样本扩展和标签嵌入的多分辨率字典学习人脸识别方法
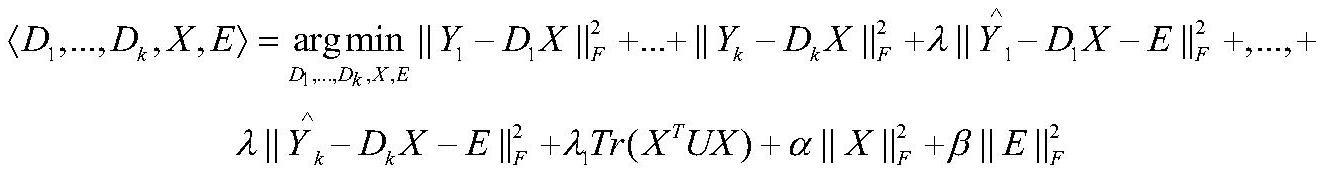
本发明属于人脸识别,具体涉及样本扩展和标签嵌入的多分辨率字典学习人脸识别方法。
背景技术:
1、人脸识别是计算机视觉和模式识别领域的一个重要研究课题,在公共安全、智能监控、金融等领域有着广泛的应用前景。目前人脸识别技术已经相对成熟,但是,在面对实际的复杂环境时,人脸识别仍然存在很多的挑战。在实际环境中的人脸识别,样本数量少是一个关键问题。扩展样本可以部分克服这个问题,因为更多的样本可以反映一个面部的不同外观。为了解决训练样本不足的问题,现有技术采用生成新的训练样本结合原始训练样本进行人脸识别的方法。但是,在生成虚拟训练样本的过程中可能会增加意外噪声和异常值,会降低识别能力。
2、在现实环境中,对于一个复杂的人脸识别系统,有许多因素会改变人脸图像的原始分辨率,如相机和物体之间的距离以及物体的移动速度,照明强度和环境遮挡、姿态、表情等,这都意味着单一分辨率特征不足以覆盖人脸图像中有效的鉴别特征。目前大多数字典学习方法都是针对单一分辨率的人脸图像,大多数现有的字典学习方法直接用于解决复杂应用场景时,无法达到理想的识别精度且泛化性能大大下降。
技术实现思路
1、本发明提供了样本扩展和标签嵌入的多分辨率字典学习人脸识别方法,已解决训练样本不足和目前大多数字典学习方法只针对单一分辨率的人脸图像的问题,本发明为原始训练样本生成虚拟样本,并将它们转化为不同的分辨率,能更好的识别多个不同分辨率下的人脸图像。同时,为虚拟样本添加噪声约束,合理的样本多样性提高学习字典的鲁棒性;然后利用原子的标签信息构造标签嵌入项,并将其嵌入到多分辨率字典学习模型上进行训练,达到准确分类的目的。
2、为实现上述目的,本发明采用的技术方案如下:
3、样本扩展和标签嵌入的多分辨率字典学习人脸识别方法,其特征在于:首先利用原始样本相邻两张人脸图像形成偏差样本,由原始训练样本与偏差样本形成虚拟样本,并将原始样本和虚拟样本转化为不同分辨率,同时为虚拟样本添加噪声约束;其次将原始训练样本的标签分配给原子,构造成原子标签信息,通过原子标签信息构造标签嵌入项;将添加噪声约束的虚拟样本在多分辨率字典学习模型上进行训练,并将原子标签信息构造的标签嵌入项嵌入到多分辨率字典学习模型,获得的表示误差,最后利用表示误差对测试样本进行分类;
4、添加噪声约束的虚拟样本在多分辨率字典学习模型上进行训练,并将原子标签信息构造的标签嵌入项嵌入到多分辨率字典学习模型,其算法目标函数为:
5、
6、其中:y1,…,yk是k个分辨率下的原始训练样本;是k个分辨率下的虚拟样本;d1,…,dk是k个分辨率下的字典;x是编码系数矩阵。
7、所述原始样本和虚拟样本通过图像金字塔方法转换为若干不同的分辨率。
8、所述虚拟样本噪声约束模型为:
9、y1=dx+o
10、
11、式中:y1是原始训练样本,d=[d1,d2,…,di,…,dk]是多分辨率字典,x=[x1,x2,…,xi,…,xn]是编码系数矩阵,o=[o1,o2,...,on]是训练样本的重构误差矩阵,是虚拟样本,e=[e1,e2,...,en]表示虚拟训练样本的噪声和异常值的矩。
12、所述原子标签信息构造标签嵌入项方式为:
