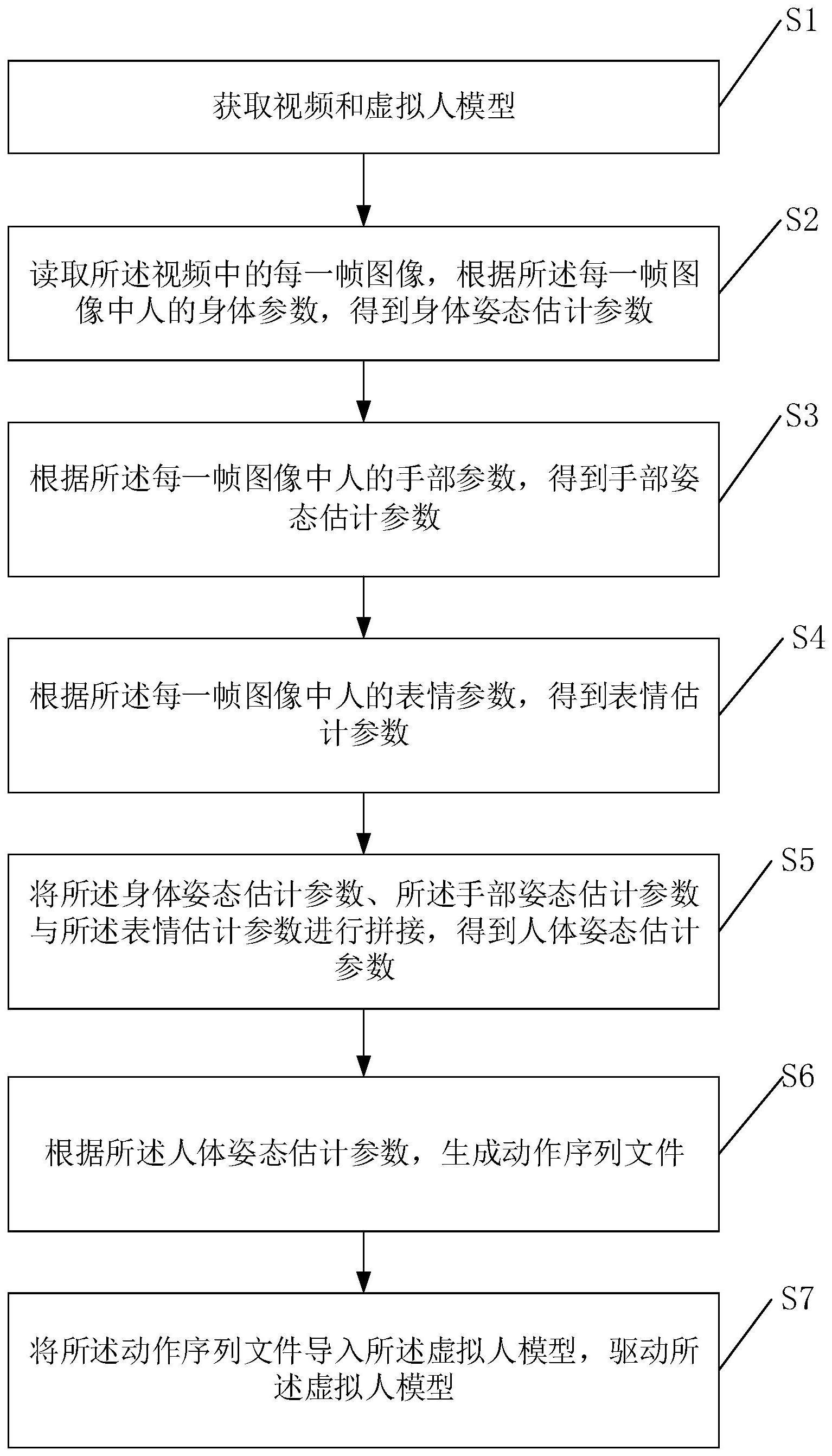
2、为了实现上述发明目的,本申请提出一种基于视频的虚拟人模型驱动方法,所述方法包括:
3、获取视频和虚拟人模型;
4、读取所述视频中的每一帧图像,根据所述每一帧图像中人的身体参数,得到身体姿态估计参数;
5、根据所述每一帧图像中人的手部参数,得到手部姿态估计参数;
6、根据所述每一帧图像中人的表情参数,得到表情估计参数;
7、将所述身体姿态估计参数、所述手部姿态估计参数与所述表情估计参数进行拼接,得到人体姿态估计参数;
8、根据所述人体姿态估计参数,生成动作序列文件;
9、将所述动作序列文件导入所述虚拟人模型,驱动所述虚拟人模型。
10、进一步地,所述读取所述视频中的每一帧图像之后,包括:
11、识别所述每一帧图像中人的手部区域、身体区域和脸部表情区域,将所手部区域、所述身体区域和所述脸部表情区域分割,得到人的身体参数、手部参数和表情参数。
12、进一步地,所述根据所述每一帧图像中人的身体参数,得到身体姿态估计参数,包括:
13、将所述人的身体参数输入smpl-x模型,得到人体姿态函数,smpl-x模型的公式为:
14、mw=w(φw,θw,βw)
15、其中,φw为人体的旋转参数,θw为人体形状参数,βw为表情相关参数,mw为人体姿态函数;
16、将所述人体姿态函数进行回归计算,得到身体姿态估计参数。
17、进一步地,所述根据所述每一帧图像中人的手部参数,得到手部姿态估计参数,包括:
18、将所述手部参数输入hmr模型,通过hmr模型中的编码器处理,得到手部特征;
19、通过hmr模型中的解码器处理,得到手部姿态参数;
20、根据所述手部特征和所述手部姿态参数,得到手部姿态估计参数。
21、进一步地,所述根据所述每一帧图像中人的表情参数,得到表情估计参数,包括:
22、将所述表情参数输入deca库,根据下述公式计算表情估计参数:
23、m(β,θ,ψ)=w(tp(β,θ,ψ),j(β),θ,w)
24、其中,β为人面部顶点参数,θ为面部姿态参数,ψ为表情参数,tp函数用于对面部参数进行三维空间的旋转变换,而j函数用于提取人脸中的所有标识点,w为对所有参数进行平滑。
25、进一步地,所述根据所述人体姿态估计参数,生成动作序列文件,包括:
26、根据所述人体姿态估计参数确定骨骼节点;
27、根据所述人体姿态估计参数和所述骨骼节点,确定所述骨骼节点的姿态参数;
28、对所述骨骼节点和所述骨骼节点的姿态参数进行解算,得到动作序列文件。
29、进一步地,所述将所述动作序列文件导入所述虚拟人模型,驱动所述虚拟人模型,包括:
30、根据所述动作序列文件,对虚拟人模型进行骨骼的重映射,驱动所述虚拟人模型。
31、本申请提供一种基于视频的虚拟人模型驱动装置,所述装置包括:
32、获取模块,用于获取视频和虚拟人模型;
33、身体姿态估计参数确定模块,用于读取所述视频中的每一帧图像,根据所述每一帧图像中人的身体参数,得到身体姿态估计参数;
34、手部姿态估计参数确定模块,用于根据所述每一帧图像中人的手部参数,得到手部姿态估计参数;
35、表情估计参数确定模块,用于根据所述每一帧图像中人的表情参数,得到表情估计参数;
36、人体姿态估计参数确定模块,用于将所述身体姿态估计参数、所述手部姿态估计参数与所述表情估计参数进行拼接,得到人体姿态估计参数;
37、动作序列文件生成模块,用于根据所述人体姿态估计参数,生成动作序列文件;
