三维语义场景补全方法、设备和介质与流程
本公开一般涉及计算机视觉,具体涉及图像处理,尤其涉及一种三维语义场景补全方法、设备和介质。
背景技术:
1、目前,随着计算机视觉技术的快速发展,与计算机视觉技术有关的应用(例如自动驾驶、机器人导航和增强现实等技术)也在不断进步。
2、在现实世界应用传感器的过程中,会存在各种局限性(视场受限、测量噪声或结果稀疏),从而导致传感器的感知测量内容受限,因此,可以利用计算机视觉技术中的三维(3-dimensional)语义场景补全(semantic scene completion,ssc)技术,对需要预测的场景进行几何和语义分割,进而可以不完整的观测中推断出密集的三维场景。在相关技术中,通常会在三维语义场景补全系统中利用激光雷达,显式地结合3d几何输入,从而完成3d语义场景补全;或者可以通过单目色彩rgb(red、green、blue)图像,对三维语义场景补全系统进行三维先验知识的大量学习训练,从而完成三维语义场景补全。
3、然而,在上述方法中,若在三维语义场景补全系统中利用激光雷达进行三维语义场景补全,存在成本较高、便携性较差的问题,而由于单目rgb图像本身模糊性较强。因此,利用单目rgb图像进行学习训练进而获得的三维语义场景补全系统,存在建立模型效果精确度较差,继而无法高效快速、高保真地完成三维语义场景补全。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种三维语义场景补全方法、设备和介质,采用本申请的方法,可以高效快速、高保真地完成三维语义场景补全。
2、第一方面,提供一种三维语义场景补全方法,该方法包括:
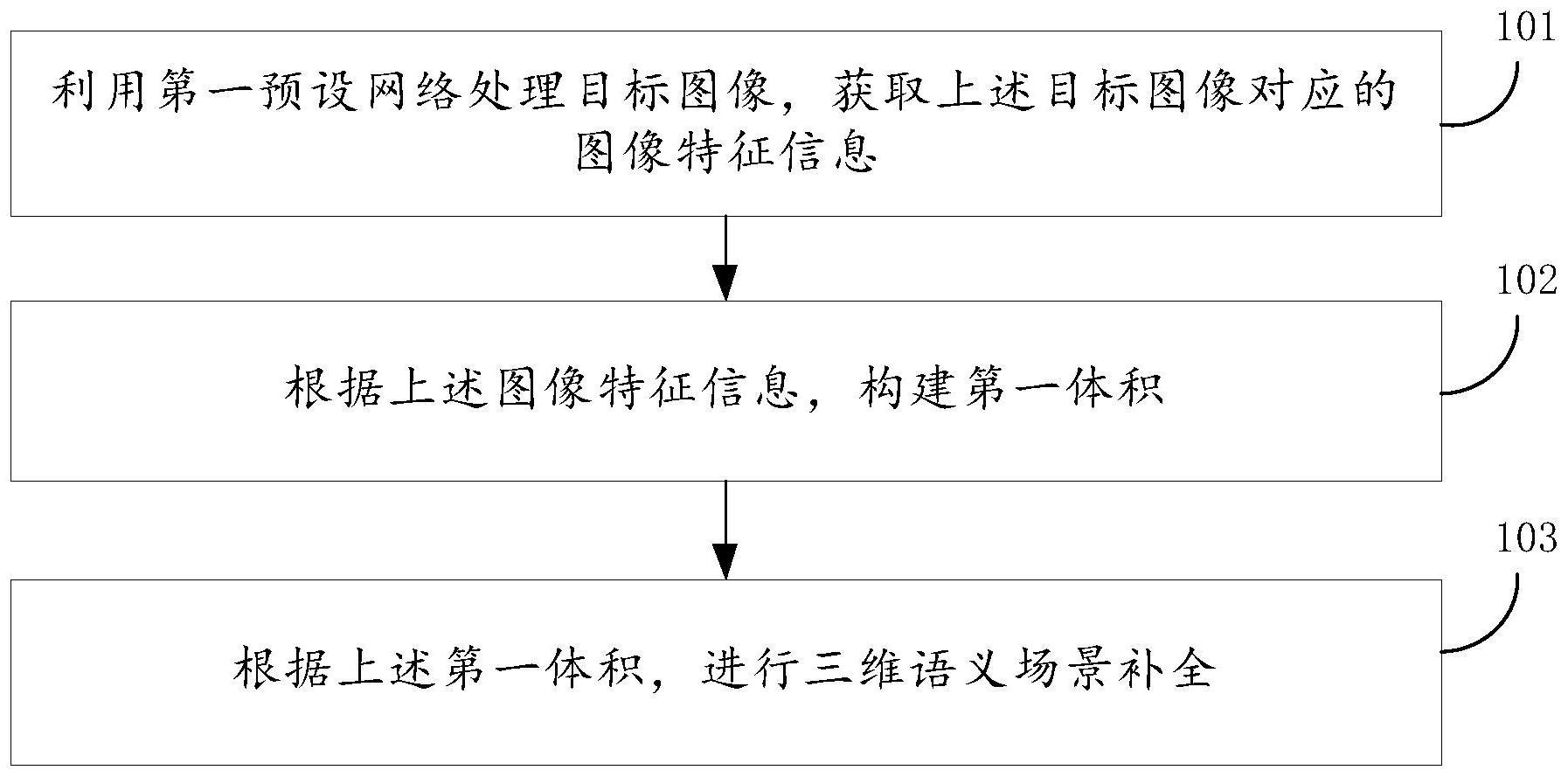
3、利用第一预设网络处理目标图像,获取所述目标图像对应的图像特征信息,所述目标图像包括双目图像;
4、根据所述图像特征信息,构建第一体积,所述第一体积包括第一双目立体stereo体积;
5、根据所述第一体积,进行三维语义场景补全。
6、第二方面,提供了一种电子设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,处理器执行程序时,实现上述第一方面以及第一方面任意一种可能的实现方式的方法的步骤。
7、第三方面,提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时,实现上述第一方面以及第一方面任意一种可能的实现方式的方法的步骤。
8、第四方面,提供一种计算机程序产品,计算机程序产品包括指令,当指令被运行时,实现上述第一方面以及第一方面任意一种可能的实现方式的方法的步骤。