13、步骤一:使用字典学习算法,通过使用第i类训练原始样本学习子字典di;
14、步骤二:学习子字典di的标签矩阵b为
15、b=[b1,...,bk]t∈rk×c;
16、步骤三:使用子字典di的标签矩阵b∈rk×c构建一个加权标签矩阵g,如下所示:
17、
18、步骤四:使用原子的轮廓矩阵和标签来构建标签嵌入项,原子的标签嵌入如下:
19、
20、其中,u=ggt∈rk×k是字典d的缩放标签矩阵。v是编码系数矩阵本发明的有益效果为:在复杂的实际环境中,获取的人脸图像有限以及人脸图像分辨率是不唯一的,导致人脸识别率降低。因此,提出一种基于样本扩展和标签嵌入的多分辨率字典学习的人脸识别方法。为原始训练样本生成虚拟样本,扩充了训练样本,为虚拟样本添加噪声约束,新添加的噪声约束使虚拟样本更加可靠,合理的样本多样性提高了学习字典的鲁棒性;并构造标签嵌入项,提高了字典的判别能力。通过实验结果都表明,本文算法框架具有较强的鲁棒性,分类精度有了提高,强于一些先进的字典学习和稀疏编码算法。
技术特征:
1.样本扩展和标签嵌入的多分辨率字典学习人脸识别方法,其特征在于:首先利用原始样本相邻两张人脸图像形成偏差样本,由原始训练样本与偏差样本形成虚拟样本,并将原始样本和虚拟样本转化为不同分辨率,同时为虚拟样本添加噪声约束;其次将原始训练样本的标签分配给原子,构造成原子标签信息,通过原子标签信息构造标签嵌入项;将添加噪声约束的虚拟样本在多分辨率字典学习模型上进行训练,并将原子标签信息构造的标签嵌入项嵌入到多分辨率字典学习模型,获得的表示误差,最后利用表示误差对测试样本进行分类;
2.根据权利要求1所述的样本扩展和标签嵌入的多分辨率字典学习人脸识别方法,其特征在于:所述原始样本和虚拟样本通过图像金字塔方法转换为若干不同的分辨率。
3.根据权利要求1所述的样本扩展和标签嵌入的多分辨率字典学习人脸识别方法,其特征在于:所述虚拟样本噪声约束模型为:
4.根据权利要求1所述的样本扩展和标签嵌入的多分辨率字典学习人脸识别方法,其特征在于:所述原子标签信息构造标签嵌入项方式为:
5.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至4任一项所述的样本扩展和标签嵌入的多分辨率字典学习人脸识别方法。
6.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如权利要求1至4任一项所述的样本扩展和标签嵌入的多分辨率字典学习人脸识别方法。
技术总结
本发明属于人脸识别技术领域,具体涉及样本扩展和标签嵌入的多分辨率字典学习人脸识别方法。解决了训练样本不足和目前大多数字典学习方法只针对单一分辨率的人脸图像的问题。本发明为原始训练样本生成虚拟样本,并将它们转化为不同的分辨率,能更好的识别多个不同分辨率下的人脸图像。同时,为虚拟样本添加噪声约束,合理的样本多样性提高学习字典的鲁棒性;然后利用原子的标签信息构造标签嵌入项,并将其嵌入到多分辨率字典学习模型上进行训练,达到准确分类的目的。
技术研发人员:严春满,崔谦
受保护的技术使用者:西北师范大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!