38、虚拟人模型驱动模块,用于将所述动作序列文件导入所述虚拟人模型,驱动所述虚拟人模型。
39、本申请还提供一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现上述任一项所述方法的步骤。
40、本申请还提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现上述任一项所述方法的步骤。
41、本申请提供的一种基于视频的虚拟人模型驱动方法,通过该方法,实现了从视频到虚拟人模型驱动的自动化过程,将人体从手部、面部和身体分别识别,解决了局部识别模糊的问题。而本方法将手部与脸部都以拼接的方式与身体合成,所以能够使输出的动作序列文件中也包含该脸部表情,更加精细地获取到视频中的人体姿态。此外,将姿态转换为动作序列文件后更加方便后续的使用,可以将同一套动作导入不同的虚拟人模型,实现资源的复用,对于商业化来说更加地方便。驱动的虚拟人物模型可被应用于虚拟人动画生成中,可以作为金融理财产品销售动画中的人物形象。
技术特征:
1.一种基于视频的虚拟人模型驱动方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于视频的虚拟人模型驱动方法,其特征在于,所述读取所述视频中的每一帧图像之后,包括:
3.根据权利要求2所述的基于视频的虚拟人模型驱动方法,其特征在于,所述根据所述每一帧图像中人的身体参数,得到身体姿态估计参数,包括:
4.根据权利要求2所述的基于视频的虚拟人模型驱动方法,其特征在于,所述根据所述每一帧图像中人的手部参数,得到手部姿态估计参数,包括:
5.根据权利要求2所述的基于视频的虚拟人模型驱动方法,其特征在于,所述根据所述每一帧图像中人的表情参数,得到表情估计参数,包括:
6.根据权利要求1所述的基于视频的虚拟人模型驱动方法,其特征在于,所述根据所述人体姿态估计参数,生成动作序列文件,包括:
7.根据权利要求1所述的基于视频的虚拟人模型驱动方法,其特征在于,所述将所述动作序列文件导入所述虚拟人模型,驱动所述虚拟人模型,包括:
8.一种基于视频的虚拟人模型驱动装置,其特征在于,所述装置包括:
9.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1至7中任一项所述方法的步骤。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至7中任一项所述方法的步骤。
技术总结
本申请涉及深度学习技术领域,特别是涉及到一种基于视频的虚拟人模型驱动方法、装置、设备及存储介质,通过所述方法,实现了从视频到虚拟人模型驱动的自动化过程,将人体从手部、面部和身体分别识别,解决了局部识别模糊的问题。而本方法将手部与脸部都以拼接的方式与身体合成,所以能够使输出的动作序列文件中也包含该脸部表情,更加精细地获取到视频中的人体姿态。此外,将姿态转换为动作序列文件后更加方便后续的使用,可以将同一套动作导入不同的虚拟人模型,实现资源的复用,对于商业化来说更加地方便。驱动的虚拟人物模型可被应用于虚拟人动画生成中,可以作为金融理财产品销售动画中的人物形象。
技术研发人员:郑喜民,黄嘉铉,舒畅,陈又新
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!