9、采用本申请的方法在进行三维语义场景补全时,可以先利用第一预设网络处理目标图像,获取目标图像对应的图像特征信息;然后根据上述图像特征信息,构建第一体积(例如,第一双目立体stereo体积);最后,根据第一体积进行三维语义场景补全。如此,通过使用目标图像构建包括第一stereo体积的第一体积,并利用该第一体积,进行三维语义场景补全,在节约成本,使得三维语义场景补全的设备便携的基础上,由于第一体积包括stereo体积,还可以提高三维语义场景补全的准确性、保真性。
技术特征:
1.一种三维语义场景补全方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述获取所述目标图像对应的图像特征信息,包括:
3.根据权利要求1所述的方法,其特征在于,在所述目标图像包括所述双目图像和鸟瞰图bev图像的情况下,所述获取所述目标图像对应的图像特征信息,包括:
4.根据权利要求3所述的方法,其特征在于,所述构建第一bev体积,包括:
5.根据权利要求3所述的方法,其特征在于,所述交互聚合所述第一stereo体积和所述第一bev体积,生成第一体积,包括:
6.根据权利要求5所述的方法,其特征在于,所述生成第一stereo体积对应的第一数据信息中,包括:
7.根据权利要求3-6任一项所述的方法,其特征在于,所述交互聚合所述第一stereo体积和所述第一bev体积,生成第一体积,包括:
8.根据权利要求7所述的方法,其特征在于,所述对所述第一bev体积和所述第一stereo体积进行串联聚合,生成第一体积,包括:
9.根据权利要求3所述的方法,其特征在于,所述构建第一bev体积,包括:
10.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时,实现如权利要求1-9任一项所述的三维语义场景补全方法。
11.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如权利要求1-9中任一所述的三维语义场景补全方法。
12.一种计算机程序产品,计算机程序产品包括指令,其特征在于,当指令被运行时实现如权利要求1-9中任一所述三维语义场景补全方法。
技术总结
本申请公开了一种三维语义场景补全方法、设备和介质。该方法包括:利用第一预设网络处理目标图像,获取上述目标图像对应的图像特征信息,上述目标图像包括双目图像;根据上述图像特征信息,构建第一体积,上述第一体积包括第一双目立体Stereo体积;根据上述第一体积,进行三维语义场景补全。采用本申请的方法,可以提高三维语义场景补全的准确性。
技术研发人员:李博涵,朱政,肖航
受保护的技术使用者:北京鉴智科技有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!